
1. Introduction
1.1 배경
- 전통적인 deep learning 모델의 한계
- 특정 작업에 최적화된 소규모 데이터셋에 기반하여 학습 → 환경이나 작업 변화에 대해 일반화 하는데 한게 有
- Foundation Models
- Foundation models는 인터넷 규모의 데이터를 활용해 사전 학습 → 뛰어난 일반화 능력과 zero-shot 학습 능력을 보이고 있음
- 수십억~수천억 개의 파라미터를 갖고 있어, 다양한 도메인 및 modality를 동시에 다룰 수 있음
1.2 목표
‘Foundation 모델이 로봇 자율성(autonomy)스택에서 인지(perception), 의사 결정(decision-making), 제어(control)를 어떻게 향상시키는가?’
- Foundation 모델들이 로봇 시스템에 어떻게 적용될 수 있는지, 이 과정에서 어떤 과정들이 존재하는지 체계적으로 정리
- 특히, Foundation 모델의 일반화 능력, multi-modal 데이터 융합, 제어 및 안전성 문제를 중심으로 로봇의 인식(perception), 의사결정(decision-making), 제어(control) 측면의 응용 사례와 기술적 발전을 조명
1.3 추가적 논의
- 기대 효과
- 기존의 특정 작업에 국한된 모델보다 훨씬 유연하고 범용적인 시스템 구축 가능
- 이는 로봇이 미지의 환경에서도 적응할 수 있게 하고, 인간과의 상호작용에서도 자연스러운 의사소통 및 협력이 가능해짐을 의미
- 도전 과제
- 데이트 희소성(data scarcity)
- 높은 다양성(high variability)
- 불확실성 정량화(uncertainty quantification)
- 안전성 평가(safety evaluation)
- 실시간 처리(real-time perfomance)
2. Foundation Models Background
2.1 Terminology and Mathematical Preliminaries
-
Tokenization | 토큰화
- 텍스트나 기타 sequence data를 token 단위로 나누고, 각 token을 1-hot 벡터로 표현한 수와 학습된 embedding 행렬을 통해 저차원의 연속(실수) 벡터로 변환
- self-attention 공식을 바탕으로 여러 head가 병렬로 학습되어, 문맥 내 token간 상호작용을 효과적으로 파악
- e.g. GPT-3는 50.257개의 토큰 사전을 사용하고, 각 토큰은 12.288차원의 임베팅으로 표현됨
-
Generative Models | 생성형 모델
- 학습데이터 분포를 모델링하여 주어진 조건에 따라 새로운 데이터 생성
- 텍스트 조건 하에 현실적인 이미지 생성 가능
-
Discriminative Models | 판별 모델
- 조건부 확률을 모델링하여 주어진 입력에 대해 올바른 레이블을 예측하는 방식
- 분류(classification), 회귀(regression) 에서 사용
-
Transformer Architecture
- 입력 sequence 내 모든 token들이 서로 상호작용 할 수 있도록 다중 헤드 self-attention 메커니즘을 사용. 이 매커니즘을 통해 각 token이 문맥(context window) 내 다른 token 간의 상호 관계 파악 가능
- 수식
- (Query):
- (Key):
- : Key 벡터의 차원
- (Value):
- : 학습 가능한 가중치 행렬
-
Autogressive Models | 자기 회귀 모델
- 입력 시퀀스에서 앞의 token들을 조건으로 하여 순차적으로 다음 token을 예측하는 방식
- 예로 GPT 계열 모델은 다음의 손실 함수를 사용
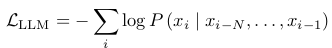
-
Masked Auto-Encoding(MAE)
- 입력의 일부 token을 마스킹한 후, 그 마스킹된 token들을 예측하도록 학습하여 문맥을 양방향으로 이해
-
Contrastive Learning
- 서로 다른 modality(e.g. 이미지, 텍스트)간의 연관성을 학습하기 위해 올바른 쌍(pair)은 임베딩 공간에서 가깝게, 틀린 쌍은 멀리 위치하도록 학습하는 기법
- 손실 함수
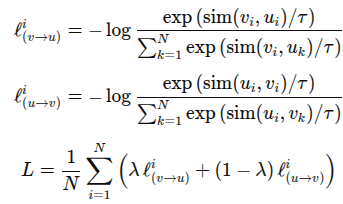
- : 유사도
- : 온도 파라미터
- : 두 손실의 가중치 비율
-
Diffusion Models
- 입력 이미지에 점진적으로 노이즈를 전방과정과, 역방향으로 이 노이즈를 제거해 이미지를 복원하는 과정을 통해 이미지 생성
- 전방향(forward) 수식:
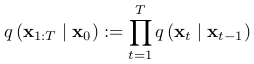
- : 원본 이미지
- : 완전히 노이즈화된 이미지
- 역방향(reverse) 수식
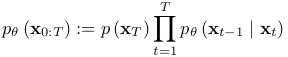
- 모델은 시작하여, 학습된 분포를 이용해 원본 이미지 복원
-
Large Language Model(LLM) Examples and Historical Context
- 대규모 텍스트 데이터로 학습 → 방대한 언어 이해, 생성 능력 확보
- fine-tuning, RLHF(Reinforecement Learning with Human Feedback) 등을 통해 다양한 도메인, 언어에 적용
-
Vision Transformers(ViT)
- 입력이미지를 고정된 크기의 패치(patch)로 분할 → 각 패치를 token처럼 취급하여 Transformer encoder에 입력 → 압축되어 1차원 벡터로 변환 → 선형 변환을 동해 임베딩 벡터로 매핑
- 각 패치 임베딩에 position encoding(위치 정보)을 추가하여, 패치 간의 공간적 구조를 보존
- e.g. ViT-G, ViT-22B ← 고해상도 이미지 처리, 로봇 비전에서 정밀한 특징 추출 가능
-
Multimodal Vision-Language Models(VLMs)
- 이미지와 텍스트 두 modality를 동시에 인코딩(텍스트, 이미지 임베딩을 대조학습으로 정렬)하여 두 데이터 간의 의미적 연관성을 학습
- open-vocabulary, zero-shot 객체 검출에 강점
- e.g. CLIP, BLIP, FILIP
-
Embodied Multimodal Language Models
- LLM과 Vision을 결합해 로봇 상태, 이미지, 텍스트를 함께 처리
- e.g. PaLM-E: LLM + ViT
-
Visual Generative Models
- 텍스트 조건 하에 이미지를 생성하여, 로봇 시뮬레이션 환경 구성이나 데이터 보강에 활용
- 텍스트 임베딩이 이미지 생성 과정에 주입 → 순차적으로 노이즈를 제거하며 최종 이미지 복원하는 방식
- DALL-E, DALL-E2
- 텍스트에서 생성된 임베딩을 바탕으로 이미지 decoder를 통해 현실적인 이미지 생성
- Stable Diffusion
- 노이즈 추가 및 제거 과정을 통해 텍스트 조건에 맞는 이미지 생성
- ex) DALL-E, DALL-E2, Stable Diffusion

로봇 소프트웨어 개발자입니다. AI 공부도 합니다.