
Abstract
- attention mechanism은 Neural Machine Translation(NMT) 분야의 발전을 이끌었지만, 그에 대한 연구가 부족하다.
- 해당 논문은 간단하고 효율적인 Attentional mechanism의 2가지 접근 방법을 소개한다.
- global attention은 모든 source words를, local attention은 일부 source words를 사용하여 한 번에 하나의 target word를 추출한다.
- WMT translation task에서 영어와 독일어의 상호 번역을 통해 효율성을 입증한다.
- 같은 조건에서 local attetion은 non attentional system에 비해 5.0 BLEU point를 향상시켰다.
- 다른 학습 조건을 적용한 attention-based model을 앙상블한 모델은 WMT' 15 English to German translation task에서 25.9 BLEU point를 달성하며 SOTA를 달성했다.
1. Introduction
- Neural Machine Translation(NMT)는 large-scale translation task에서 SOTA를 달성하였다.
- Why? 최소한의 도메인 지식을 요구하고, 개념적으로 간단하다.
- 해당 모델은 모든 source words를 필요로 하였고, 하나의 target word를 output으로 한다.
- end-to-end 구조이며, 긴 단어의 일반화 성능이 좋다. → 작은 메모리 공간을 차지한다.
- attention의 등장으로 Neural Network에서 서로 다른 modality 사이의 연결을 학습하는 등 모델의 학습 방법에 기여하였다.
- [Bahdanau et al.2015]에서 NMT 분야 최초로 attention 기반 모델을 제시하였다.
- [Xu et al., 2015]에서 hard attention과 soft attention 모델의 융합을 제시하였다.
- 해당 논문에서 attention 기반 model에서 simplicity & effectiveness를 고려한 두 가지 새로운 방법을 제시한다.
- global attention(all source words) : [Bahdanau et al.2015]와 비슷하지만, 구조적으로 더 간단하다.
- local attention(soruce words의 일부 단어) : [Xu et al., 2015]에 제안된 융합의 개념을 착안하였다. 이는 global 및 soft model 보단 계산 측면에서 효율적이고, hard model과 다르게 대부분의 경우에서 미분 가능하다.
- 또한, 이전 논문과 다르게 3가지의 alignment function 제안한다.
2. Neural Machine Translation
-
NMT 시스템은 source sentence(x_1, ,,, , x_n)를 target sentence(y_1, ,,, , y_n)로 변환하는
조건부 확률(p(y|x))을 적용한 Neural Network이다. -
NMT 기본 형태는 Encoder와 Decoder로 구성되어있다.
- Encoder : 각각의 source sentence로부터 representation(s)를 계산한다.
- Decoder : 한 번에 하나의 target word를 생성한다.
- 위 두 설명으로 조건부 확률을 아래와 같이 표현할 수 있다. (y와 x를 풀어서 설명)

-
최근 NMT 모델은 Decoder 분해 과정 모델링에 RNN 구조를 주로 사용했지만,
이는 Encoder의 representation을 계산하는 방법과는 다르다.
-
Decoder가 y_j를 산출하는 확률을 아래와 같이 표현할 수 있다.

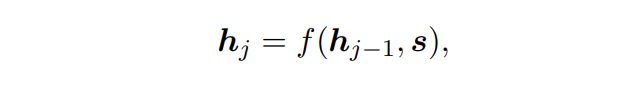
-
g( ) : argument의 vocabulary-size 벡터를 출력하는 변환 함수
-
f( ) : 이전 hidden state를 parameter로 받아 현재 hidden state를 계산하는 함수
f( )는 vanilla RNN, GRU unit이나 LSTM의 unit으로 사용된다.
-
h_j : RNN hidden unit
-
결론 : target word y_j에 대한 조건부 확률을
현재 hidden state의 vocabulary-size 벡터를 softmax를 통해 예측 분포 형태로 표현한다.
-
-
[Bahdanau et al., 2015; Jean et al., 2015]에 이어서 본 논문에서 제시하는 representation s는
Decoder의 hidden state 초기화를 위해 사용되거나,
번역 과정 전체가 반영된 source hidden state의 한 set를 의미했다.이러한 방법들은 attention mechanism으로 칭한다.
-
본 연구에서는 NMT 시스템을 위해 아래 그림과 같이 stacking LSTM 구조를 활용하고,
LSTM의 unit은 [Zaremba et al., 2015]에서 정의한 unit을 사용한다.
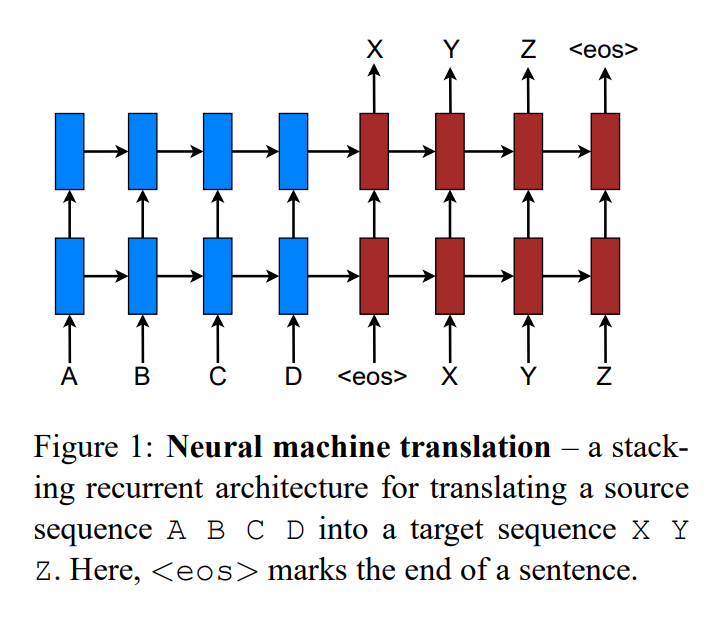
-
해당 학습의 objective(목적함수)는 아래와 같고, 변환 과정에 대한 조건부 확률의 합이 최적화 대상이 된다.
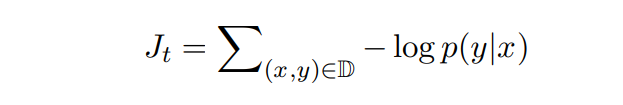
- D : parallel한 학습 시 하나의 그룹
3. Attention-based Models
-
크게 global attention(all source)와 local attention(only a few source)로 나뉘는데, Decoding 과정 중 stacking LSTM의 top layer에서 input으로 hidden state h_t가 필요하다는 것은 동일하다.
-
이후에 현재 target word y_t 예측을 돕기 위해
source 정보가 포함된 context vector c_t를 도출하는 것이 목표이다. -
global attention인지 local attention인지에 따라 context vector c_t를 도출하는 방법이 다르지만, 이후 과정은 동일하다.
-
아래는 hidden state h_t와 context_vector c_t를 concatenation하여 두 vector 정보를 결합한 layer(concatenation layer)를 활용해 아래와 같이 attentional hidden state(attentional vector) ˜h_t를 구할 수 있다.
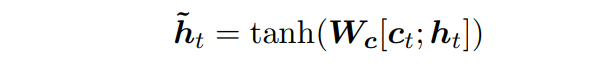
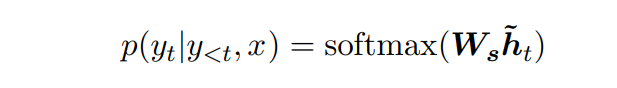
- W_c : concatenation layer의 가중치, concatenation을 attentional vector 형태로 변환하기 위해 필요하다.
- [c_t; h_t] : context vector와 hidden state의 concatenation
- W_s : softmax layer의 가중치, attentional hidden state를 vocabulary-size 벡터로 변환한다.
- 결론 : target word y_j에 대한 조건부 확률을 자세히 풀면,
attentional vector ˜h_t의 vocabulary-size 벡터로 변환하고,
softmax를 통해 예측 분포 형태로 산출한다.
attentional vector는 context vector와 현재 hidden state가 필요하다.
-
아래 3.1절과 3.2절에서 context vector c_t를 계산하는 방법에 대해 자세히 설명한다.
3.1 Global Attention
-
Encoder의 모든 hidden state를 반영하여 c_t를 산출하는 접근방법이다.
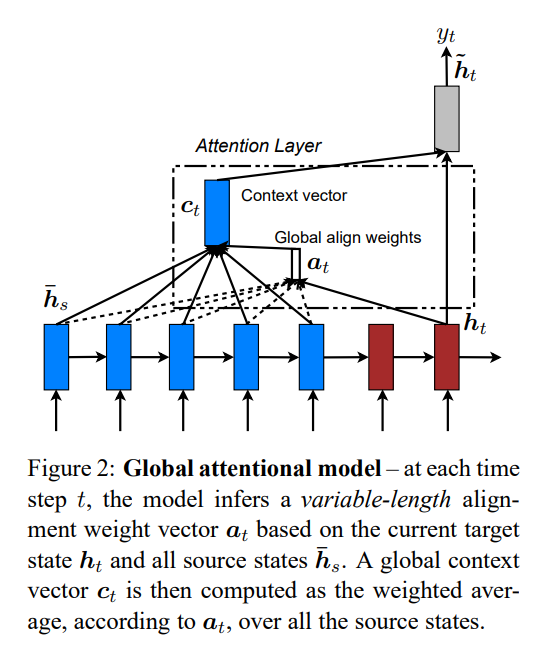
-
alignment vector a_t는 다양한 길이로 존재하는데, 이 때 size는 source side의 time step 개수와 동일하다.
-
attention-based model 구축 초기, location-based function을 통해 alignment vector(alignment score) a_t를 산출하였다. (source hidden state ¯h_s 없이 target hidden state h_t만을 사용)
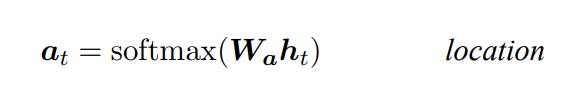
-
아래 alignment vector a_t는 content-based function이며, 현재 target hidden state h_t와 각각 source hidden state ¯h_s(¯h_s’) vector를 비교하여 산출한다.
- dot : source hidden state와 target hidden state의 내적
- general : source hidden state에 W_a를 곱한 뒤 target hidden state 와 내적
- concat : 두 벡터(source hidden state와 target hidden state)를 concat한 뒤, W_a를 곱하고, activate function(tanh)을 거친 뒤, v_a vector와 내적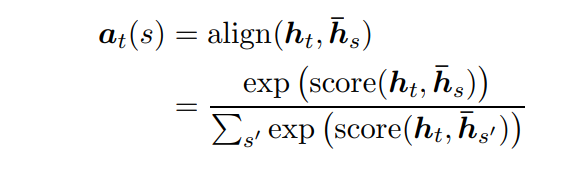
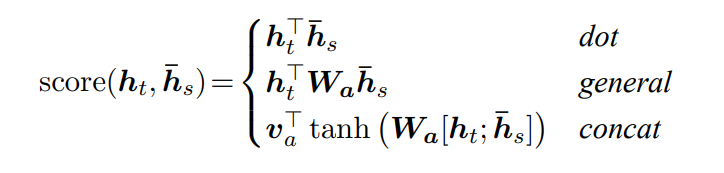
-
alignment vector a_t를 통해 산출한 context_vector c_t는 모든 source hidden state를 고려하여 가중 평균을 계산한다.
-
-
[Bahdanau et al., 2015] 와의 차이점 (더 단순하고 일반화된 방법을 사용하였다.)
1) Encoder와 Decoder 둘 다 LSTM top layer의 hidden state를 사용한다. (Figure 2 참고)
Bahdanau : bi-directional encoder의 forward & backward source hidden state 결합체와
non-stacking uni-directional decoder의 target hidden state를 사용하였다.2) 계산 경로가 더 간단하다. (Figure 2 참고 : h_t → a_t → c_t → ˜h_t)
Bahdanau : 이전 hidden state로 부터 현재 h_t를 산출한다. (h_t−1 → a_t → c_t → h_t)3) 다양한 alignment function를 통한 실험을 진행했다.
Bahdanau : alignment function으로 concat만을 사용하여 실험을 진행했다.
-
global attention은 모든 source word를 사용하기 때문에 long sequence translation에서 많은 비용이 필요하다.
3.2 Local Attention
-
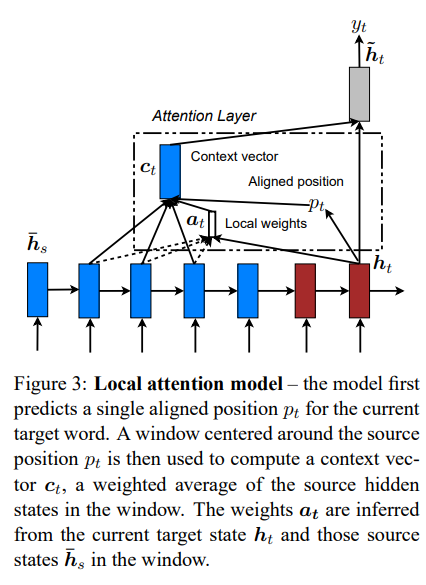
각 target word가 모든 source word를 반영하는 global attention의 단점을 보완하기 위해 source words 일부 만을 집중해서 선택하는 방법이다.
-
image caption generation 관련 논문인 [Xu et al. 2015]에서 제안한 soft와 hard attentional models 사이의 tradeoff를 반영했다.
- soft attention : source image의 모든 patch를 반영하여 softly하게 가중치를 두는 방식으로
- global attention과 유사하다.
- hard attention : 한 time에 반영할 이미지의 patch 1개만을 선택하는 방식이다.
- inference 비용이 더 적지만, 미분불가능하고, 더 복잡한 학습 기술이 필요하다. (분산 축소, 강화 학습 등)
- soft attention : source image의 모든 patch를 반영하여 softly하게 가중치를 두는 방식으로
-
해당 논문에서 제시하는 local attention은 context의 small window에 선택적으로 집중하고, 미분이 가능하다.
- soft attention의 단점(expensive computation)을 보완하고,
- hard attention과 달리, 미분가능 + 쉽게 학습이 가능하다.
-
자세한 과정은 아래와 같다.
- time t에서 각각의 target word를 위해 aligned position p_t를 generate한다.
- 그 다음, window 범위만큼 source hidden state 한 set를 가중치 평균 계산하여 context vector c_t을 산출된다.
- window 범위는 aligned position p_t을 기준으로 +-D이며, [p_t-D, p_t+D]와 같이 표현한다. 이 때, D는 empirically(경험적으로) 값을 부여한다.
-
이 때, global attention과 다르게, local의 alignment vector a_t는 차원이 고정되어있다. (예 : 2D+1 차원 등)
-
aligned position은 두 가지 방법에 의해 결정된다.
- Monotonic alignment (local-m)
- 가정 : source sequence와 target sequence는 거의 monotonically(단조롭게) 정렬된 상태이다.
- aligned position p_t = time t
- alignment vector a_t는 global attention에서 산출한 방법과 동일하다.(a_t(s) 수식 참고)
- Predictive alignment (local-p)
-
model을 통해 aligned position p_t를 예측한다.
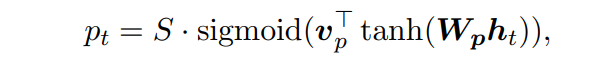
- W_p, v_p : 모델의 position 예측을 위해 학습되는 parameters이다.
- h_t : target hidden state
- S : source sentence의 길이
- p_t를 [0, S]로 제한하기 위해 sigmoid 결과 (0~1 사이 값)에 S를 곱한다.
-
global의 alignment vector a_t를 구하는 식에
p_t를 중심으로 한 Gaussian 분포를 곱하여,
p_t와 가까울수록 alignment score에 높은 가중치를 부여한다.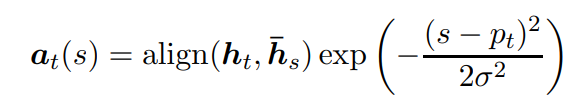 - σ : 표준편차이며, D/2와 같이 경험적으로 값을 부여한다.
- σ : 표준편차이며, D/2와 같이 경험적으로 값을 부여한다.
- s : “p_t를 중심으로 한 window” 내의 정수 값이다.
-
- Monotonic alignment (local-m)
-
[Gregor et al., 2015]에서 제안한 selective attention과 매우 유사하지만, 더 단순하다.
- selective attention은 모델이 다양한 location과 zoom의 image patch를 선택할 수 있고,
- local attention은 모든 target position에 같은 zoom을 사용함으로써 계산 단순화와 동시에 좋은 성능을 유지한다.
3.3 Input-feeding Approach
- attentional vector ˜h_t를 다음 time step의 input으로 제공함으로써,
과거 alignment decision에 대한 정보를 모델에 반영하는 방법이다.
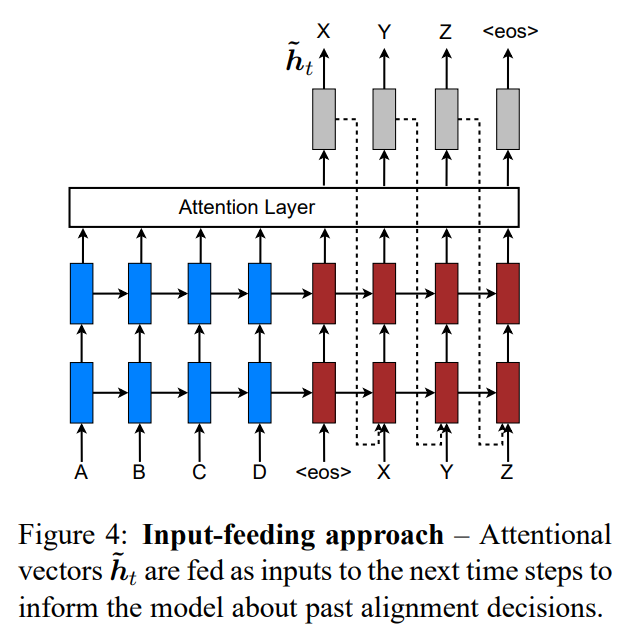
- standard MT에서 어떤 source words가 변환된 것인지 추적하기 위해 translation 과정동안 coverage set을 보관한다.
- attentional NMTs에서도, alignment decision은 이전 alignment 정보와 유기적으로 연결하기 위해 input-feeding을 제안한다.
- input-feeding은 attentional vector ˜h_t를 다음 time steps에서 input과 함께 결합시킨다.
이를 통해 이전 alignment choice를 model이 알 수 있으며,
수평, 수직적으로 확장하는 매우 깊은 network을 만들 수 있다. - other works와 비교
- [Bahdanau et al. 2015]에서 subsequent(다음) hidden state를 구축할 때,
context vector c_t를 사용하여 coverage 효과(이전 정보 포함)를 얻었지만,
이러한 연결이 유용한지 아닌지에 대한 연구가 이루어지지 않았다.
- [Xu et al. 2015]은 제약 조건이 추가된 doubly attentional approach를 제안한다.
- training objective(목적함수)가 더해진 제약 조건은
image caption generation 시, 모든 part에서 동일한 attention을 사용하도록 하고,
NMT에서 앞서 언급한 coverage 효과를 보다 빠르게 얻을 수 있다.
- 그러나, input-feeding approach은 모델에 맞는 attentional한 제약 조건을 결정할 수 있는 flexibility가 존재한다.
- training objective(목적함수)가 더해진 제약 조건은
- [Bahdanau et al. 2015]에서 subsequent(다음) hidden state를 구축할 때,
4. Experiments
- 영어와 독일어 간 상호 WMT 번역 task의 효과성을 평가한다.
- newstest2013(3000개 문장)은 hyperparameter 선정을 위한 development set으로 사용된다.
- 번역 성능 지표로 2가지 type의 BLEU를 사용한다.
- tokenized BLEU : 기존 NMT works와 비교할 수 있다.
- NIST BLEU : WMT 결과와 함께 비교할 수 있다.
4.1 Training Details
- 데이터 셋
- WMT’ 14 traning data
- 4.5M sentences pairs 중 최빈단어 상위 50K로 제한하고, 나머지는 로 변환하며, 길이가 50 단어보다 클 경우 filtering되고, 학습 과정에서 mini-batch를 섞는다.
- 모델 구조
- 4개의 층으로 이루어진 LSTM model
- 각 층은 100개의 cell과 1000차원의 embedding을 가진다.
- 학습 방법
1) parameter : [-0.1, 0.1] 범위에서 균일하게 초기화된다.
2) 10 epochs, SGD
3) 초기 learning rate = 1이고, 5 epoch 이후로는 매 epoch마다 learning rate를 절반으로 줄인다.
4) mini-batch size = 128이고, nomalized gradient가 5를 넘을 시, 재조정한다.
5) LSTM에서는 0.2의 확률로 dropout을 사용하고,
dropout의 경우 12 epoch까지 학습되고, 8 epoch 후에 learning rate를 절반으로 줄인다.
local attention에서 window 범위를 결정하는 D를 10으로 설정한다. - 실험환경
- MATLAB을 통해 구현한다.
- 단일 GPU device Tesla K40에서 초당 1K의 target word를 처리하며, 7-10일동안 학습한다.
4.2 English-German Results
-
비교 대상
- Winning WMT’ 14 system [Buck et al., 2014]
- WMT'14에서 우승한 phrase-based system이다.
- 거대한 단일 언어 텍스트인 Common Crawl corpus에서 훈련되었다.
- RNNsearch [Jean et al., 2015]
- 해당 language pair에 대해 유일하게 실험한 system이다.
- 최근 SOTA이자 end-to-end 형태의 NMT system이다.
- Winning WMT’ 14 system [Buck et al., 2014]
-
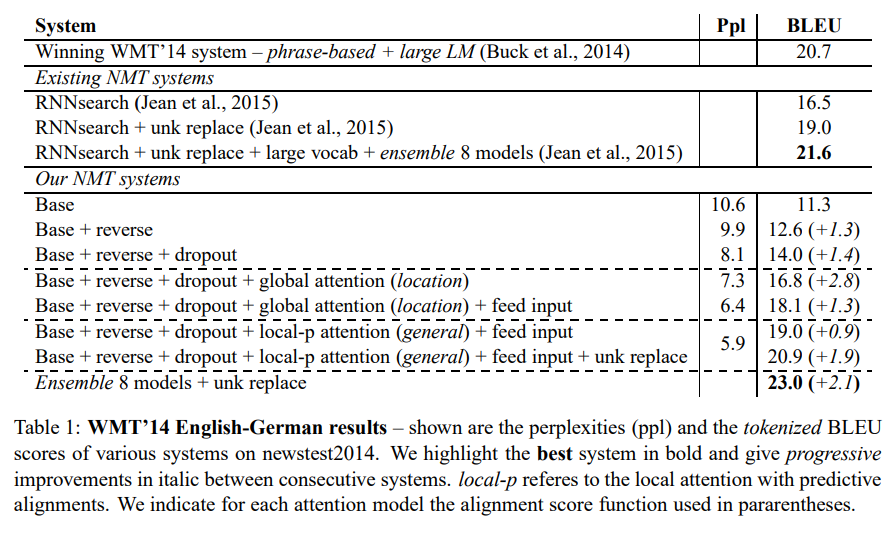
Table 1은 newstest2014에서 다양한 시스템의 perplexities(ppl), tokenized BLEU score 이다.
- perplexities(ppl)은 번역 quality 평가척도이다.
-
BLEU 향상 요인
1) reserve(source sentence의 확보) ➡️ +1.3 BLEU
2) + dropout ➡️ +1.4 BLEU
3) + global attention (location) ➡️ +2.8 BLEU
이 때 16.8 BLEU로 RNNsearch(16.5 BLEU)보다 더 좋은 성능을 보였다.
4) + input-feeding ➡️ +1.3 BLEU
5) global → local-p (predictive alignments) ➡️ +0.9 BLEU
최종적으로 attention(local-p, input-feeding) 적용 이후, +5.0 BLEU 달성했다.
6) + unk replace ➡️ +1.9 BLEU
이전 논문에서 제시된 기법이다. (Luong et al., 2015; Jean et al., 2015)
7) + Ensemble 8 models ➡️ +2.1 BLEU
다양한 초기조건을 가진 8개의 모델 (dropout 유무, global/local attention 등) 을 앙상블한 모델이 성능 향상을 보였다.
해당 모델을 본 논문에서 best model로 선정하였다. -
결론적으로 기존보다 SOTA보다 1.4 BLEU 큰 23.0 BLEU를 보이며, 새로운 SOTA를 달성하였다.
-
아래는 best model을 WMT’15 데이터로 학습시킨 결과이다.
- newstest2015는 더 큰 데이터를 가지며, 이 또한, 기존 SOTA 보다 1.0 BLEU 더 높은 성능을 보이며, 새로운 SOTA를 달성하였다.

4.3 German-English Results
-
WMT’15 데이터로 비슷한 형태의 독일어 → 영어 번역 실험을 진행하였다.
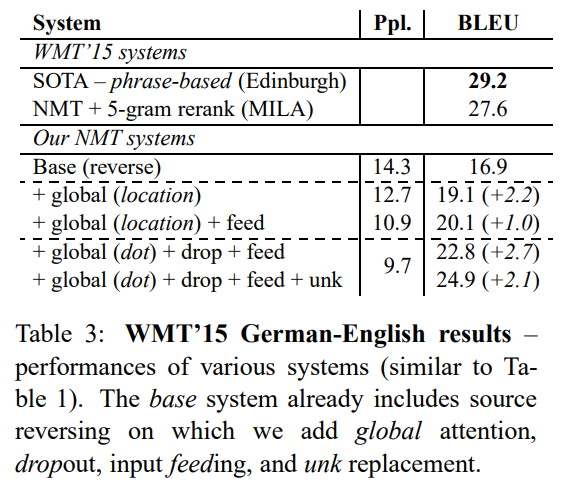
-
해당 task에서 24.9 BLEU로 SOTA를 달성하지 못했지만, 아래와 같은 성능 향상을 보였다.
- +global attention(location) ➡️ +2.2 BLEU
- +input-feeding ➡️ +1.0 BLEU
- 주목할 점은 local attention이 아닌, global attention 중 dot 형태의 alignment function이 해당 task에서는 좋은 성능을 보였다. ➡️ +2.7 BLEU
- +unk ➡️ +2.1 BLEU
5. Analysis
- 아래 정보는 newstest2014 English-German 기준이다. (Table 1 참고)
5.1 Learning curves
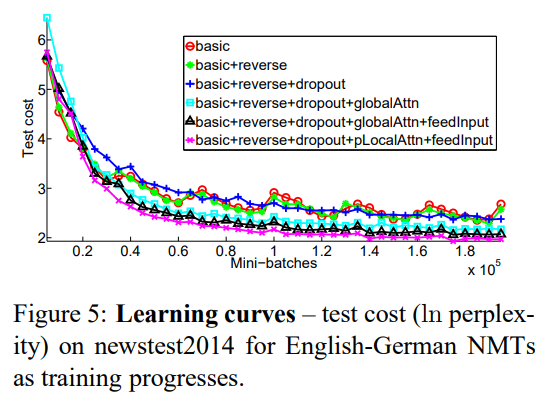
- Figure 5를 보면 non-attentional model과 attentional model 간 명확한 차이가 존재한다.
- input-feeding과 local attention model을 함께 사용한 모델(보라색 커브)이 더 낮은 test cost를 달성하였다.
- non attential model이면서 dropout을 사용한 모델(진한 파란색 커브)는 non dropout에 비해 더 천천히 학습되지만, 시간이 지나면서 test error minimizing 측면에서 더욱 robust해진다.
5.2 Effects of Translating Long Sentences
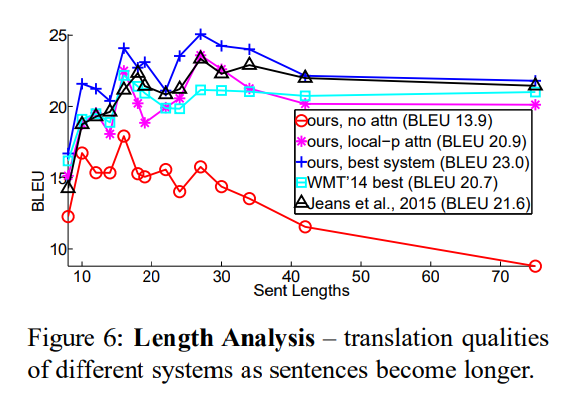
- 문장의 길이에 따라 번역 성능이 달라진다.
- 그 중 non attentional model은 문장이 길어질 때, 성능 방어를 하지 못했다.
- ours, best system(진한 파란색 커브)은 모든 길이에서 다른 시스템보다 좋은 성능을 보였다.
5.3 Choices of Attentional Architectures
- 본 논문에서 3가지 유형의 attentional model (global, local-m, local-p) 과
총 4가지의 alignment function (location, dot, general, concat) 이 존재한다.
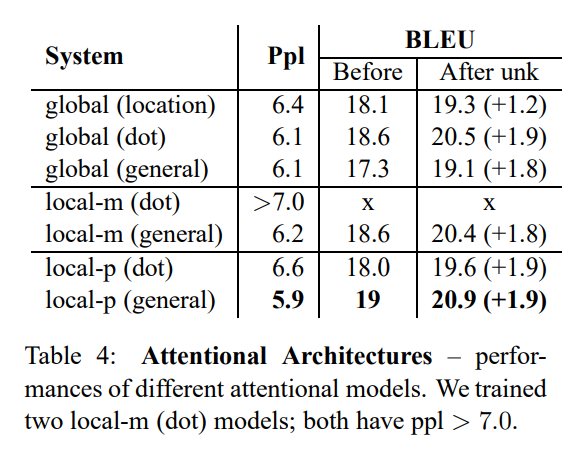
- global + location 조합은 unk replace 시 성능 향상이 다른 alignment function과 비교하여 작다.
- content-based function 중
- concat은 좋은 성능을 보이지 못했고, 해당 결과에 대한 원인 분석이 필요하다.
- global attention 중 dot function이
- local attention 중 general function이 더 좋은 성능을 보였다.
- attention model 중
- local-p가 ppl, BLEU 측면에서 가장 좋은 성능을 보인다.
5.4 Alignment Quality
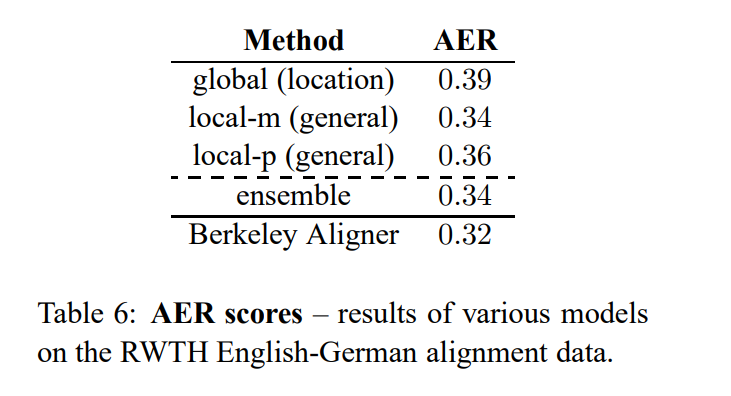
- attention-based model을 위해 word alignment가 함께 필요하고, 위 Table 6가 해당 논문에서 제시된 모델의 alignment quality를 평가한 표이다.
- 평가지표로 AER(Alignment Error Rate)를 사용하였다.
- 각 target word 당 가장 높은 alignment weight를 가진 source word를 선택함으로써 only one-to-one alignment를 추출했다.
- Table 6을 보면, Berkely Aligner의 one-to-many alignments과 비교하여 더 높은 AER을 보였다.
- Table 6을 보면, global > local > ensemble 순으로 AER이 낮아짐을 알 수 있다.
- 이에 alignment quality와 translation score 사이의 상관관계가 없다는 의견을 제시한다.
5.5 Sample Translation
- 아래는 model을 통한 번역의 예시이다.
- src : source(input)
- ref : human translation (정답값으로 생각한다.)
- best : 논문에서 제시한 best attention model을 통한 결과(output)
- base : non attention model을 통한 결과(output)
- 파란색 글 : 올바른 해석
- 빨간색 글 : 틀린 해석
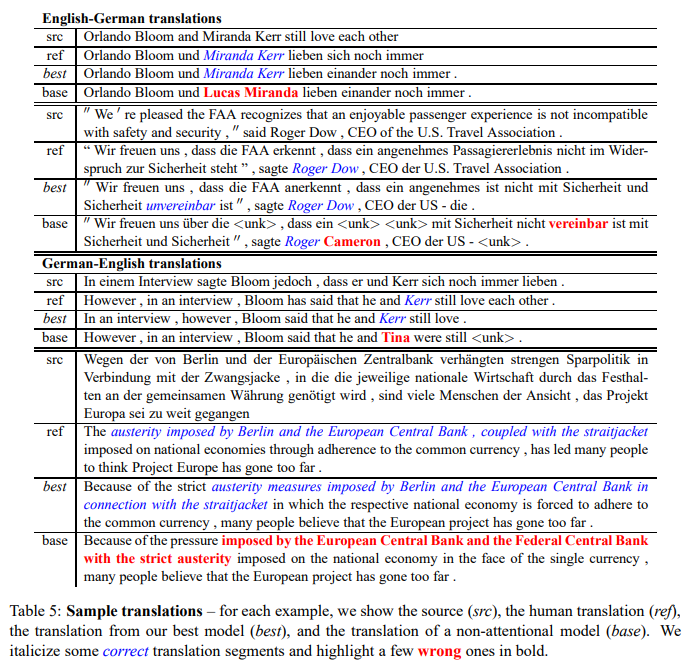
- non attention-based model은 해당 model의 관점은 sensible(그럴듯한?) 이름을 제시하지만, source side와의 직접적인 연결이 부족하여 정확한 번역을 하기 힘들다.
- attention-based model은 이중 부정 구문(예 : not incompatible) 번역이 가능하지만,
non attention-based model은 이중 부정 구문에 대한 번역이 불가능하다. - attention-based model은 긴 문장 번역에 대한 성능이 좋다.
6. Conclusion
- NMT 분야에서 간단하고 효과적인 attention mechanism을 제시하였다.
- global approach : 한 번에 모든 source position을 사용한다.
- local approach : 한 번에 일부 source position을 사용한다.
- WMT translation task에서 실험한 결과,
- non attention-based model에 비해 +5.0 BLEU의 성능 향상을 이끌어냈다.
- 특히, 앙상블 모델을 통해 English → German 번역 분야에서 SOTA를 달성했다. (WMT’14, WMT’15)
- 다양한 alignment function에 대한 비교 실험을 진행하고, 어떤 function이 어떤 attention-based model에서 성능이 가장 좋은지 확인했다.
- 해당 논문으로 다양한 사례(name translation, long sentence)에서 non attention-based model보다 attention-based model이 더 뛰어나다는 것을 보여줬다.
Insight
attention 개념을 NMT 분야에 적용시켜 성능을 대폭 향상시킨 모델이다. 특히, 크게 global attention과 local attention 두 가지 방법론을 제시했는데, global attention은 기존 NMT 분야에서 좋은 성능을 보이던 방법론에서 착안하였고, local attention은 image caption generation이라는 타 분야에서 활용된 방법론에서 착안하였다. 새롭게 접하는 방법론을 다른 분야에 적용이 가능한가?에 대한 시각이 필요하다는 것을 배울 수 있었다. 이러한 시각은 추후 연구 주제를 탐색하는데, 긍정적인 영향을 줄 수 있을 것이라 생각한다.
Alignment Quality를 파악하는 평가지표로 Alignment Error Rate(AER)을 사용하였다. 해당 논문에서는 BLEU score와 AER 결과가 비례하지 않음을 보며, 두 값 사이의 상관관계가 없다는 의견을 제시하였다. 해당 논문에서 제시한 모델이 translation을 하는 과정에서 alignment이 포함되어있기 때문에 일반적으로 alignment quality가 translation score에도 영향을 줄 수 있다고 생각한다. 하지만 해당 논문에서는 상관관계가 없다는 결론이 모델의 결과로만 제시된 측면이 아쉬웠다. alignment quality를 측정하는 다른 평가지표가 존재한다면, 그것에 대한 추가 검증을 통해 해당 결론에 대한 이해를 높일 수 있다고 생각한다.
