데이터를 위한 Back_End 공부하기 : Spring Boot에서 flush() 완벽 이해하기.

데이터를 위한 Back_End 공부하기 : Spring Boot에서 flush() 완벽 이해하기.

▽ 데이터를 위한 Back_End 공부하기 : Spring Boot에서 flush() 완벽 이해하기.
목 차
1. JPA의 작동 방식
- 엔티티 상태와 라이프사이클
- 영속 컨텍스트란?
2. flush()란 무엇인가
3. flush()의 동작원리.
4. flush 모드의 종류와 특징
5. flush()를 사용하는 이유,
6. flush() 사용 예제.
- insert
- update
- delete
7. 실무에서 flush() 사용시 주의사항.
8. 결론.
1. JPA의 작동 방식
1-1 엔티티 상태와 라이프사이클.
JPA에서 엔티티는 다음과 같은 4가지 상태를 가집니다.
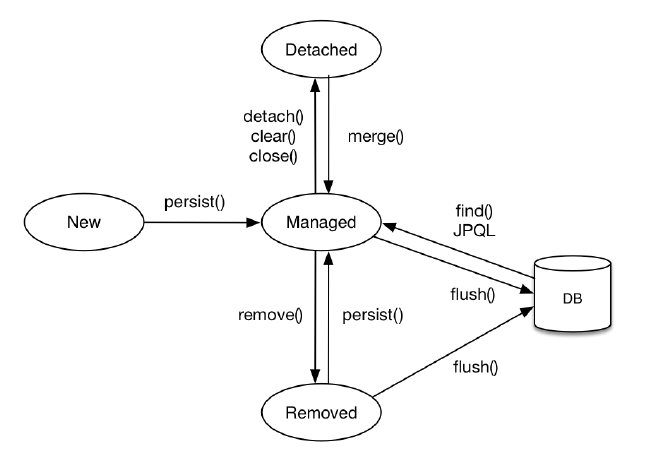
1. 비영속 (Transient):
영속성 컨텍스트와 관계없는 상태로, 단순히 객체만 생성된 상태입니다.
UserEntity user = new UserEntity(); // 비영속 상태
2. 영속 (Managed):
영속성 컨텍스트에 저장된 상태로, 변경 사항이 자동으로 추적됩니다.
entityManager.persist(user); // 영속 상태로 전환
3. 준영속 (Detached):
영속성 컨텍스트에서 분리된 상태로, 더 이상 변경 사항을 추적하지 않습니다.
entityManager.detach(user); // 준영속 상태로 전환
4. 삭제 (Removed):
데이터베이스와 영속성 컨텍스트에서 삭제된 상태입니다.
entityManager.remove(user); // 삭제 상태로 전환
1-2 영속 컨텍스트란?
영속성 컨텍스트(Persistence Context)는 JPA가 엔티티 객체를 관리하기 위해 사용하는 메모리 공간입니다.
이는 일종의 캐시로, 엔티티의 상태를 추적하고 필요할 때 데이터베이스와 동기화합니다.
※ 특징.
-
변경 감지 (Dirty Checking): 엔티티의 변경 사항을 자동으로 추적하여 필요 시 수정 쿼리를 생성합니다.
-
1차 캐시: 동일한 트랜잭션 내에서는 동일한 엔티티 객체를 반환하여 메모리 효율성을 높입니다.
-
쓰기 지연(Write-Behind): SQL 쿼리는 트랜잭션 커밋 시점에 한 번에 실행되어 성능을 최적화합니다.

2. flush()란 무엇인가
flush()는
- 영속성 컨텍스트에 저장된 변경 사항(Insert, Update, Delete 등)을
데이터베이스에 즉시 반영하는 메서드입니다.
. - Hibernate 문서에 따르면,
"Flushing은 메모리에 보관된 영속 상태를 기반 영속 저장소와 동기화하는 프로세스"입니다.
.
JPA에서 flush()는 다음과 같은 역할을 합니다:
-
영속성 컨텍스트의 변경 사항을 데이터베이스에 반영합니다.
-
트랜잭션 커밋 전에 변경 사항을 확인할 수 있게 합니다.
-
쿼리 실행 전에 영속성 컨텍스트와 데이터베이스를 동기화합니다.
3. flush()의 동작원리.
flush() 메서드가 호출되면 다음과 같은 과정이 진행됩니다:
1. 변경 감지(Dirty Checking):
영속성 컨텍스트 내의 모든 엔티티를 스캔하여 변경된 엔티티를 찾습니다.
2. SQL 생성:
변경된 엔티티에 대한 적절한 SQL 쿼리(INSERT, UPDATE, DELETE)를 생성합니다.
3. 쿼리 실행:
생성된 SQL 쿼리를 데이터베이스에 전송하여 실행합니다.
4. 동기화:
영속성 컨텍스트와 데이터베이스 상태를 동기화합니다.
- 중요한 점은 flush()가 트랜잭션을 커밋하지 않는다는 것입니다.
- 트랜잭션은 여전히 유지되며, 이후 롤백이 가능합니다. 이는 flush()와 commit()의 주요 차이점입니다.
4. flush 모드의 종류와 특징
JPA에서는 다음과 같은 flush 모드를 제공합니다:
FlushModeType.AUTO (JPA & Hibernate).
-
JPA 명세에서 기본값으로 설정된 모드로, 다음 두 가지 상황에서 자동으로 flush를 수행합니다:
-
트랜잭션이 커밋되기 전
-
영속성 컨텍스트에 변경 사항이 있는 테이블에 영향을 미치는 쿼리가 실행되기 전
-
-
Hibernate의 AUTO 모드는 JPA와 약간 다르게 동작합니다.
-
Hibernate는 쿼리가 영속성 컨텍스트의 변경 사항에 영향을 받을 가능성이 있는 경우에만
flush를 수행합니다.
예를 들어, 다른 엔티티에 대한 쿼리는 flush를 트리거하지 않을 수 있습니다.
FlushModeType.COMMIT (JPA & Hibernate).
- 이 모드에서는 트랜잭션이 커밋될 때만 flush가 수행됩니다.
쿼리 실행 전에는 자동으로 flush되지 않습니다.
FlushModeType.MANUAL (Hibernate 전용).
- 이 모드에서는 개발자가 명시적으로 flush()를 호출할 때만 flush가 수행됩니다.
5. flush()를 사용하는 이유.
데이터 일관성 유지
- 변경 사항을 즉시 반영하여 이후 실행되는 쿼리가 최신 데이터를 참조하도록 보장합니다.
- 예를 들어, 엔티티를 수정한 후 JPQL 쿼리를 실행하는 경우,
쿼리 결과에 수정 사항이 반영되도록 하려면 flush()가 필요할 수 있습니다.
- 예를 들어, 엔티티를 수정한 후 JPQL 쿼리를 실행하는 경우,
대량 작업 처리
- 대량 데이터를 처리할 때
flush()와 clear()를 사용하여 메모리를 효율적으로 관리하고 성능을 최적화할 수 있습니다.- 영속성 컨텍스트에 너무 많은 엔티티가 누적되면
메모리 사용량이 증가하고 성능이 저하될 수 있습니다.
- 영속성 컨텍스트에 너무 많은 엔티티가 누적되면
제약 조건 검증
- 데이터베이스 제약 조건(예: 고유 키, 외래 키 등)을 확인하려면 변경 사항을 즉시 반영해야 합니다.
- flush()를 호출하면 데이터베이스 제약 조건 위반 여부를 즉시 확인할 수 있습니다.
ID 생성 및 참조
- 자동 생성된 ID 값을 즉시 얻기 위해 flush()를 사용할 수 있습니다.
- 특히 IDENTITY 전략을 사용하지 않는 경우,
엔티티를 저장한 후 생성된 ID 값을 참조하려면 flush()가 필요할 수 있습니다.
6. flush() 사용 예제.
5-1 insert
대량의 데이터를 저장할 때 배치 처리를 통해 성능을 최적화하는 예제.
@Transactional
public void saveUsers(List<UserEntity> users) {
int batchSize = 20;
for (int i = 0; i < users.size(); i++) {
entityManager.persist(users.get(i));
if (i % batchSize == 0) {
entityManager.flush(); // INSERT 쿼리 실행
entityManager.clear(); // 메모리 초기화
}
}
}
이 코드는 20개의 엔티티마다 flush()와 clear()를 호출하여 영속성 컨텍스트의 크기를 제한하고 메모리 사용량을 최적화합니다.
5-2 update
엔티티를 수정한 후 변경 사항을 즉시 데이터베이스에 반영하는 예제.
@Transactional
public void updateUsers(List<UserEntity> users) {
for (UserEntity user : users) {
user.setName("Updated Name");
}
entityManager.flush(); // UPDATE 쿼리 실행
// 이후 쿼리는 업데이트된 데이터를 참조
List<UserEntity> updatedUsers = entityManager.createQuery("SELECT u FROM UserEntity u WHERE u.name = :name", UserEntity.class)
.setParameter("name", "Updated Name")
.getResultList();
}
5-3 delete
엔티티를 삭제한 후 변경 사항을 즉시 데이터베이스에 반영하는 예제.
@Transactional
public void deleteUsers(List<Long> userIds) {
for (Long id : userIds) {
UserEntity user = entityManager.find(UserEntity.class, id);
entityManager.remove(user);
}
entityManager.flush(); // DELETE 쿼리 실행
// 이후 쿼리는 삭제된 데이터를 참조하지 않음
long count = entityManager.createQuery("SELECT COUNT(u) FROM UserEntity u", Long.class)
.getSingleResult();
}
7. 실무에서 flush() 사용시 주의사항.
성능 고려사항
- flush()는 데이터베이스와 직접 상호작용하므로 과도한 호출은 성능 저하를 초래할 수 있습니다.
- 필요한 경우에만 호출하고, 대량 작업 시 적절한 배치 크기를 설정하는 것이 중요합니다.
트랜잭션 관리
- flush()는 트랜잭션 내에서 호출해야 합니다.
- @Transactional 어노테이션을 사용하여 트랜잭션을 관리하면 예외 발생 시 롤백이 가능합니다.
벌크 연산과의 상호작용
- 벌크 연산(예: executeUpdate())은 영속성 컨텍스트를 무시하고 직접 데이터베이스에 쿼리를 실행합니다.
- 이로 인해 영속성 컨텍스트와 데이터베이스 간의 불일치가 발생할 수 있습니다.
- 벌크 연산 후에는 영속성 컨텍스트를 초기화하는 것이 좋습니다.
@Modifying 애노테이션 활용
- Spring Data JPA에서 벌크 연산을 수행할 때는 @Modifying 애노테이션을 사용합니다.
- 이 애노테이션에는 clearAutomatically 옵션이 있어,
쿼리 실행 후 영속성 컨텍스트를 자동으로 초기화할 수 있습니다.
@Modifying(clearAutomatically = true)
@Query("UPDATE UserEntity u SET u.name = :name WHERE u.id = :id")
int updateUserName(@Param("id") Long id, @Param("name") String name);
SQL 쿼리 확인
- Spring Boot 설정으로 JPA가 생성하는 SQL 쿼리를 확인하여,
flush()가 예상대로 동작하는지 검증할 수 있습니다.
spring.jpa.show-sql=true
spring.jpa.properties.hibernate.format_sql=true
8. 결론.
flush()는 JPA에서 영속성 컨텍스트와 데이터베이스 간의 동기화를 관리하는 중요한 메커니즘입니다.
- 이를 통해 데이터 일관성을 유지하고, 대량 작업 시 성능을 최적화하며,
실시간 데이터 검증이 가능합니다.
하지만 flush()는 신중하게 사용해야 합니다.
과도한 호출은 성능 저하를 초래할 수 있으며, 트랜잭션 관리와 벌크 연산과의 상호작용에 주의해야 합니다.
실무에서는 대부분의 경우 JPA의 기본 동작(AUTO 모드)에 의존하는 것이 좋습니다.
그러나 특정 상황(예: 대량 데이터 처리, ID 생성 및 참조, 제약 조건 검증)에서는 명시적인 flush() 호출이 필요할 수 있습니다.
결국, flush()는 JPA의 강력한 기능 중 하나이지만,
그 동작 원리와 영향을 이해하고 적절한 상황에서 사용하는 것이 중요합니다.
