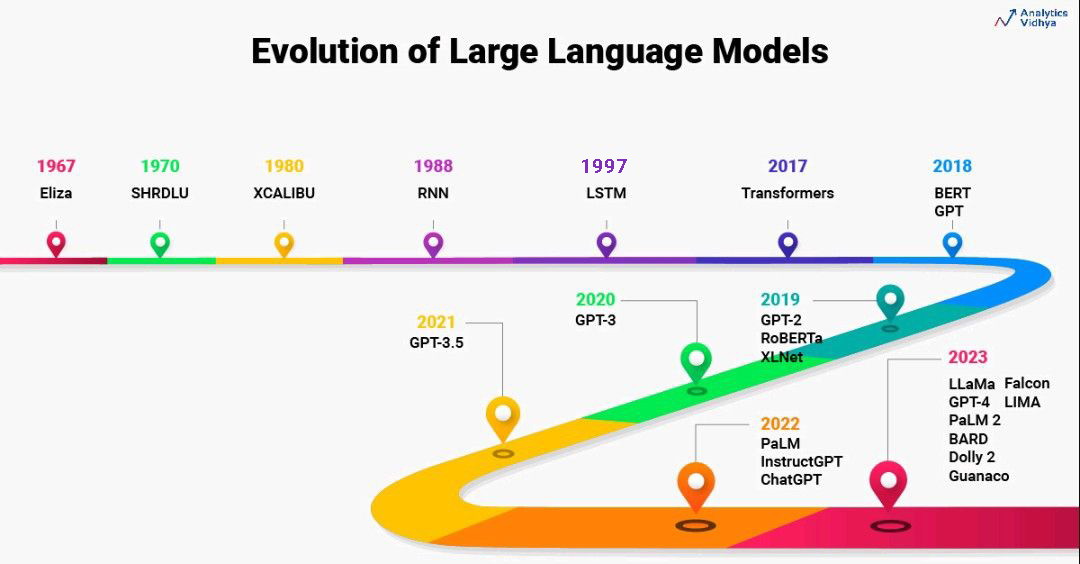
본 내용은 아래의 DSBA 연구실 세미나 발표 영상 중 Introduction을 정리한 자료입니다.
[Paper Review] Transformer to T5 (XLNet, RoBERTa, MASS, BART, MT-DNN,T5)
1. Seq2Seq
- Incoder와 Decoder 구조이며, RNN 계열로 이루어져있다.
- NMT(Neural Machine Translation)에 특화된 모델
2. Attention + Seq2Seq
- NMT(Neural Machine Translation) 측면에서 좋은 성능을 보였다.
- Decoder가 Source Sentence의 중요한 정보에 집중할 수 있도록 하는 것이 Key
3. Transformer
- NMT 측면에 초점을 맞춘 모델이다.
- Attention 기법을 발전시킨 Self-Attention, Multi-head Attention 기법을 사용하였다.
- Transformer 이후, Tranformer를 기반으로 한 수많은 모델이 NLP 분야에서 좋은 성능을 나타내고 있다.
이후 모델은 모두 Task Agnostic(Task 제한 없는) 한 모델이다.4. GPT-1
- Transformer의 Decoder Block만을 활용 →
좋은 representation 학습하는 것이 목적이다.
이를 통해 언어 자체를 이해할 수 있는 모델을 만들 수 있다. - Pre-train Model을 만든 뒤, Task에 맞춰서 Fine-Tuning하는 방식이며, 해당 방식의 시초가 된 모델이다.
5. BERT
- Transformer의 Encoder Block만을 활용 →
Bidirectional하게 맥락을 파악하는 것이 목적이다.
이를 통해 언어를 더 잘 이해할 수 있다. - 모든 NLP Task에서 SOTA를 달성하였다.
6. GPT-2
- Task Agnostic하지만, 학습을 정확히 했다면 Fine-Tuing 없이도 Task 수행이 가능하다.
- Zero-Shot만으로 좋은 성능을 내는 것이 목적이다.
- 7가지 NLP Task에서 SOTA를 달성하였다. (특히, Generation Part에서 좋은 성능을 나타내었다.)
7. XLNet
- BERT + GPT를 합친 모양이다. (실제로는 AE(Auto Encoding)과 AR(Auto Regressive)를 결합한 모델)
- 양방향 학습이 가능하다. (Factorization order를 통해)
- AR formula를 통해 BERT 한계를 극복하여, 큰 성능 향상을 보인 모델이다.
8. RoBERTa
- 가장 최적화된 BERT
- BERT가 underfitting(과소적합) 되어있음을 가정하고,
학습시간, batch size, train data를 증가시켜 강건한(Robust) 모델을 만들고자 하였다.
9. MASS
- XLNet과 같이 AE(Auto Encoding)과 AR(Auto Regressive)를 결합한 모델이다.
- Encoder와 Decoder의 상반된 Noising(Masking)을 하는 것이 특징이다.
- Encoder에서 Masking을 한다면,
Decoder에서는 Masking된 단어를 예측하고,
Encoder에서는 Masking이 되지 않은 단어에 대한 깊은 이해를 진행한다.
이렇게 Encoder와 Decoder가 상호 작용하며 학습되는 것(joint training)을 장려하는 모델이다.
10. BART
- MASS와 매우 유사한 구조를 가지는 모델이다. (AE + AR)
- MASS와 다르게 Encoder에 다양한 nosing을 추가하여,
Text generation task에서 SOTA를 달성하였다.
11. MT-DNN
- AE와 AR을 결합한 모델이 쏟아져 나오던 중 BERT 기반 Multi-Task Learning을 진행한 모델이다.
- Multi-Task Learning을 통해 Universal Representation을 생성하는 것이 목적이다.
- Pre-train 단계에서 Multi-Task Learning을 진행함으로써, Fine-Tuning의 의존도를 낮추고, 좀 더 Robust한 모델로 발전시켰다.
12. T5 (Text To Text To Transformer)
- Encoder와 Decoder, Transformer가 결합된 모델이다.
- 모든 NLP Task를 통합할 수 있도록 Text-To-Text 프레임워크를 사용하는 것이 특징이다.
- 기존에는 Pre-train 된 모델을 NLP Task에 맞게 Fine-Tuning 하여 모델을 개선하였다면,
T5는 NLP Task를 하나의 모델로 학습할 수 있도록 하였다. (T5에서 Fine-Tuning을 제외한 것은 아니다.)
Insight
- rough 하게나마 NLP 모델의 발전 흐름을 파악할 수 있었고, 이후 NLP 논문 리뷰에 도움을 줄 수 있다고 생각한다.
- 하나의 Sensational Model이 등장하면, 그 모델의 구조를 인용하여 발전시키는 모델들이 따라서 등장하는 것 같다.
- 이러한 흐름에서 새로운 방식과 구조를 제시하는 것이 NLP 분야 전체의 발전을 유도한다고 생각한다. (XLNet의 AE, AR 결합 등)
- 다양한 NLP Task에서 활용할 수 있는 Robust Model이 가치가 있다.
해석에 부족한 부분이 있을 수 있습니다. 읽어보시고 댓글로 피드백 해주시면 감사하겠습니다!
