[ DB & SQL(RDBMS, NoSQL) ] 데이터 베이스 기초 이해_01.

🎯 학습 목표.
-
데이터와 정보의 개념 구분 및 실무에서의 적용 이해
-
데이터베이스와 DBMS의 본질 및 구조적 철학 습득
-
다양한 DB 유형(RDBMS, NoSQL, NewSQL, In-Memory, Cloud DB)의 구조적 차이 이해
-
CAP 이론과 BASE 모델 등 분산 시스템의 핵심 이론 습득
-
데이터 독립성과 논리적 설계 중요성에 대한 인식 확보
목 차
1. 데이터 vs 정보: 본질적 구분과 실무 적용.
2. 데이터베이스(Database)의 정의와 철학
3. DBMS(Database Management System)란?

1. 데이터 vs 정보: 본질적 구분과 실무 적용.
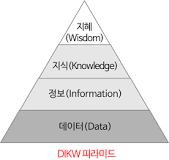
1.1 데이터와 정보의 철학적 / 이론적 기반
1-1-1. 개념 정의와 구분.
-
데이터(Data): 맥락 없이 존재하는 사실의 단편 (예: 25, 서울, A001)
-
정보(Information): 데이터를 해석 가능한 형태로 가공한 것 (예: "서울의 기온은 25도입니다.")
-
지식(Knowledge): 정보를 축적해 의미 있는 의사결정을 가능케 하는 기반
-
지혜(Wisdom): 경험 기반 판단의 통찰 (DIKW 모델에서 최상위 개념)
1-1-2. DIKW 피라미드 모델
-
ex)
-
데이터: 수강생 ID, 출석일, 결석여부
-
정보: 출석률 계산 → "5월 출석률 80%"
-
지식: "출석률 80% 이하인 학생의 성적이 낮다"는 통계
-
지혜: 출석률 기준의 조기 경고 시스템 설계
-
1.2 실무에서의 데이터와 정보의 구분.
1-2-1. 비즈니스 로직에서의 데이터 활용.
-
로그 수집 시스템: 원시 데이터 수집 (e.g., ELK, Kafka)
-
ETL 파이프라인: 데이터를 정제하여 정보로 변환 (Spark, Airflow)
-
BI 도구와 리포팅: 최종 사용자에게 제공될 ‘정보’의 형태 (Tableau, Power BI)
1-2-2. 데이터 품질이 정보 신뢰성에 미치는 영향.
-
결측치(Missing Value), 이상치(Outlier) → 정보 왜곡의 원인
-
정규화된 데이터 저장이 정보 일관성에 기여
1.3 데이터 → 정보로의 전환 과정에서 요구되는 기술 역량.
1-3-1. 데이터 처리 기술 스택.
-
백엔드 관점: 데이터 수집 → DB 저장 → API 응답
-
통계/ML 관점: Raw Data → Feature Extraction → Result Interpretation
1-3-2. 정보로 가공하기 위한 전처리/정규화/집계 기술.
-
정규화(Normalization) vs 비정규화(Denormalization)
-
SQL로 구현하는 집계 정보: GROUP BY, JOIN, ROLLUP, CUBE
-
OLAP Cube와 Drill-Down 방식의 정보 탐색
2. 데이터베이스(Database)의 정의와 철학
2-1. 데이터베이스의 개념적 정의
2-1-1. 데이터베이스의 정의와 구성 요소.
-
정의:
- 관련성 있는 데이터의 구조적 집합체. 컴퓨터 시스템 상에 영구적으로 저장되며,
- 효율적으로 검색·관리될 수 있도록 구성됨.
-
구성 요소:
-
데이터: 정형화된 정보
-
메타데이터: 데이터에 대한 설명 (스키마)
-
DBMS: 이를 관리하는 소프트웨어 시스템
-
쿼리 언어(SQL 등): 사용자-시스템 간 인터페이스
-
2-1-2. 파일 시스템과의 비교.
| 항목 | 전통 파일 시스템 | 데이터베이스 |
|---|---|---|
| 중복 제어 | 없음 | 정규화 및 제약 조건 |
| 동시성 제어 | 없음 | 트랜잭션, Lock |
| 검색 | 순차 검색 위주 | 인덱스 기반 |
| 보안 | 제한적 | 인증, 권한, 뷰 |
2-2. 데이터베이스의 존재 이유 및 철학적 기반
2-2-1. 왜 DB인가? (실무 중심 관점)
-
동시 사용자 다수 처리
-
데이터 무결성 보장
-
데이터 중복 제거 및 일관성 유지
-
복잡한 질의(Query) 지원
-
백업 및 복구 등 신뢰성 있는 데이터 관리
2-2-2. 데이터 중심 아키텍처와 철학
-
"모든 것은 데이터다": 이벤트 기반 시스템, 로그 중심 설계
-
현실 세계의 모델링: 고객, 주문, 결제 등 실세계 개체(Entity)를 데이터로 추상화
-
도메인 중심 설계(DDD)와의 연계:
-
도메인 Entity ↔ 테이블 매핑 전략
-
Aggregate와 저장 구조의 일치성 고려
-
2-3. 데이터베이스의 논리적/물리적 구조
2-3-1. 논리적 구조 ( 스키마 )
-
개체(Entity), 속성(Attribute), 관계(Relationship)
-
스키마 정의 언어 (DDL): CREATE TABLE, ALTER TABLE
-
정규화(NF1~NF3, BCNF): 이상 현상 제거, 데이터 중복 방지
2-3-2. 물리적 구조
-
인덱스, 파티셔닝, 클러스터링 등 성능 최적화 구조
-
파일 시스템과의 매핑 (Tablespace, Datafile)
-
디스크 I/O 최적화 설계 (Buffer Pool, Page Cache)
2-4. 데이터베이스의 핵심 속성과 이론.
2-4-1. 트랜잭션과 ACID
-
Atomicity (원자성)
-
Consistency (일관성)
-
Isolation (격리성)
-
Durability (지속성)
- 예시: 은행 송금 처리 시 트랜잭션 보장
2-4-2. 데이터 무결성과 제약조건
-
기본 키(Primary Key), 외래 키(Foreign Key)
-
UNIQUE, NOT NULL, CHECK 제약
-
Referential Integrity (참조 무결성)
2-4-3. 데이터 일관성 보장을 위한 동시성 제어.
-
Lock (Shared, Exclusive)
-
MVCC (MySQL InnoDB의 사례)
-
Isolation Level: Read Uncommitted → Serializable
2-5. 실무에서의 DB 사용 전략 및 설계 철학.
2-5-1. 설계 시 고려사항.
-
요구사항 수집 → ERD → 논리 모델 → 물리 모델
-
서비스 규모에 따른 설계 전략 차이
-
스타트업: 단순한 단일 DB → 빠른 MVP 개발
-
대규모 서비스: 마이크로서비스 기반 DB 분리, CQRS 등 도입
-
2-5-2. 백엔드 개발자와 DBA의 협업 포인트.
-
스키마 설계 권한 분리
-
Query 성능 이슈 진단: EXPLAIN, 인덱스 전략
-
마이그레이션 및 버전 관리 (Flyway, Liquibase)
2-5-3. 데이터 철학이 반영된 실무 사례 예시.
-
주문 처리 시스템에서의 일관성과 트랜잭션 보장
-
실시간 데이터 분석을 위한 구조 (ETL + DWH)
-
이벤트 소싱(Event Sourcing) 기반 아키텍처에서의 DB의 역할
✅ 마무리 요약
-
데이터베이스는 단순한 저장소가 아니라 현실 세계를 구조화된 형태로 지속적이고 일관되게 모델링하는 핵심 시스템이다.
-
백엔드 개발자 혹은 DBA로 성장하려면, 논리적 모델링 → 정규화 → 성능 최적화 → 동시성 제어 → 트랜잭션 처리에 이르는 전 영역에 대한 이해가 필요하다.
-
데이터 철학은 비즈니스 의사결정, 시스템 아키텍처 설계, 장애 복구 및 데이터 전략 수립까지 모두 연결된다.
3. DBMS(Database Management System)란?
3-1. DBMS의 기본 개념 및 탄생 배경
3-1-1. DBMS의 정의.
-
DBMS란?
- 데이터를 효율적으로 저장·관리·검색·갱신할 수 있도록 도와주는 소프트웨어 시스템
-
DBMS의 핵심 기능:
-
CRUD 연산 지원
-
데이터 무결성 보장
-
트랜잭션 처리
-
사용자 관리 및 권한 설정
-
백업 및 복구 기능
-
동시성 및 장애 복구
-
3-1-2. DBMS의 등장 배경.
-
파일 시스템 기반 데이터 관리의 한계
- 중복, 비일관성, 검색 속도 문제
-
데이터 독립성 확보 필요성 대두
-
1970년대 IBM System R 프로젝트 → RDBMS 모델 태동
3-2. DBMS의 구성 요소 및 아키텍처.
3-2-1. DBMS의 내부 구성.
-
DDL 처리기: 스키마 정의 및 변경
-
DML 처리기: INSERT/UPDATE/DELETE/SELECT 실행
-
쿼리 최적화기(Query Optimizer): 실행 계획 생성
-
스토리지 관리자: 데이터 저장 및 디스크 관리
-
버퍼 관리자: 메모리 캐싱 및 I/O 최적화
-
트랜잭션 관리자: ACID 보장
-
로그 관리자: Redo, Undo 로그 관리
3-2-2. DBMS의 계층 구조.
-
SQL 인터페이스
-
파서 / 리라이팅 / 옵티마이저 / 익스큐터
-
스토리지 계층: Table / Index / Log / Buffer Pool
3-3. DBMS의 주요 기능과 동작 방식.
3-3-1. CRUD 처리.
-
SELECT: 인덱스를 통한 효율적 탐색
-
INSERT/UPDATE/DELETE: 로그 기록 + 스토리지 반영
-
View, Materialized View 사용 방식
3-3-2. 트랜잭션 처리와 로그 구조.
-
Undo / Redo 로그 → 장애 복구
-
WAL(Write-Ahead Logging): 쓰기 순서 보장
-
트랜잭션 격리 수준과 현상: Dirty Read, Phantom Read
3-3-3. 병행성 제어.
-
Locking Mechanism: Row-level, Table-level Lock
-
MVCC 방식 (MySQL InnoDB, PostgreSQL 예시)
-
Deadlock 감지 및 회피
3-3-4. 백업과 복구.
-
Point-in-Time Recovery
-
Full / Incremental / Differential 백업
-
클러스터 기반 DB에서의 고가용성 전략
3-4. DBMS의 종류와 비교
3-4-1. RDBMS vs NoSQL vs NewSQL.
| 구분 | RDBMS | NoSQL | NewSQL |
|---|---|---|---|
| 모델 | 관계형 | 문서/키-값/그래프 | 관계형 |
| 스키마 | 고정 | 유동 | 고정 |
| 확장성 | 수직 확장 위주 | 수평 확장 용이 | 수평 확장 |
| 트랜잭션 | ACID | BASE | ACID |
| 예시 | MySQL, PostgreSQL | MongoDB, Redis | CockroachDB, Yugabyte |
3-4-2. 오픈소스 vs 상용 DBMS.
-
오픈소스: MySQL, PostgreSQL, MariaDB
-
상용: Oracle, MS SQL Server, DB2
-
선택 기준: 비용, 성능, 라이선스, 커뮤니티 지원
3-5. 실무에서의 DBMS 선택 및 활용 전략
3-5-1: 프로젝트 규모에 따른 선택 전략
-
스타트업: MySQL, SQLite, PostgreSQL
-
엔터프라이즈: Oracle, MS SQL + 분석 시스템 연계
-
대용량 분산 시스템: NewSQL, Sharding 기반 아키텍처
3-5-2: 성능 최적화 전략
-
쿼리 최적화: 인덱스 설계, JOIN 전략, Subquery 제거
-
Connection Pool, Prepared Statement
-
트랜잭션 분리 및 비동기 처리 전략
3-5-3: 모니터링과 운영
-
Query 분석: EXPLAIN, ANALYZE
-
리소스 추적: IOPS, 메모리 사용량, Lock 대기 시간
-
운영 도구: pgAdmin, Oracle AWR, MySQL Workbench
✅ 마무리 요약.
-
DBMS는 단순한 저장소 관리 시스템이 아닌,
- 고성능 데이터 처리 및 무결성 보장, 동시성 제어, 장애 복구, 보안 정책까지 포괄하는 데이터 처리의 핵심 엔진이다.
-
실무에서 DBMS를 제대로 활용하려면,
- 내부 구성의 작동 원리부터 다양한 트랜잭션 시나리오, 성능 문제 해결 능력까지 갖춰야 한다.
-
데이터베이스는 코드보다 오래 남는다.
- 신중한 DB 설계 및 운영 전략은 프로젝트 전체 생명주기에도 큰 영향을 미친다.
