[DB : Data] AI 데이터 구축을 위한 데이터 라벨링이란??

▽ [DB : Data] AI 데이터 구축을 위한 데이터 라벨링이란??

데이터 라벨링이란??
최고의 요리가 좋은 재료에서 시작되듯, AI 솔루션의 품질 도한 고품질의 데이터에 달려 있습니다.
데이터 라벨링은 AI 데이터를 준비하는 과정 중 하나로, [수집-라벨링-전처리 단계]를 포함합니다.
데이터 라벨링(Data Labeling)이란 머신러닝, 딥러닝 모델이 학습할 수 있도록
데이터에 의미 있는 ‘정답’(레이블, Label)을 붙이는 작업을 말합니다.
쉽게 말해, 모델에게 “이 데이터가 무엇을 의미하는지” 알려주는 과정입니다.
1. 기본 개념.
- 데이터(Data) : 모델이 학습할 원재료.
- 예를 들어 이미지, 텍스트, 오디오, 비디오 등
- 레이블(Label) : 데이터의 의미나 정답을 나타내는 태그.
- 예 : 사진 속 사물이 사물이 '고양이'인지 '강아지'인지,
문장의 감정이 '긍정'인지 '부정'인지
- 예 : 사진 속 사물이 사물이 '고양이'인지 '강아지'인지,
- 목적 : 모델이 입력 데이터와 출력 레이블 간의 패턴을 학습할 수 있도록 함.
2. 데이터 라벨링의 유형.
- 이미지/영상 라벨링.
- 분류(Classfication) : 이미지 전체에 레이블 지정.
- ex) 이 사진은 '자동차', 이 사진은 '자전거'
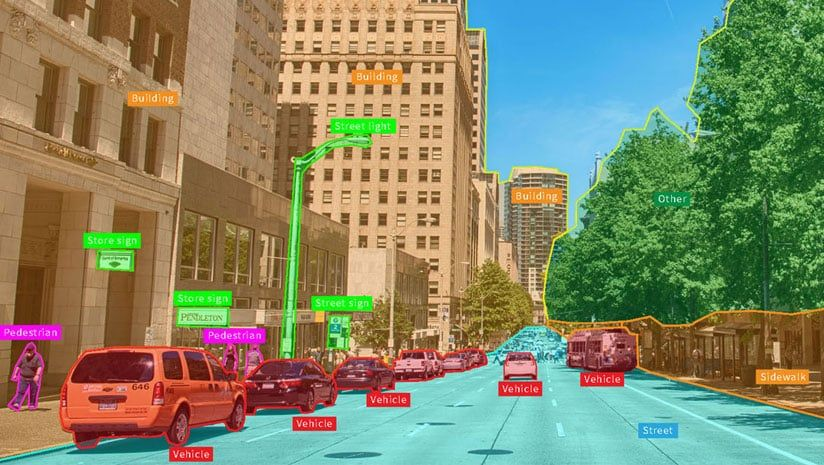
- 객체 탐지(Object Detection) : 이미지 내 객체 위치와 종류 표시.
- ex) 자동차의 경계 박스 + '자동차' 라벨.
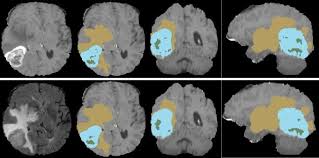
- 세그멘테이션(Segmentation) : 이미지 픽셀 단위로 객체 구분.
- ex) 자율주행 차량에서 도로, 보행자, 차선 구분.
- 텍스트 라벨링.
- 감정 분석(Sentiment Analysis) : 긍정, 부정, 중립
- 개체명 인식(NER : Named Entity Recognition) : 사람, 장소, 조직 등 태깅.
- 주제 분류(Topic Classfication) : 뉴스 기사, 리뷰 등 주제 구분.
- 오디오/음성 라벨링.
- 음성 인식: 발화된 문장 텍스트 변환.
- 감정 라벨링: 음성의 감정 태그 부여.
- 사운드 이벤트 인식: 특정 소리(경적, 박수 등) 구분.
3. 데이터 라벨링의 중요성.
AI는 크게 데이터와 코드로 이루어짐. AI의 성능을 높이려면 데이터나 코드의 퀄리티를 높여줘야 함.
데이터 품질을 좌우하는 첫 걸음은 바로 정확한 좋은 데이터를 확보하는 것, 즉 데이터 라벨링에서 시작됨.
데이터 라벨링이 제대로 이루어지지 않으면, AI는 학습할 수 있는 올바른 데이터를 제공받지 못하고, 그 결과 성능이 저하될 수 밖에 없음.
-
모델 성능 결정 : 모델의 학습 품질은 라벨링 정확도에 크게 의존.
-
오류 방지 : 잘못된 라벨은 모델이 잘못 학습하도록 유도.
-
다양성 확보 : 충분하고 다양한 데이터 라벨링으로 모델 일반화 능력 향상.
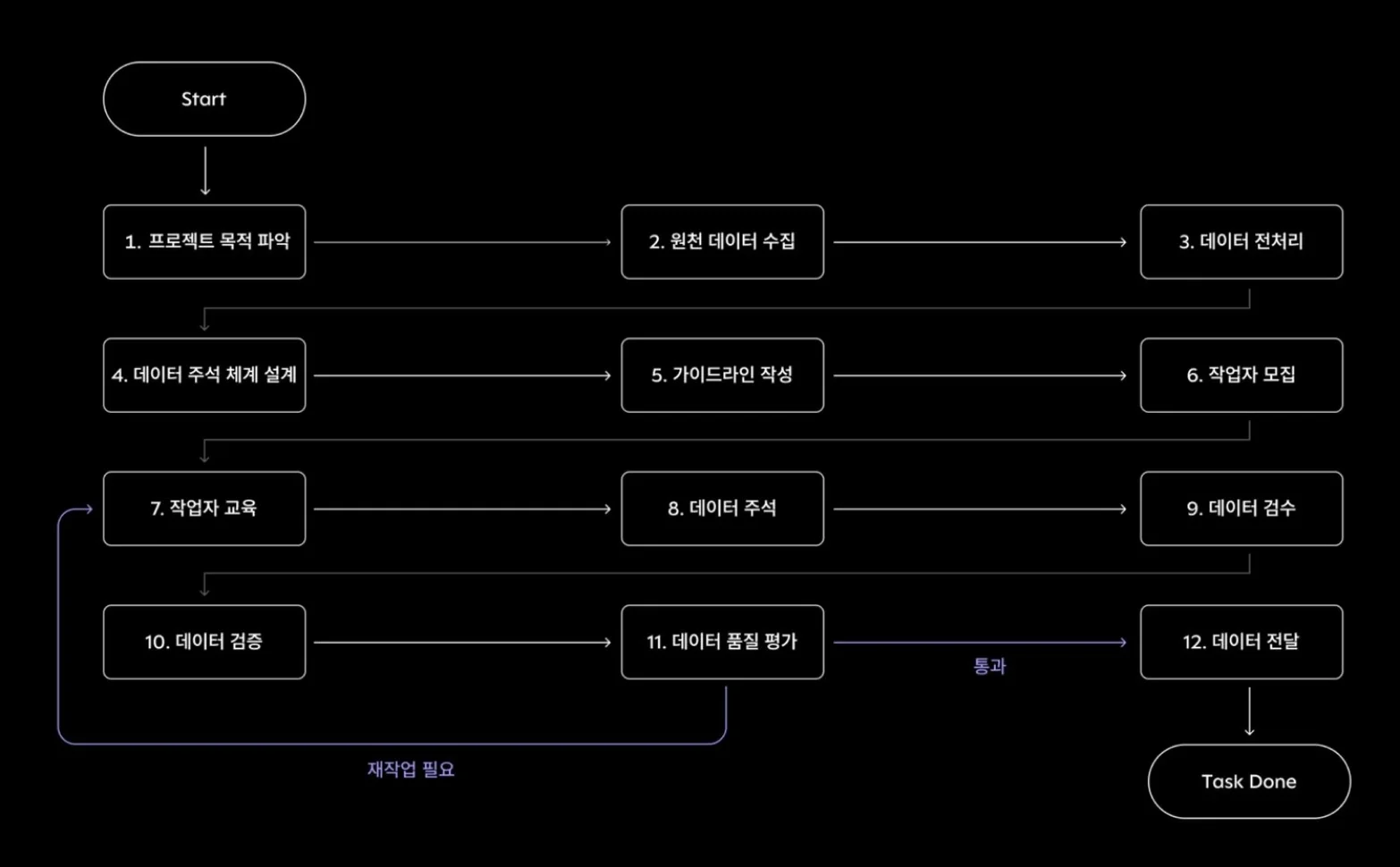
4. 데이터 라벨링 진행 절차.
-
-
프로젝트 목적에 맞는 원천 데이터 수집 : 원시 데이터 확보.
- 오픈 데이터 소스 수집(AI hub 등)
- 인터넷 데이터를 크롤링하여 수집
- 기존에 가지고 있던 사내 혹은 개인 데이터 활용
- 자체적으로 데이터 수집.
-
원천 데이터를 수집하는 방법은 다양합니다.
먼저, 프로젝트의 태스크를 해결할 수 있는 데이터의 형태를 정의하고,
쿼리를 작성하여 따로 수집하는 작업을 거치게 됩니다.
이렇게 데이터 수집 단계 이전이나 수집 단계에서 AI 모델 기획은 이미 완성이 되어 있어야 합니다.
모델의 목적과 아웃풋에 따라 어떤 데이터를 수집해야 할 지가 결정되기 때문입니다.
대량의 데이터의 경우 수집하는 시간도 오래 걸리기 때문에 충분한 시간을 두어야 합니다.
-
-
데이터 전처리.
- 수집한 원천 데이터를 바로 라벨링할 수 있지만, 앞서 언급했듯 라벨링 작업은 상당한 노동력이 필요하고, 노동력은 비용으로 직결되는 문제입니다.
- 따라서 퀄리티 높은 데이터를 전달해야 비용 대비하여 퀄리티 높은 라벨링 결과가 나올 수 있기 때문에 데이터 전처리 작업이 필요.
-
-
-
데이터 라벨링 설계.
- 전처리된 데이터를 라벨링 단계로 전달하고, 라벨링 완료된 데이터를 어떻게 받을 것인지 설계하는 단계입니다.
- Input과 Output의 형태 및 형식부터 자세한 라벨링 방식, 모호한 부분에 대한 처리 방법 등을 고민하는 단계.
-
-
-
라벨링 가이드 작성 : 어떤 기준으로 라벨을 붙일지 설계.
- 설계가 끝났다면, 라벨러가 정확하게 작업을 수행할 수 있도록 명확하고 구체적인 라벨링 가이드를 작성합니다.
- 가이드는 진행할 태스크에 대한 명확한 설명과 데이터 구축의 목적, 용어 등 중요하게 고려해야 할 사항을 보기 쉽게 설명하는 것이 중요.
- 가이드에는 필요한 도메인 지식이 있다면 반드시 포함시키면서, 주관성이 짙을 것으로 예상되는 데이터의 경우에는 라벨링 결과 예시도 함께 넣는 것이 좋습니다.
- 설계가 끝났다면, 라벨러가 정확하게 작업을 수행할 수 있도록 명확하고 구체적인 라벨링 가이드를 작성합니다.
-
-
- 라벨링 수행 : 사람이 직접 라벨링하거나, 반자동/자동 툴 활용.
-
- 검수 및 QA : 라벨 정확도 확인, 수정
-
- 학습용 데이터셋 생성 : 모델 학습에 사용할 최종 데이터 준비.
좋은 데이터란 무엇일까?

좋은 데이터(Good Data)란 Ai/데이터 분석/머신러닝 모델이 신뢰할 수 있는 결과를 만들어낼 수 있도록 충분히 정확하고, 다양하며, 의미있는 특성을 가진 데이터. !
단순히 많다고 좋은 것이 아니라, 품질과 구조, 다양성이 확보된 데이터가 핵심.
1. 좋은 데이터의 특징.
-
- 정확성(Accuracy)
- 데이터 자체가 사실과 일치해야 함.
- 라벨이 잘못되거나, 잘못 기록된 값이 없어야 함.
- ex) 키와 몸무게 데이터에서 단위 오류 없이 기록됨.
- 정확성(Accuracy)
-
- 완전성(Completeness)
- 결측치(Missing Value)가 적거나 없고, 필요한 속성이 모두 포함됨.
- ex) 고객 데이터라면 이름, 연락처, 구매 이력 등 필수 정보가 모두 존재.
- 완전성(Completeness)
-
- 일관성(Consistency)
- 동일한 유형의 데이터가 일관된 형식과 기준으로 저장됨.
- ex) 날짜 표기가 yyyy-mm-dd로 통일. 성별을 M/F로 통일.
- 일관성(Consistency)
-
- 다양성(Diversity)
- 데이터가 모델이 학습해야 할 다양한 상황과 케이스를 포함.
- 편향(Bias) 없이 다양한 연령, 지역, 상황 등 반영
- ex) 얼굴 인식 모델 학습 시 다양한 인종과 조명 조건 포함.
- 다양성(Diversity)
-
- 적시성(Timeliness)
- 최신 데이터여야 모델이 현실을 잘 반영
- ex) 뉴스 기사 분석 모델은 오래된 데이터보다 최신 트렌드 데이터가 중요
- 적시성(Timeliness)
-
- 중복 없음(No Redundancy)
- 중복 데이터가 많으면 모델 학습이 왜곡될 수 있음.
- 예: 동일한 이미지가 여러 번 학습 데이터에 포함되지 않도록 주의.
- 중복 없음(No Redundancy)
-
- 레이블 품질(Label Quality)
- 특히 지도학습(Supervised Learning)에서는 정확하고 일관된 라벨링이 필수.
- 예: 감정 분석 데이터에서 긍정/부정을 정확히 구분.
- 레이블 품질(Label Quality)
2. 좋은 데이터와 AI 모델의 관계.
| 특징 | 모델에 미치는 영향 |
|---|---|
| 정확성 | 잘못된 학습 방지, 예측 신뢰도 향상 |
| 다양성 | 일반화 능력 향상, 과적합 방지 |
| 일관성 | 안정적인 학습, 오류 감소 |
| 완전성 | 모델 입력 오류 방지, 성능 저하 방지 |
| 레이블 품질 | 지도학습 성능 핵심 |
💡 한마디 요약:
“좋은 데이터가 있어야 좋은 모델이 나온다.”
데이터가 쓰레기라면 아무리 최신 알고리즘을 써도 결과는 쓰레기(Garbage In, Garbage Out).
