들어가기에 앞서..
실무에서 특정 테이블에 있는 레코드를 읽어와 재가공해 이력 테이블로 삽입하는 업무를 맡아 Batch를 활용해 처리한 경험이 있습니다.
하지만 당시에는 빠르게 처리하는 것만 생각해서 Batch 구조와 원리에 대해 신경을 쓰지 않았습니다..
이제라도 Batch에 대해 공부하고 기록을 남기고자 합니다.
1. Spring Batch란

위의 첨부내용처럼 Batch는 일괄 처리 라는 단어적 의미를 갖고 있다.
Spring Batch는 Batch Processing을 기반으로 로깅, 추적, 트랜잭션 관리, 작업 처리 통계, 작업 재시작, 건너뛰기, 리소스 관리를 포함하여 대량의 레코드를 처리하는 데 필수적인 재사용 가능한 기능을 제공한다. (출처 : https://spring.io/projects/spring-batch)
2. Spring Batch 구조

Flow를 확인해보면 Job Scheduler에서 지정된 일정에 맞춰 JobLauncher를 실행한다. JobLauncher에서는 Job을 실행시키고 Job에서는 Step을 실행한다.
Step은 Tasklet과 Chunk기반으로 이루어져 있다. (위의 Flow는 Chunk기반이다.)
Read ~ Write의 처리가 완료된 이후 다음 Step이 있다면 작업을 시작하고 없는 경우 Batch 작업을 종료한다.
2-1. Job
배치 처리 과정을 담은 하나의 단위로 즉, 배치 작업 자체를 의미한다.
Job에는 1개 이상의 Step이 포함되어야 한다.
구현체로써는 SimpleJob과 FlowJob 등이 제공된다.
2-1-1. JobLauncher
- Job과 JobParameter를 사용해 Job을 실행시키는 객체.
- Batch 처리를 완료한 후 Client에 JobExecution을 리턴한다. (비동기도 가능)

2-1-2. JobInstance
- Job의 논리적 실행 단위 객체로 고유하게 식별 가능한 작업 실행.
- Job Name, Job Parameter 조합으로 인스턴스를 생성
- 동일한 Job Name, Job Parameter의 조합은 단 1개의 인스턴스만 생성 가능
- Job : JobInstance는 1:N의 관계
2-1-3. JobParameters
- Job 실행 시 사용되는 Parameter
- 여러 개의 JobInstance를 구분하기 위한 용도이다.
- JobParameters : JobInstance는 1:1의 관계

2-1-4. JobExecution
- JobInstance의 실행 시도 객체
- JobInstance의 실행 상태, 시작 및 종료, 생성 시간 등 정보를 저장
- ExitStatus가 FAILED일 경우 재실행 가능, COMPLITED인 경우 재실행 불가
- JobInstance : JobExecution은 1:N의 관계
2-1-5. JobRepository
- 모든 Batch 정보를 가지고 있는 메타 데이터 저장소
- Job이 실행되면 JobRepository에 JobExecution과 StepExecution을 생성한다.
- 이후 JobRepository에서 Execution의 정보들을 DB에 저장 및 조회해 사용한다.
Job에 대한 자세한 내용은 아래 블로그를 참조하면 좋을 듯합니다.
https://hoestory.tistory.com/40
2-2. Execution Context
- Framework에서 Execution의 상태를 저장하고 공유하는 객체
- Job의 재시작 시 이미 처리된 데이터는 스킵하고 이후 수행할 때 상태 정보를 활용한다.
- 종류로는 JobExecution과 StepExcution이 있다.
- JobExecution : 각 Job에 생성되고 Job간의 공유는 불가능하다. 단, Job내부의 Step간의 공유는 가능하다.
- StepExcution : 각 Step에 생성되고 Step간의 공유는 불가능하다.
2-3. StepExecution
- Step의 실행 시도 객체
- Step별로 StepExecution이 생성된다.
- JobExecution에 저장되는 정보 외에 Read, Write, Commit 수 등의 정보가 저장된다.
- Job이 재시작 되더라도 이미 성공한 Step은 스킵, 실패한 Step만 실행된다.
- Step의 StepExecution이 하나라도 실패한다면 JobExecution은 실패 처리가 된다.
2-4. Step
- Batch Job을 구성하는 하나의 실행 단위
- 하나의 Job은 여러 개의 Step으로 구성될 수 있다.
- Step은 Reader, Processor, Writer로 구성되어 있다.
- StepExecution을 통해 실행 상태 및 결과를 관리한다.
- 구현체로는 다음과 같다.
- TaskletStep : 가장 기본이 되는 클래스. Tasklet 타입이 구현체를 제어
- PartitionStep : 멀티 스레드 방식으로 Step을 여러 개 분리해서 실행
- JobStep : Step 내에서 Job을 실행
- FlowStep : Flow를 실행하는 Step
2-4-1 Tasklet
- Tasklet기반 Step은 Batch의 Step단계에서 단일 Task를 수행한다.
- TaskletStep에 의해 반복 실행되며 반환 값에 따라 실행 및 종료된다.
- RepeatStatus.CONTINUABLE : 반복
- RepeatStatus.FINISHED : 종료
- 단일 Task를 수행하기 때문에 Step과 Tasklet은 1:1의 관계를 가진다.
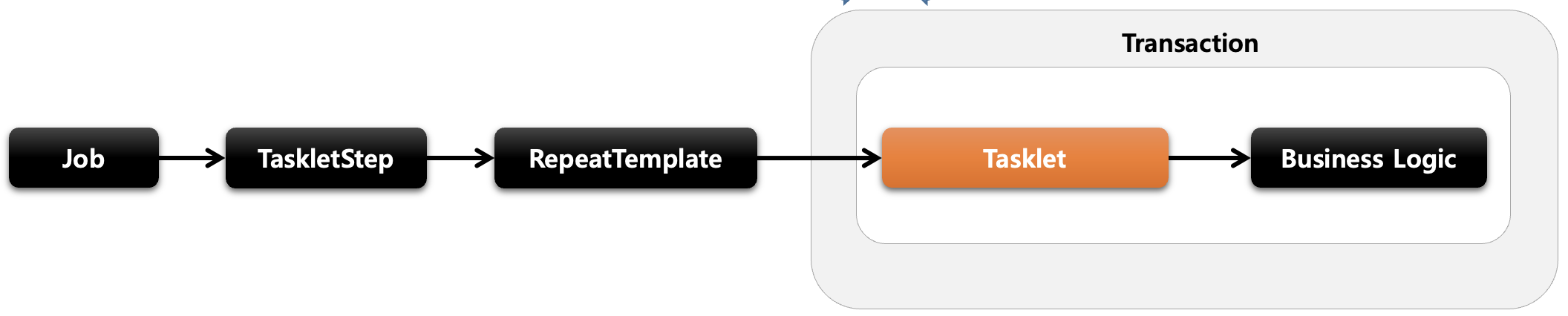
2-4-2 Chunk
- Chunk기반 Step은 Batch의 Step단계에서 처리할 레코드(한 덩어리)를 n개씩 나눠 수행한다.
- ItemReader, ItemProcessor, ItemWriter를 사용하며, ChunkOrientedTasklet가 제공된다.

2-4-2-1. ItemReader
ItemReader는 Chunk기반에서 처리할 데이터를 읽어오는 Interface이다.
구현체로는 다음과 같다.
- JDBC
- Cursor : JdbcCursorItemReader
- Paging : JdbcPagingItemReader
- JPA
- Cursor : JpaCursorItemReader
- Paging : JpaPagingItemReader
- Txt, CSV 등 : FlatFileItemReader
- Json : JsonItemReader
- 복수의 파일 조합 : MultiResourceItemReader
- Thread : SynchronizeditemStreamReader
- Custom : CustomItemReader
위의 JDBC와 JAP에서 Cursor와 Paging은 데이터를 조회하는 방식이다.
- Cursor
- 현재 행에 Cursor를 유지하며 다음 데이터를 호출할 시, 다음 행으로 Cursor를 이동하며 데이터 반환을 이루는 형태의 Streaming I/O
- DB Connection이 연결되면 Batch가 완료될 때까지 데이터를 읽어온다.
- 따라서, DB Connection과 메모리가 충분해야 한다는 제한이 있다.
- Thread-safe하지 않다.
- Paging
- 페이지 단위로 데이터를 조회하는 방식이며, Page Size만큼 한번에 데이터를 가지고 온다.
- 한 페이지를 읽을 때마다 DB Connection을 맺고 끊음
- Cursor와 다르게 페이지 단위로 가져오기 때문에 메모리 사용량이 적다는 이점이 있다.
- 다만, 데이터 정렬이 되어 있어야 문제 없이 사용할 수 있다.
- Thread-safe하다.
정리한 걸 보았을 때는 Cursor보다 Paging방법이 여러모로 장점이 많아보인다.
하지만, DB Connection과 메모리가 충분하다면 Paging보다 Cursor방식이 더 빠르기도 한다.

2-4-2-2. ItemProcessor
ItemProccessor는 Chunk 단위로 읽어온 데이터를 필요에 따라 가공을 하는 단계이다.
가공을 통해 원하는 타입으로 데이터를 변환하거나 필터링하여 전달 가능 하다.
2-4-2-3. ItemWriter
ItemWriter는 Batch에서 출력 작업을 담당한다.
Processor에서 가공된 데이터를 DB에 저장하거나, 원하는 포맷(TXT, CSV, JSON 등)에 맞춰 출력도 가능하다.
출력이 완료되면 Transaction이 종료되고 새로운 Chunk 단위의 프로세스로 이동해 작업을 이어한다.
구현체로는 다음과 같다.
- TXT, CSV 등 파일 : FlatFileItemWriter
- Json : JsonFileItemWriter
- JDBC : JdbcBatchItemWriter
- JPA : JpaItemWriter
- Custom : CustomItemWriter
2-5. Meta Table
위의 내용도 매우 중요하지만 이번 공부에 있어서 개인적으로 Meta Table이 Spring Batch에서 가장 중요하다고 생각했다.
사실상 위의 내용들은 개념 정도로 알고 Batch 전략에 맞춰서 또는 해야할 작업에 맞춰서 활용하면 된다.
하지만 작업을 실패하더라도 다시 실행한다던지, 이미 처리된 내용을 스킵하는 등 이러한 정보를 어디에 저장하고 어디서 가져오는지 이런 판단 요소들이 저장된 곳이 바로 Meta Table이기 때문이다.
2-5-1. Meta Table이란
스프링 배치 메타데이터 테이블은 Java에서 이를 나타내는 도메인 객체와 밀접하게 일치합니다. 예를 들어, JobInstance, JobExecution, JobParameters, StepExecution은 각각 BATCH_JOB_INSTANCE, BATCH_JOB_EXECION, BATCH_JOB_EXECION_PARAMS, BATCH_STEP_EXECION에 매핑됩니다. ExecutionContext는 BATCH_JOB_EXECONT와 BATCH_STEP_EXECONT에 매핑됩니다. JobRepository는 각 Java 객체를 올바른 테이블에 저장하고 저장하는 역할을 합니다. 이 부록에서는 메타데이터 테이블을 만들 때 내린 많은 설계 결정과 함께 자세히 설명합니다. 이 부록에서 설명하는 다양한 테이블 생성 문장을 볼 때, 사용되는 데이터 유형은 가능한 한 일반적이라는 점에 유의하세요. 스프링 배치는 많은 스키마를 예시로 제공합니다. 각 데이터베이스 공급업체가 데이터 유형을 처리하는 방식의 차이로 인해 모두 다양한 데이터 유형을 가지고 있습니다. 다음 이미지는 여섯 개의 테이블에 대한 ERD 모델과 그들 간의 관계를 보여줍니다 - Spring Boot 공식 문서 -
2-5-2. Meta Table ERD

BATCH_JOB_INSTANCE
- 특정 Job 인스턴스의 고유성 관리
- Job Name, Job Parameter 조합으로 인스턴스를 생성
- 동일한 Job Name, Job Parameter의 조합은 단 1개의 인스턴스만 생성 가능
| JOB_INSTANCE_ID | PK |
|---|---|
| VERSION | 해당 레코드에 update 될때마다 1씩 증가 (낙관적 락에 사용) |
| JOB_NAME | 실행된 잡의 이름 |
| JOB_KEY | 잡 이름과 잡 파라미터의 해시 값으로, JobInstance를 고유하게 식별하는 데 사용되는 값 |
BATCH_JOB_EXECUTION
- Job의 실행 정보를 저장
- Job 생성 시간, 시작 시간, 종료 시간, 실행 상태, 실패 메세지 등을 관리
- Job이 실행될 때마다 생성
| 컬럼 이름 | 설명 |
|---|---|
| JOB_EXECUTION_ID | PK |
| VERSION | 해당 레코드에 update 될때마다 1씩 증가 (낙관적 락에 사용) |
| JOB_INSTANCE_ID | BATCH_JOB_INSTANCE 테이블을 참조하는 FK |
| CREATE_TIME | 레코드가 생성된 시간 |
| START_TIME | 잡 실행이 시작된 시간 |
| END_TIME | 잡 실행이 완료된 시간 |
| STATUS | 잡 실행의 배치 상태 |
| EXIT_CODE | 잡 실행의 종료 코드 |
| EXIT_MESSAGE | EXIT_CODE와 관련된 메시지나 Stack Trace |
| LAST_UPDATED | 레코드가 마지막으로 갱신된 시간 |
BATCH_STEP_EXECUTION
- 각 Step의 실행 정보를 저장
| 컬럼 이름 | 설명 |
|---|---|
| JOB_EXECUTION_ID | PK |
| VERSION | 해당 레코드에 update 될때마다 1씩 증가 (낙관적 락에 사용) |
| JOB_INSTANCE_ID | BATCH_JOB_INSTANCE 테이블을 참조하는 FK |
| CREATE_TIME | 레코드가 생성된 시간 |
| START_TIME | 잡 실행이 시작된 시간 |
| END_TIME | 잡 실행이 완료된 시간 |
| STATUS | 잡 실행의 배치 상태 |
| EXIT_CODE | 잡 실행의 종료 코드 |
| EXIT_MESSAGE | EXIT_CODE와 관련된 메시지나 Stack Trace |
| LAST_UPDATED | 레코드가 마지막으로 갱신된 시간 |
BATCH_JOB_EXECUTION_PARAMS
- Job과 함께 실행되는 JobParameter의 정보를 관리
| 컬럼 이름 | 설명 |
|---|---|
| JOB_EXECUTION_ID | PK |
| TYPE_CODE | 파라미터 값의 타입을 나타내는 문자열 |
| KEY_NAME | 파라미터 이름 |
| STRING_VAL | 타입이 String인 경우 파라미터의 값 |
| DATE_VAL | 타입이 Date인 경우 파라미터의 값 |
| LONG_VAL | 타입이 Long인 경우 파라미터의 값 |
| DOUBLE_VAL | 타입이 Double인 경우 파라미터의 값 |
| IDENTIFYING | 파라미터가 식별되는지 여부를 나타내는 플래그 |
BATCH_JOB_EXECUTION_CONTEXT
- Job의 각 Step 실행 상태를 저장
- 모든 Step의 상태를 통합 관리
| 컬럼 이름 | 설명 |
|---|---|
| JOB_EXECUTION_ID | PK |
| SHORT_CONTEXT | 트림(trim) 처리된 SERIALIZED_CONTEXT |
| SERIALIZED_CONTEXT | 직렬화된 ExecutionContext |
BATCH_STEP_EXECUTION_CONTEXT
- 각 Step의 실행 상태를 저장
- 스탭 실행의 메모리 상태를 직렬화하여 저장
| 컬럼 이름 | 설명 |
|---|---|
| STEP_EXECUTION_ID | PK |
| SHORT_CONTEXT | 트림 처리된 SERIALIZED_CONTEXT |
| SERIALIZED_CONTEXT | 직렬화된 ExecutionContext |
