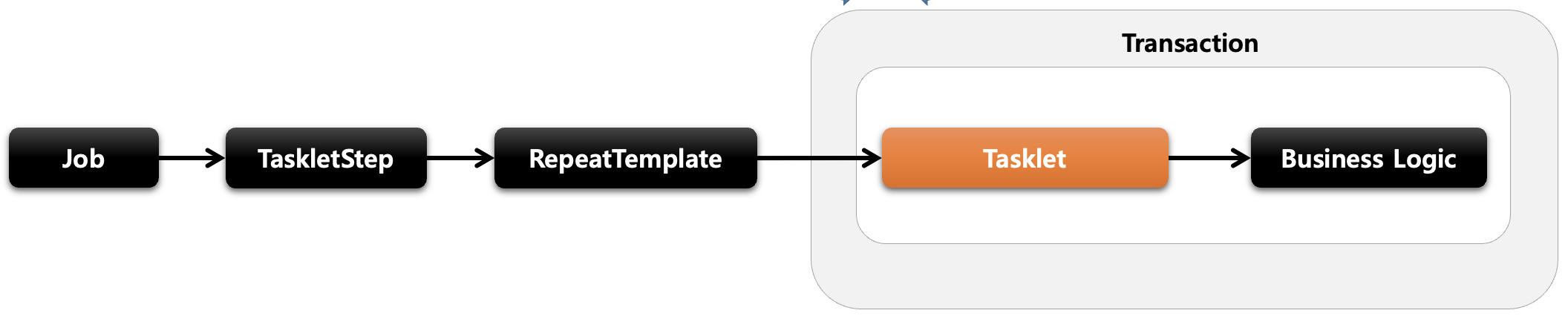
이전 포스트 에서는 Spring Batch에 대해 정리해봤다.
이번 포스트는 Open API를 통해 숙박 정보를 Json으로 받아 간략하게 가공한 뒤, DB에 저장하는 Batch 실습을 정리해보고자 한다.
사용한 숙박 정보API는 아래 공공API를 사용했다.
https://www.data.go.kr/tcs/dss/selectApiDataDetailView.do?publicDataPk=15101578
신청만 하면 바로 승인되니 기다릴 필요도 없고 가이드도 잘 나와있어서 사용하기 편했다.(다만,, response의 field값이 없는 경우가 좀 많다..)
1. 개발 환경
- Language
- Java 17
- Framework
- Spring Boot 3.4.3
- Spring Batch 5.2.0
- Library
- Spring Data JPA
- Lombok
- DataBase
- MySQL 8.0.37
- OS & IDE
- Windows 11
- IntelliJ 2024.3.5
2. 개발 기간
- 2025.03.12 - 2025-03-27 (2주)
원래 목표는 3일이었다.. (1일 공부, 1일 구현 및 테스트, 1일 리팩토링)
하지만 이력서 준비와 개인사로 인해 2주나 걸리고 말았다..🥲
3. 다중 DB 연결
spring.batch.job.enabled=false
spring.batch.jdbc.initialize-schema=never
spring.batch.jdbc.schema=classpath:org/springframework/batch/core/schema-mysql.sql
spring.datasource-meta.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource-meta.jdbc-url=jdbc:mysql://localhost:3307/meta_batch
spring.datasource-meta.username=DB유저
spring.datasource-meta.password=패스워드
spring.datasource-data.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource-data.jdbc-url=jdbc:mysql://localhost:3307/stay_info
spring.datasource-data.username=DB유저
spring.datasource-data.password=패스워드| 필드 | 설명 |
|---|---|
| spring.batch.job.enabled | 애플리케이션 실행 시 batch를 시작 유무 |
| true : 시작 | |
| false : 시작 하지 않음 | |
| spring.batch.jdbc.initialize-schema | 스키마 자동생성 |
| ALWAYS: 스크립트 항상 생성 | |
| EMBEDDED: 내장 DB일 때만 실행되며 스키마가 자동 생성됨 (Default) | |
| NEVER: 스크립트를 항상 실행하지 않음 | |
| spring.batch.jdbc.schema | Meta 테이블 생성 SQL 지정 |
| org/springframework/batch/core/schema-mysql.sql 를 지정하면 됨 | |
| spring.datasource-meta ... | Meta 테이블을 작성할 Schema 지정 |
| spring.datasource-data ... | Data 테이블을 작성할 Schema 지정 |
3-1. DB Config
3-1-1. Meta DB Config
@Configuration
public class MetaDBConfig {
@Primary
@Bean
@ConfigurationProperties(prefix = "spring.datasource-meta")
public DataSource metaDbSource(){
return DataSourceBuilder.create().build();
}
@Primary
@Bean
public PlatformTransactionManager metaTransactionManager(){
return new DataSourceTransactionManager(metaDbSource());
}
}스프링 부트에서 2개 이상 DB를 연결하려면 Config클래스 작성이 필수적이다.
그리고 충돌을 방지하기 위해 다중 DB를 연결하게 되면 어느 DB를 우선 해야하는지 정해야한다.
그렇지 않으면 어느 DB에 데이터를 저장하거나 읽거나 하는 등 작업을 할 수 없기에 에러가 발생하게 된다.
우선 순위를 지정하기 위해서는 @Primary 어노테이션을 사용하면 된다.
@ConfigurationProperties는 prefix로 지정해둔 경로의 값을 불러오는 어노테이션이다.
여기선 위에서 작성한 application.properties의 spring.datasource-meta 로 시작하는 변수의 값들을 불러오게 된다.
읽어온 값들을 DataSource로 반환하면 Meta 테이블의 스키마에 대한 데이터소스가 Bean으로 등록된다.
PlatformTransactionManager도 동일하게 충돌을 방지하기 위해 @Primary 어노테이션을 붙히고
metaDbSource를 매개변수로 지정해 생성해준다.
3-1-2. Data DB Config
@Configuration
@EnableJpaRepositories(
basePackages = "com.study.stay.repository",
entityManagerFactoryRef = "dataEntityManager",
transactionManagerRef = "dataTransactionManager"
)
public class StayDBConfig {
@Bean
@ConfigurationProperties(prefix = "spring.datasource-data")
public DataSource dataDBSource(){
return DataSourceBuilder.create().build();
}
@Bean
public LocalContainerEntityManagerFactoryBean dataEntityManager(){
LocalContainerEntityManagerFactoryBean em = new LocalContainerEntityManagerFactoryBean();
em.setDataSource(dataDBSource());
em.setPackagesToScan(new String[]{"com.study.stay.entity"});
em.setJpaVendorAdapter(new HibernateJpaVendorAdapter());
HashMap<String, Object> properties = new HashMap<>();
properties.put("hibernate.dialect", "org.hibernate.dialect.MySQLDialect");
properties.put("hibernate.hbm2ddl.auto", "update");
properties.put("hibernate.show_sql", "true");
em.setJpaPropertyMap(properties);
return em;
}
@Bean
public PlatformTransactionManager dataTransactionManager(){
JpaTransactionManager transactionManager = new JpaTransactionManager();
transactionManager.setEntityManagerFactory(dataEntityManager().getObject());
return transactionManager;
}
}Meta DB Config와 달리 설정해야할 내용이 조금 더 많다.
먼저 실제 Data가 저장되거나 하기 때문에 @EnableJpaRepositories 어노테이션을 붙히고 repository의 경로와 참조할 EntityManager와 TransactionManager의 메서드명을 지정한다.
해당 메서드 명은 Bean으로 만든 메서드이다.
DataSource는 MetaDBConfig와 동일하게 작성한다. 다만 prefix만 맞게끔 수정하면 된다.
LocalContainerEntityManagerFactoryBean은 위의 @EnableJpaRepositories에 작성했던 EntityManager와 동일한 이름의 메서드를 만들면된다.
em.setPackagesToScan(new String[]{"com.study.stay.entity"});위의 내용은 해당 경로의 Entity Class들을 스캔한다.
아래 properteis의 경우, 다중 DB로 연결하게 되면 변수 설정으로는 어떠한 DB에 대한 설정인지 알 수 없기에 이 Config에 등록한다.
PlatformTransactionManager의 경우 JpaTransactionManager를 초기화 해서 반환해준다.
4. Batch 작성
(※ Batch 작성에 앞서 Entity의 내용들은 따로 적지 않습니다. 보고 싶으신 분들은 GitHub의 Repository를 봐주시면 감사하겠습니다. GitHub )
JobBuilder를 통해 stayInfoJob 이름을 가지며 stayInfoStep이라는 Step을 실행하는 형태의 Job을 생성한다.
incrementer는 작업이 여러번 실행될 때마다 고유한 실행 ID를 증가시키기 위해 사용한다.
@Bean
public Job stayInfoJob(JobRepository jobRepository, Step stayInfoStep) {
return new JobBuilder("stayInfoJob", jobRepository)
.incrementer(new RunIdIncrementer())
.start(stayInfoStep)
.build();
} @Bean
public Step stayInfoStep(
JobRepository jobRepository,
PlatformTransactionManager transactionManager,
StepExecutionListener stayInfoStepListener,
RepositoryItemWriter<StayInfo> stayInfoWriter
) {
return new StepBuilder("stayInfoStep", jobRepository) // Step 이름 지정
.<OpenApiResponse, StayInfo>chunk(10, transactionManager) // Chunk 기반 10개씩 나눠서 실행
.reader(apiResponseReader()) // reader 지정
.processor(stayInfoProcessor()) // processor 지정
.writer(stayInfoWriter) // writer 지정
.listener(stayInfoStepListener) // listener 지정 필요없으면 안해도 됨.
.build();
}Step의 read - processor - writer단계이다. 아래 Processor와 Writer와 함께 대부분 익명함수를 사용한다고 한다.
로직이 길거나 복잡하면 클래스로 만들어서 사용하면 좋다. 자세한 코드 내용은 후술하겠다.
@Bean
public ItemReader<OpenApiResponse> apiResponseReader() {
return new StayInfoReader();
} @Bean
public ItemProcessor<OpenApiResponse, StayInfo> stayInfoProcessor() {
return new StayInfoProcessor();
} @Bean
public RepositoryItemWriter<StayInfo> stayInfoWriter() {
return new RepositoryItemWriterBuilder<StayInfo>()
.repository(stayInfoRepository)
.methodName("save")
.build();
} @Bean
public StayInfoStepListener stayInfoStepListener() {
return new StayInfoStepListener(); // Open Api의 request에서 pageNo 필드 값을 증가시키기 위해 지정
}4-1. Reader
@Component
@Slf4j
public class StayInfoReader implements ItemReader<OpenApiResponse> {
@Value("${api.uri}")
private String apiUri;
@Value("${api.auth-key}")
private String authKey;
@Autowired
private ObjectMapper objectMapper;
@Autowired
private RestTemplate restTemplate;
private static final String KEY_PAGE_NO = "pageNo";
private int pageNo = 1;
/*
* Listener과 관련된 내용으로, pageNo값을 증가 시키기위해 ExceutionContext를 사용했다.
* context에 Key가 존재하면 해당 Value를 pageNo에 대입해 사용한다.
*/
@BeforeStep
public void beforeStep(StepExecution stepExecution){
ExecutionContext context = stepExecution.getExecutionContext();
if(context.containsKey(KEY_PAGE_NO)){
pageNo = context.getInt(KEY_PAGE_NO);
}else{
context.put(KEY_PAGE_NO, pageNo);
}
}
@Override
public OpenApiResponse read() throws Exception{
return getAllStayInfo();
}
/*
*아래 내용은 OpenApi를 통해 Response를 읽어오는 내용이다.
*/
public OpenApiResponse getAllStayInfo(){
log.info("stay info read start.");
try {
URI uri = new URI(apiUri + "?serviceKey=" + authKey
+ "&numOfRows=" + 1000 + "&pageNo=" + pageNo + "&MobileOS=AND&MobileApp=TestApp&_type=json");
ResponseEntity<String> responseEntity = restTemplate.getForEntity(uri, String.class);
if(responseEntity.getStatusCode() == HttpStatus.OK){
log.info("stay info read complete.");
return objectMapper.readValue(responseEntity.getBody(), OpenApiResponse.class);
}
} catch (URISyntaxException | JsonProcessingException e) {
throw new RuntimeException(e);
}
return new OpenApiResponse();
}
}4-2. Processor
Processor는 필요없으면 안해도 상관없지만 Open API의 Response에 사용하지 않을 값들을 삭제하는 가공 처리를 하고 Entity의 형태로 반환했다.
@Slf4j
public class StayInfoProcessor implements ItemProcessor<OpenApiResponse, StayInfo> {
private Iterator<StayInfo> stayInfoIterator;
@Override
public StayInfo process(OpenApiResponse response) {
log.info("process start.");
List<Item> itemList = response.getResponse().body().items().item();
stayInfoIterator = itemList.stream()
.map(item -> StayInfo.from(
item.title(),
item.addr1(),
item.addr2(),
item.areacode(),
item.sigungucode(),
item.firstimage(),
item.firstimage2(),
item.mapy(),
item.mapx(),
item.mlevel(),
item.tel(),
item.likeCount(),
item.rating()
))
.iterator();
log.info("process complete.");
if( stayInfoIterator.hasNext() ){
return stayInfoIterator.next();
}
return null;
}
}4-3 Listener
StepExecution의 경우 Step간의 정보 공유는 되지 않지만 아래 내용은 같은 Step 내부에서 동작하기에 pageNo를 증가 시킬 수 있다.
public class StayInfoStepListener implements StepExecutionListener {
@Override
public void beforeStep(StepExecution stepExecution) {
}
@Override
public ExitStatus afterStep(StepExecution stepExecution) {
ExecutionContext executionContext = stepExecution.getExecutionContext();
int pageNo = executionContext.getInt("pageNo", 1);
executionContext.put("pageNo", pageNo + 1);
return ExitStatus.COMPLETED;
}
}5. Scheduler
아래는 스케줄러로 1분마다 Batch를 실행시키는 형태이다.
@Scheduler 외에도 quartz scheduler로 Batch를 자동 실행할 수 있다.
@Slf4j
@Component
@RequiredArgsConstructor
public class BatchScheduler {
private final JobLauncher jobLauncher;
private final Job stayInfoJob;
@Scheduled(cron = "0 0/1 * * * ?")
public void runJob() {
try {
log.info("Batch job started.");
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH-mm-ss");
String date = dateFormat.format(new Date());
JobParameters jobParameters = new JobParametersBuilder()
.addString("date", date)
.toJobParameters();
log.info("Batch job is start.");
jobLauncher.run(stayInfoJob, jobParameters);
log.info("Batch job completed.");
} catch (Exception e) {
log.error("Batch job failed.", e);
}
}
}6. 실행 결과



7. 회고
사용만 하던 Batch를 간략하게나마 정리할 수 있는 시간이 되었다.
FastCampus에서 OpenAPI를 활용했을 때 Batch를 사용할까 라는 생각을 하긴 했었지만
담당 업무부터 팀장 대리역할을 하느라 Batch라는 생각이 바로 사라졌던 기억이 좀 아쉽다.
조만간 Batch 전략들에 대해 조금 더 알아보고자 한다.
수많은 데이터들을 일괄처리 하는 만큼 분명 성능 저하 등 개선이 필요한 이슈들이 있을텐데
어떻게 개선하면 좋을지 고민을 해보면 실무에서도 좋은 결과를 낼 수 있지 않을까 싶다.
