1 캐시 성능 비교
현재 실무에서 많이 느낀건 서비스의 특수성이라는 영향도 있지만 응답속도가 너무 느렸다.
분명히 Redis의 Cache를 사용하고 있는데 왜 이렇게 느릴까라는 생각을 했고
그 이유를 조금이라도 더 알아 보고 다양한 Cache 중 대표적인 Caffeine과 Redis그리고 캐시를 사용하지 않는 환경까지 3개를 비교해 어느 상황에 사용하면 좋을지 정리하고자 기록을 남기고자 한다.
2 Cache란
자주 사용하는 데이터나 값을 미리 복사해 놓는 임시 장소이다.
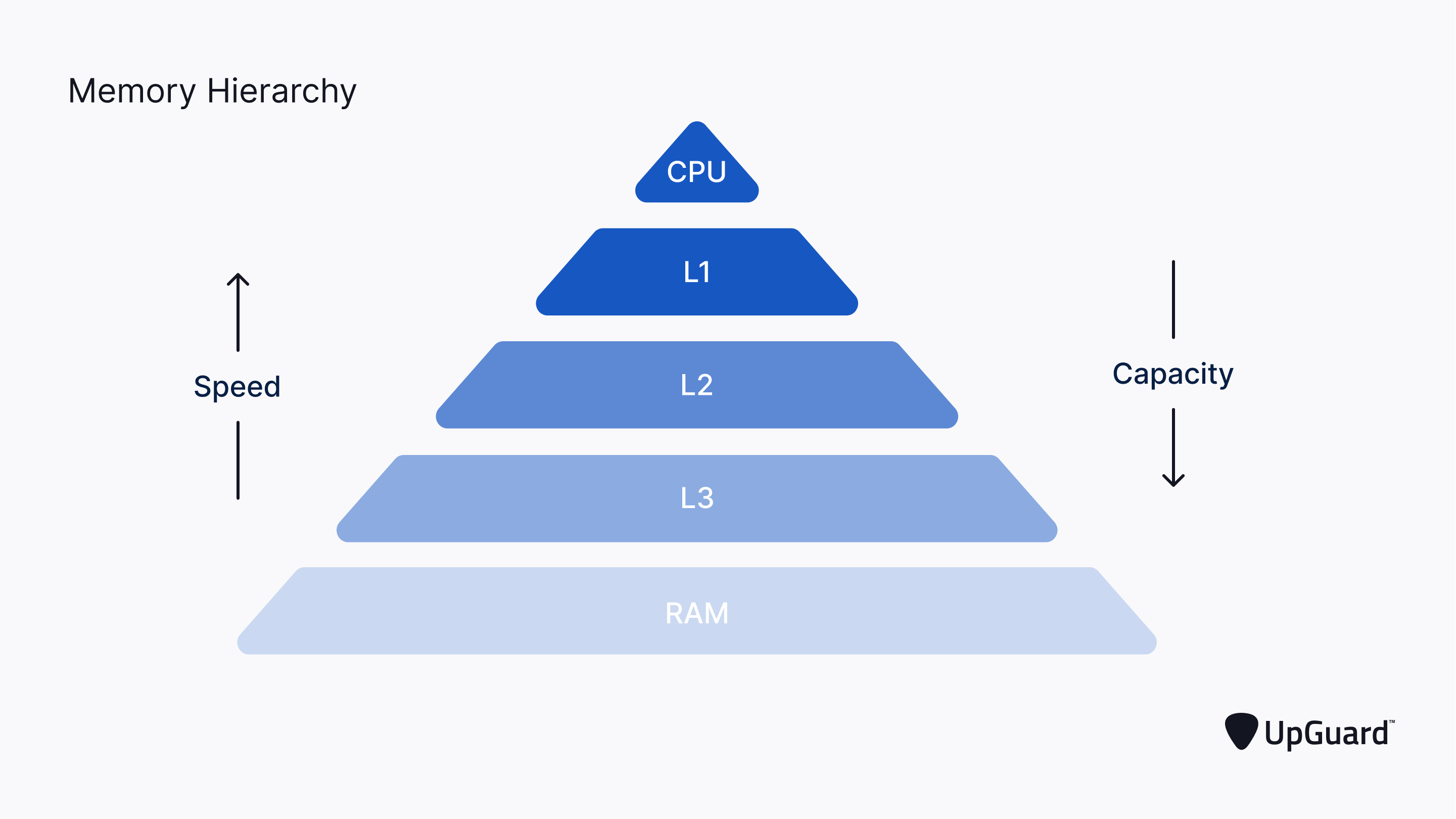
출처 : https://www.upguard.com/blog/cache
위의 이미지의 저장공간 계층 구조에서 확인할 수 있듯이, 캐시는 저장 공간이 작고 비용이 비싼 대신 빠른 성능을 제공한다.
그렇다면 다음과 같은 상황에서 캐시를 활용하는 것이 가장 가성비가 좋다는 의미이다.
- 값이 자주 바뀌지 않고 자주 호출되는 값인지
- DB를 통해 조회해서 가져오는 응답 시간이 오래 걸리는지
값이 자주 바뀌지 않고 자주 호출되는 값은 왜 캐시를 활용하면 좋을까.
위의 상황은 결국 동일한 결과에 대해 동일한 연산이 자주 발생된다는 의미이다.
어차피 결과가 동일하기 때문에 캐시에 저장해두면, 굳이 연산을 하지 않고 해당 결과를 바로 반환하면 되기 때문이다.
DB를 통해 조회해서 가져오는 응답 시간이 오래 걸리는 상황에선 왜 캐시를 활용하면 좋을까.
응답 속도의 문제이다. 응답 속도는 여러 원인으로 인해 느려질 수 있다.
대표적으로는 외부 시스템 호출 비용이 클 때와 트래픽이 급증하는 경우가 있다.
외부 시스템 호출 비용이 크면 네트워크 왕복, 디스크 I/O, 쿼리 파싱 등 여러 단계를 거치기 때문에 수십~수백 ms씩 걸리는 반면 캐시를 통해 읽는다면 1ms 이하로도 줄일 수 있기 때문이다.
즉, 병목이 발생할 수 있는 구간을 건너뛰기가 가능하기에 캐시를 활용하는 방법을 도입할 수 있다.
트래픽이 급증하는 경우도 동일하다. 트래픽이 급증하는 상황에서 모든 요청이 백엔드에 쏟아지는 경우 과부하나 장애로 이어지기도 한다. 이 때 캐시를 통해 트래픽을 제일 앞단에서 처리하도록 한다면 백엔드에게 쏟아지는 부하를 크게 줄일 수 있다.
3 Cache의 종류
캐시의 종류는 다양한다. Caffeine, Redis뿐만 아니라 CDN 캐시, 브라우저 캐시 등등 다양하지만 이번에는 백엔드에서 자주 활용되는 캐시 중 Caffeine과 Redis에 대해서만 기록하고자 한다.
3-1 Caffeine 캐시
Caffeine 캐시는 JVM 힙 메모리 안에 데이터를 저장하는 Java 전용 캐시 라이브러리이다.
3-1-1 동작 방식
애플리케이션 프로세스 내부 메모리에 직접 저장한다. 네트워크 없이 메모리 주소 참조만으로 데이터를 읽어오기 때문에 속도가 극도로 빠르다.
3-1-2 장점
- 속도가 가장 빠름 : 네트워크 I/O가 전혀 없어 나노초~마이크로초 단위 응답
- 설정이 간단 : 의존성 추가 후 코드 몇 줄로 바로 사용 가능
- 자동 메모리 관리 : W-TinyLFU 알고리즘으로 히트율이 높은 데이터를 자동으로 유지
- 별도 인프라 불필요 : Redis 서버 없이 앱 단독으로 동작
3-1-3 단점
- 서버 간 데이터 공유 불가 : 인스턴스가 2대이면 캐시가 2개로 분리되어 일관성이 깨짐
- 앱 재시작 시 데이터 소멸 : 휘발성이라 영속성 없음
- 메모리 제약 : JVM 힙을 공유하므로 저장 용량이 제한적
- Java/JVM 전용 : 다른 언어 서버와 공유 불가
3-2 Redis 캐시
Redis 캐시는 네트워크로 접근하는 형태로 외부 독립적인 인메모리 데이터 저장소이다.
3-2-1 동작 방식
별도 Redis 서버에 데이터를 저장하고, 애플리케이션은 네트워크(TCP)를 통해 읽고 쓴다. 여러 서버가 같은 Redis를 바라보기 때문에 데이터가 공유된다.
3-2-2 장점
- 서버 간 캐시 공유 : 여러 인스턴스가 동일한 데이터를 바라봄 (일관성 보장)
- 다양한 자료구조 지원 : String, Hash, List, Set, Sorted Set, Pub/Sub 등
- 영속성 옵션 : RDB/AOF로 디스크에 저장 가능, 재시작 후 복구 가능
- 대용량 저장 가능 : 서버 메모리 한도까지 자유롭게 확장
- 언어 무관 : Node.js, Python, Go 등 어떤 스택이든 사용 가능
3-2-3 단점
- 네트워크 레이턴시 존재 : 아무리 빨라도 0.5~1ms 이상 소요
- 인프라 관리 필요 : 별도 서버 운영, 장애 대응, 모니터링 필요
- 비용 발생 : 클라우드 사용 시 인스턴스 비용 추가
- 단일 장애점 위험 : Redis 서버 다운 시 전체 캐시 영향 (Cluster/Sentinel로 완화 가능)
3-3 장단점 비교
| 항목 | Caffeine | Redis |
|---|---|---|
| 저장 위치 | JVM 힙 내부 (로컬) | 외부 독립 서버 |
| 응답 속도 | ✅ 나노초~마이크로초 (네트워크 없음) | ⚠️ 0.5~수 ms (네트워크 경유) |
| 서버 간 공유 | ❌ 인스턴스마다 캐시가 분리됨 | ✅ 모든 서버가 동일 캐시 공유 |
| 데이터 일관성 | ❌ 다중 서버 환경에서 불일치 가능 | ✅ 단일 저장소로 일관성 보장 |
| 영속성 | ❌ 앱 재시작 시 데이터 소멸 | ✅ RDB/AOF로 디스크 저장 가능 |
| 저장 용량 | ⚠️ JVM 힙 크기에 제한됨 | ✅ 서버 메모리 한도까지 확장 가능 |
| 자료구조 | Key-Value만 지원 | ✅ String, Hash, List, Set, Sorted Set 등 |
| 만료 정책 | TTL, 최대 크기, 참조 기반 제거 | TTL, LRU, LFU, 수동 삭제 등 |
| 인프라 구성 | ✅ 별도 서버 불필요 | ❌ Redis 서버 별도 운영 필요 |
| 설정 복잡도 | ✅ 의존성 추가 후 코드 몇 줄로 완성 | ⚠️ 서버 설치, 연결 설정, 운영 필요 |
| 운영 비용 | ✅ 추가 비용 없음 | ❌ 서버 운영 또는 클라우드 비용 발생 |
| 장애 영향 | ✅ 앱과 생사를 같이 함 (별도 장애 없음) | ❌ Redis 다운 시 캐시 전체 영향 |
| 고가용성 | 해당 없음 | Sentinel / Cluster로 구성 가능 |
| 언어 지원 | ❌ Java / JVM 전용 | ✅ 언어 무관 (Node, Python, Go 등) |
| Pub/Sub 지원 | ❌ | ✅ 메시지 브로커 역할도 가능 |
| 모니터링 | ⚠️ 제한적 (JMX, Micrometer 등) | ✅ Redis CLI, RedisInsight 등 풍부한 도구 |
4 캐시 밴치마크 실습
4-1 기술 스택
4-1-1 언어 & 프레임워크
| 기술 | 버전 | 용도 |
|---|---|---|
| Java | 17 | 메인 언어 |
| Spring Boot | 4.0.5 | 애플리케이션 프레임워크 |
| Spring Web MVC | (Boot 관리) | REST API (GET /*/products/{id}) |
| Spring Data JPA | (Boot 관리) | ORM / DB 접근 레이어 |
| Spring Cache | (Boot 관리) | 캐시 추상화 인프라 |
| Spring Session Data Redis | (Boot 관리) | Redis 연결 및 세션 관리 |
4-1-2 캐시
| 기술 | 버전 | 역할 |
|---|---|---|
| Caffeine | 3.1.8 | L1 로컬 인메모리 캐시 (JVM 힙) |
| Redis | 7-alpine | L2 분산 캐시 (외부 프로세스, TCP) |
| NoCacheStrategy | — | 베이스라인 (캐시 없음, 매 요청 DB 조회) |
캐시 전략은 CacheStrategy 인터페이스로 추상화하고, ProductController에서 @Qualifier로
3종을 동시 활성화하여 엔드포인트 경로(/caffeine/, /redis/, /nocache/)로 분기.
4-1-3 데이터베이스
| 기술 | 버전 | 용도 |
|---|---|---|
| H2 | (Boot 관리) | 인메모리 DB (개발/테스트 전용) |
| Hibernate | (Boot 관리) | JPA 구현체 |
4-1-4 직렬화
| 기술 | 버전 | 용도 |
|---|---|---|
| Jackson Databind | (Boot 관리) | Redis 저장 시 Product → JSON 직렬화 |
Redis 직렬화는 deprecated된 GenericJackson2JsonRedisSerializer 대신
ObjectMapper를 직접 사용하는 커스텀 RedisSerializer<Product> 구현.
4-1-5 모니터링 & 운영
| 기술 | 버전 | 용도 |
|---|---|---|
| Spring Actuator | (Boot 관리) | /actuator/metrics, /actuator/health 등 엔드 포인트 노출 |
| Micrometer | (Boot 관리) | 메트릭 수집 추상화 레이어 |
| Micrometer Prometheus Registry | (Boot 관리) | Actuator 메트릭 → Prometheus 포맷 변환 |
| Prometheus | latest | 시계열 메트릭 저장 |
4-1-6 부하 테스트
| 기술 | 버전 | 용도 |
|---|---|---|
| k6 | 1.7.1 | 부하 생성 + JSON 리포트 출력 |
| Python 3 | 3.8.6 | k6 JSON 파싱 후 CSV/콘솔 출력 (parse_results.py) |
k6 스크립트는 warmup + load 6개 시나리오(전략별 각 2개)를 단일 실행으로 순차 처리.
4-1-7 인프라 & 컨테이너
| 기술 | 용도 |
|---|---|
| Docker | Redis, Prometheus, Grafana 컨테이너 실행 |
| Docker Compose | 인프라 서비스 일괄 관리 (redis, prometheus) |
4-1-8 개발 도구
| 기술 | 버전 | 용도 |
|---|---|---|
| Gradle | 9.4.1 | 빌드 도구 |
| Lombok | (Boot 관리) | 보일러플레이트 코드 생성 (@Getter,@RequiredArgsConstructor 등) |
| Spring DevTools | (Boot 관리) | 개발 중 핫 리로드 |
| Testcontainers | (Boot 관리) | 테스트 시 Redis 컨테이너 자동 기동 |
| JUnit 5 | (Boot 관리) | 단위 / 통합 테스트 |
4-1-9 설계 패턴
| 패턴 | 적용 위치 | 내용 |
|---|---|---|
| Strategy Pattern | CacheStrategy 인터페이스 | 캐시 구현체 교체 가능하도록 추상화 |
| Qualifier Injection | ProductController | @Qualifier로 3종 전략 빈을 동시 주입 |
| Command Pattern | DataSeeder | 앱 시작 시 10만 건 자동 시딩 (CommandLineRunner) |
5 핵심 로직
5-1 Strategy 추상화 및 구현화
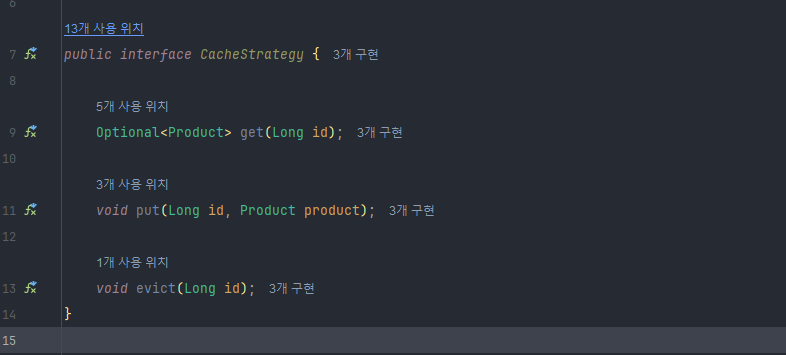
-
get : 캐시에 저장된 데이터 조회
-
put : 데이터 캐싱
-
evict : id를 통해 캐시에서 데이터 삭제
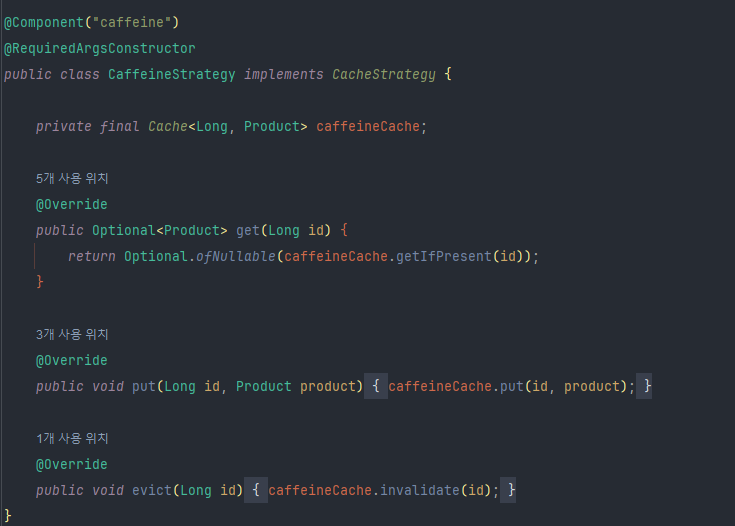
5-1-1 CaffeineStrategy
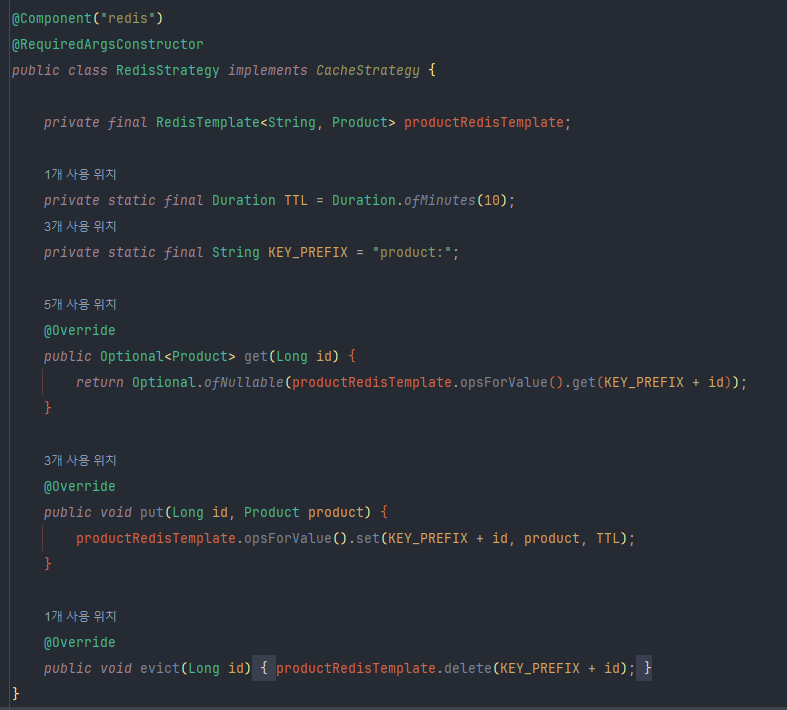
5-1-2 RedisStrategy
5-1-3 NoCacheStratey
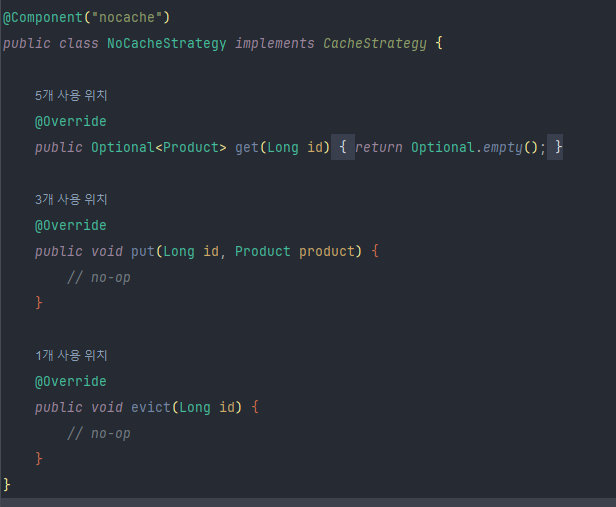
어느 동작도 하지 않지만, 컨트롤러의 각 API가 동일patch 메서드를 호출하기 때문에
작성하였고 get메서드에 의해 EMPTY의 데이터가 반환되어 DB에 직접 조회하도록 유도
5-2 Controller & Service
5-2-1 Controller
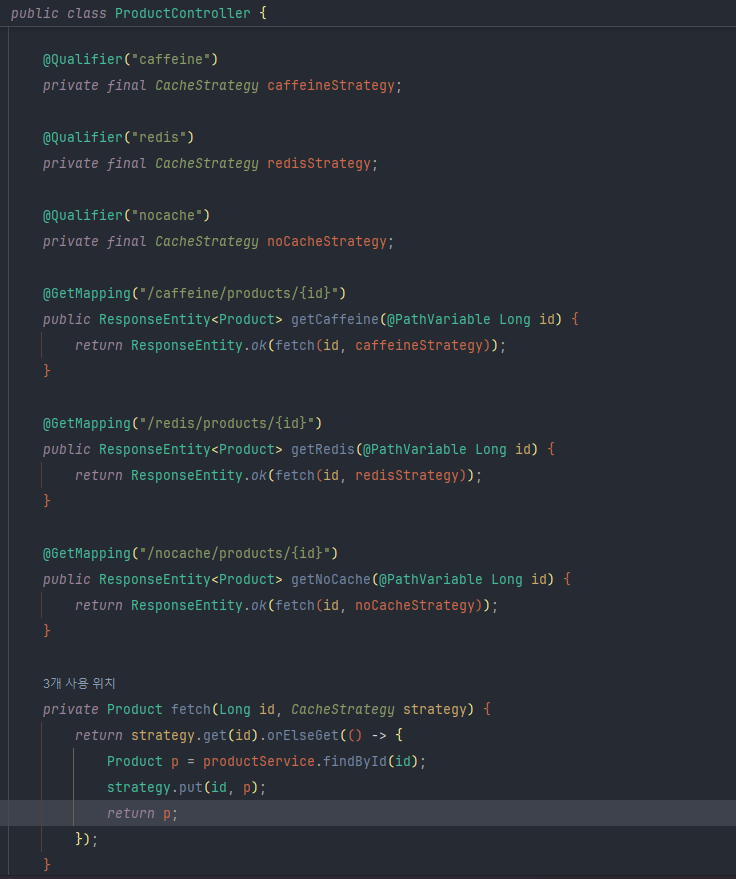
@Qualifer 어노테이션을 통해 3종 전략 빈을 동시 주입하고, 각 API는 patch 메서드를 호출
patch 메서드에서는 strategy를 통해 값을 조회하고 없다면 service를 통해 DB조회한 결과를 반환.
마지막으로 strategy.put 메서드로 캐싱
5-2-2 Service
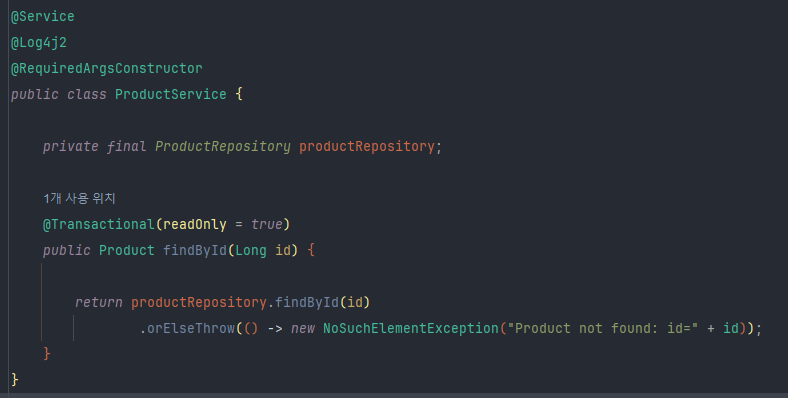
Service의 경우 DB 조회에 대한 로직만 필요하므로 최소환의 비즈니스 로직만 작성
6 테스트
6-1 테스트 방법
테스트는 2가지를 준비했다. 첫 번째로는 Postman을 통한 API 직접 호출
두 번째는 K6를 활용한 부하 테스트를 통한 캐시 성능 밴치마크
6-2 API 호출 테스트
복잡한 비즈니스 로직이 없어 API 호출을 하는 것만으로는 성능을 확인하기 어렵기 때문에 Service 로직에서 반복문을 추가해 반환 속도를 의도적으로 늦춰서 실행한다.
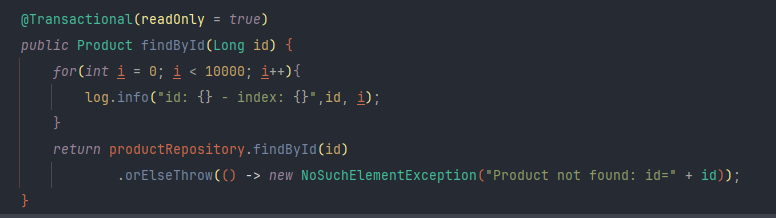
6-2-1 No-Cache
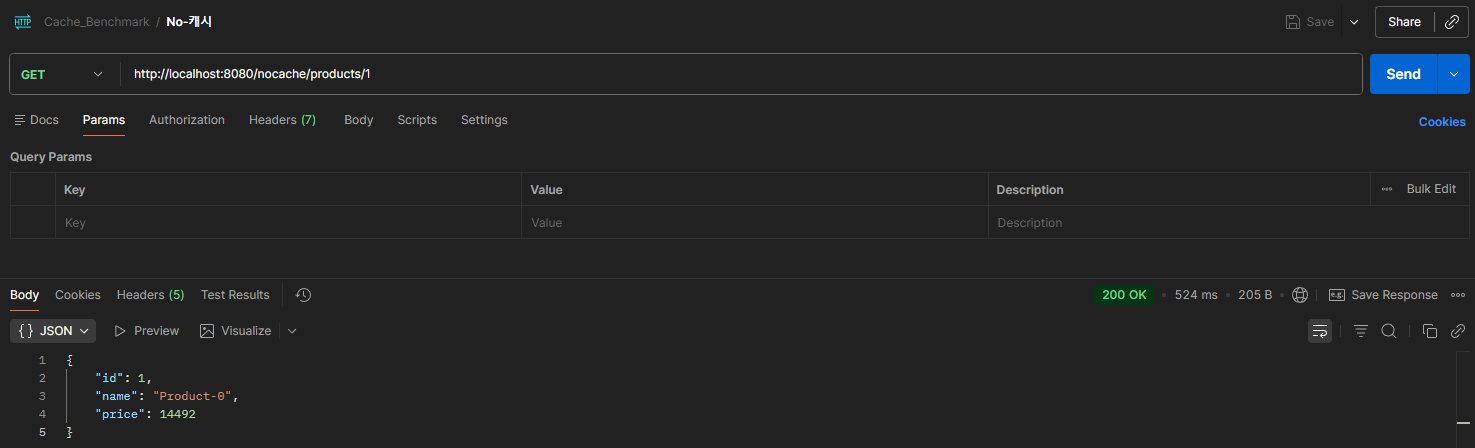
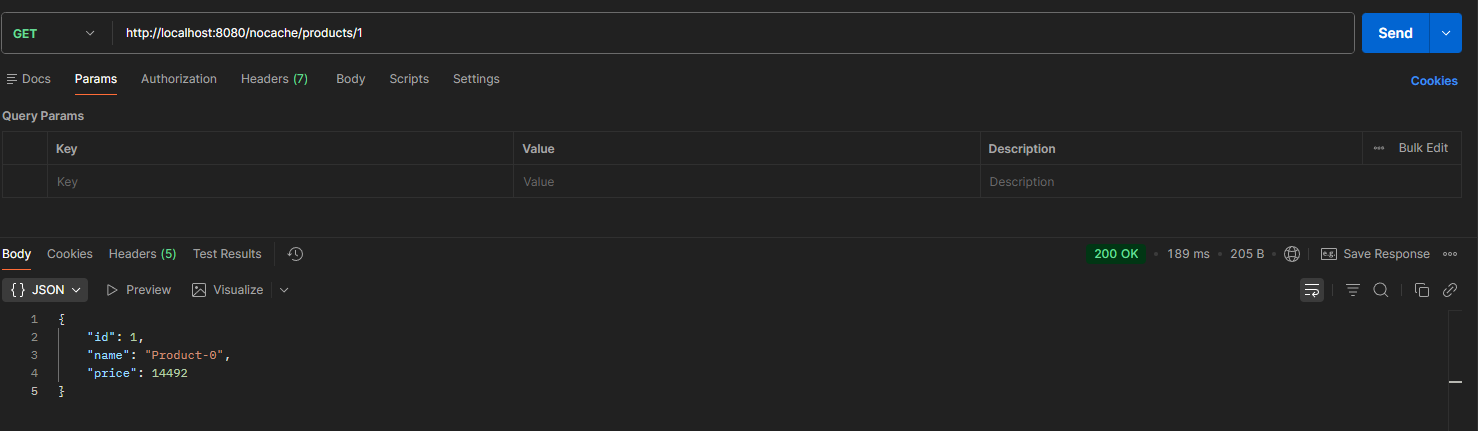
No-Cache의 경우 524ms와 189ms라는 비교적 늦은 응답속도를 확인할 수 있다.
6-2-2 Caffeine
-
Cache Miss
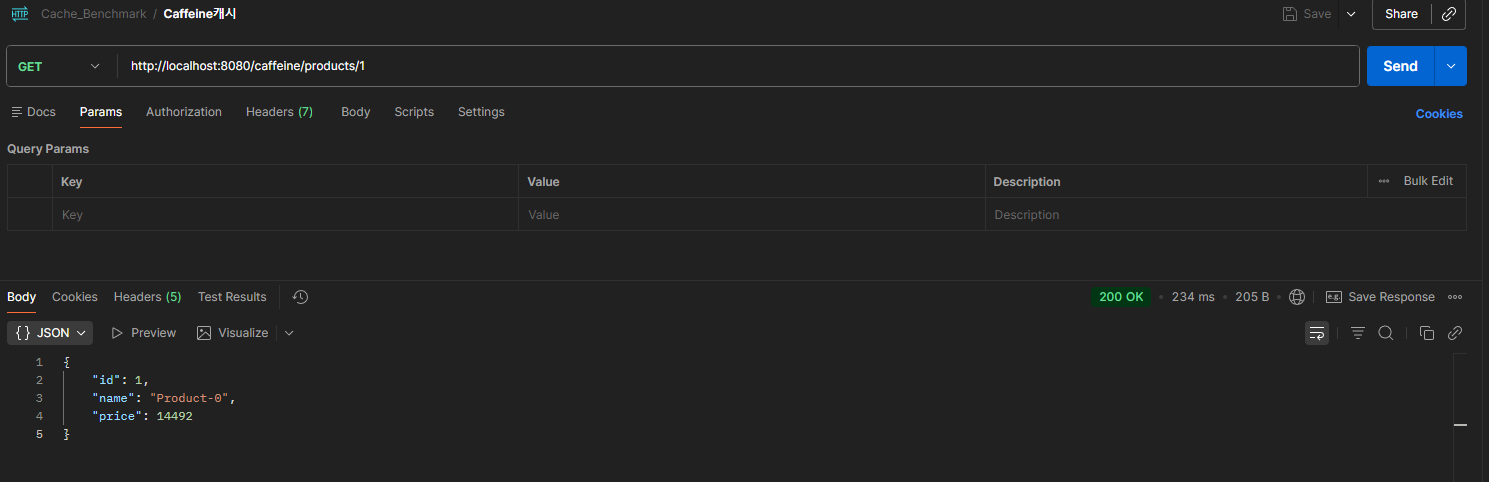
-
Cache Hit
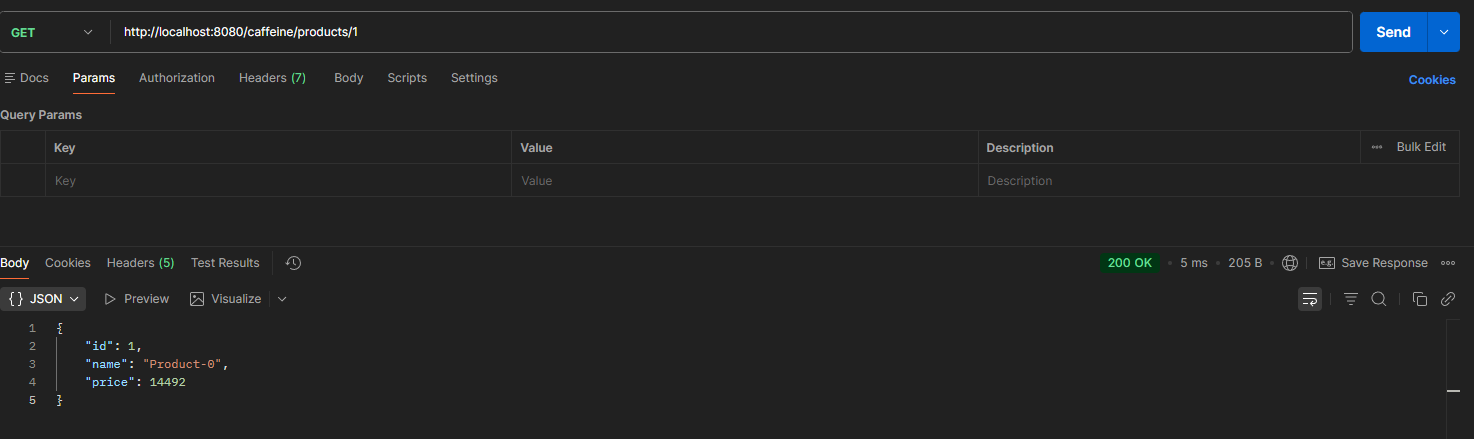
Caffeine의 경우 Cache Miss에서는 234ms를 보여주지만 Cache Hit일 때는 5ms라는 빠른 응답 속도를 나타낸다.
6-2-3 Redis
- Cache Miss
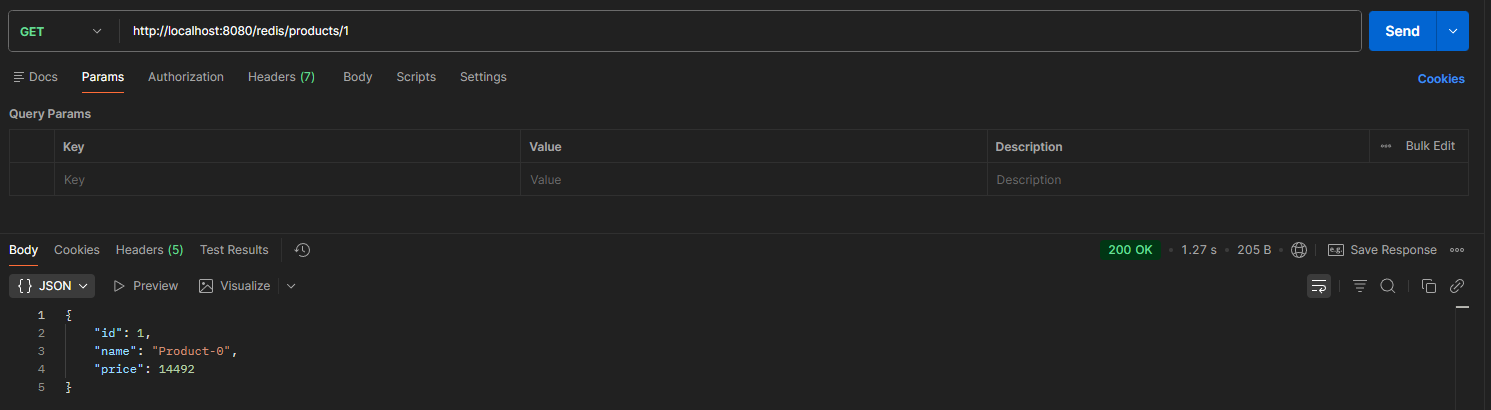
- Cache Hit
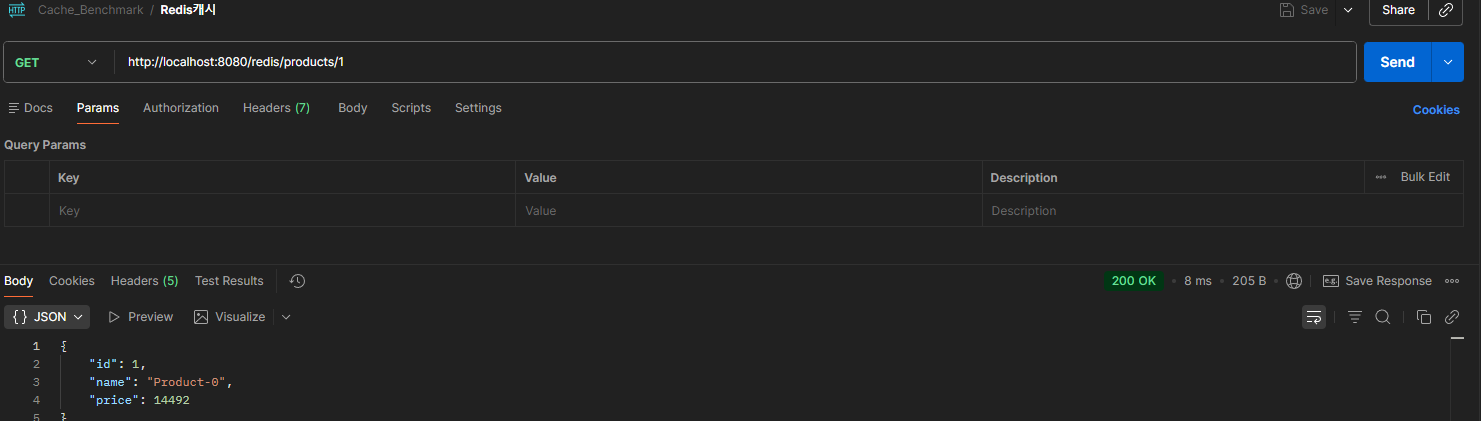
Redis의 경우도 1.27s에서 8ms로 응답 속도가 매우 빠르게 향상된 것을 확인할 수 있었다.
7 부하 테스트
7-1 K6의 부하테스트 목적
동일한 애플리케이션 인스턴스에서 캐시 전략 3종을 공정한 조건 아래 비교하여, 전략 선택이 성능에 미치는 영향을 수치로 증명하는 것이 목표였다.
7-1-1 측정 지표
TPS — 초당 처리 요청 수 (전략 간 처리량 비교)
p50 — 전체 요청의 중간값 응답시간
p95 — 상위 5% 느린 요청의 응답시간 (서비스 안정성 기준)
p99 — 최악 케이스 응답시간
error_rate — 비정상 응답 비율 (목표 < 1%)
7-1-2 시나리오 설계
| 구간 | vus | 시간 | 목적 |
|---|---|---|---|
| warmup | 10 | 30s | 캐시 초기 적재 + JVM 워밍업 |
| load | 100 | 60s | 실제 부하 조건에서 전략 간 비교 |
7-2 K6 부하테스트 결과
7-2-1 Load 시나리오 기준 (vus=100, 60s)
| 전략 | 총 요청 | TPS | avg | p50 | p95 | p99 | max | 에러 |
|---|---|---|---|---|---|---|---|---|
| Caffeine | 58,713 | 978.5 | 1.6ms | 1.2ms | 3.5ms | 7.0ms | 37.0ms | 0 |
| No-Cache | 57,978 | 966.3 | 2.3ms | 1.6ms | 6.6ms | 17.1ms | 46.2ms | 0 |
| Redis | 56,441 | 940.7 | 5.8ms | 4.2ms | 15.3ms | 24.4ms | 108.2ms | 0 |
7-2-2 서버 처리 시간 TTFB — http_req_waiting (Load 기준)
| 전략 | avg | p50 | p95 | p99 |
|---|---|---|---|---|
| Caffeine | 1.3ms | 1.1ms | 2.9ms | 5.2ms |
| No-Cache | 1.7ms | 1.2ms | 4.0ms | 12.3ms |
| Redis | 5.5ms | 4.0ms | 14.8ms | 23.7ms |
7-2-3 결론
-
Caffeine이 가장 빠름
p50 기준 1.2ms로 3종 중 가장 빠르다. JVM 힙에서 직접 반환하므로 네트워크 비용이 전혀 없다. p99도 7.0ms로 안정적.
-
NoCache가 Redis보다 빠르게 나왔다 — H2 인메모리 특성
NoCacheStrategy(p50 1.6ms)가 Redis(p50 4.2ms)보다 빠른 것은 이상해 보이지만, 사용 중인 DB가 H2 인메모리이기 때문이다. H2는 프로세스 내부 메모리에서 직접 조회하므로 TCP 통신이 없다. PostgreSQL 같은 외부 DB를 사용했다면 순위가 달라졌을 것이다.
-
Redis가 가장 느리게 나왔다 — TCP + 직렬화 비용
p50 4.2ms, p95 15.3ms로 Caffeine의 3~4배 수준. TTFB 기준 avg 5.5ms는 전부 네트워크 RTT + JSON 직렬화/역직렬화 오버헤드로 보인다.
-
TPS는 셋 다 비슷 — 병목이 캐시가 아님
TPS가 940~978로 거의 동일한 이유는 k6 스크립트의 sleep(0.1) 때문이다. vus 100 × (1/0.1) = 최대 1,000 TPS가 이론적 상한이며, 실제 수치가 이에 근접하고 있다. 즉 현재 병목은 캐시가 아닌 k6의 요청 간격이다.
-
에러율 0% — 안정성 확인
H2를 사용했기에 원했던 결과와 차이가 나지만 그래도 어떠한 상황에서 어떠한 기술 스택을 사용하면 좀 더 좋을 수 있을지 알게되었다고 생각한다.
GitHub
