
3. Robotics
3.1 Robot Policy Learning for Decision Making and Control
-
Language-conditioned Imitation Learning for Manipulation
-
로봇은 시연 데이터와 자연어 지시를 통해 행동 정책()을 학습
- 각 시연은 상태, 행동, 언어 지시의 순서로 구성
-
정책 함수
- ← 확률 분포
- : 언어 지시
- : 조건
- : 행동
- ← 확률 분포
-
손실 함수
-
주어진 시연에서 실제로 취한 행동을 모델이 잘 재현하도록 학습시키는 역할
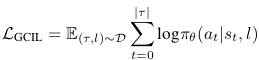
- GCIL(Goal-Conditioned Imitation Lerning)
- : 언어 주석이 포함된 시연 데이터셋
- : 일련의 상태-행동-언어 쌍 { }
-
-
-
Language-Assisted Reinforcement Learning
- 강화학습(RL)을 통해 로봇이 환경과 상호작용하여 최적의 행동 정책을 학습할 때, LLM, VLM이 제공하는 자연어 기반 정보 사용하여 a) 복잡한 작업을 하위 작업으로 분할 or b) 탐색 과정에서 유용한 보상 함수 구성 → 언어 기반 보상 신호를 구성 → RL 에이전트가 학습
3.2 Language-Image Goal-Conditioned Value Learning
- 로봇이 현재 상태 와 목표 에 대해 “얼마나 가치가 있는지”를 평가하도록 가치함수 를 학습해, 목표 달성을 위한 최적의 행동을 선택
- 시각적 정보와 언어 목표를 결합하여 로봇이 환경 내에서 “어떤 상태가 목표에 가까운지”를 평가하는 방식을 학습
- Time-Contrastive Learning
- 시간적으로 인접한 프레임들 간의 거리를 최소화, 멀리 떨어진 프레임과의 거리를 크게 하는 방식 → 연속적인 상태 간의 차이를 학습
- Contrastive Loss 기반 가치 학습
- 이미지와 언어 임베딩 사이의 코사인 유사도 활용 → 주어진 목표 상태에 가까운 상태의 값을 높게 평가
- Time-Contrastive Learning
- e.g.
- R3M: 사전 학습된 시각적 표현을 고정시킨 채, 로봇 조작 작업에서의 가치 평가에 활용
- VIP: 순수한 비지도 학습을 통해 언어 및 시각 정보를 결합한 가치 함수를 학습
- LIV: 다중모달 대조 학습을 통해 언어 및 시각 정보를 결합한 가치 함수를 학습
3.3 Robot Task Planning using Large Language Models
- Language Instructions for Task Specification
- LLM을 사용해 사용자의 고수준 명령을 분석하고, 이를 세부 작업으로 분해
- 주방 정리 → 식기 정리, 재료 분류
- 자연어(NL, natural launguage)를 template, temporal logic(TL) 등으로 변환하여 복작한 작업을 단순화 →
- LLM을 사용해 사용자의 고수준 명령을 분석하고, 이를 세부 작업으로 분해
- Code Generation using Language Models for Task Planning
- LLM이 자연어 설명을 받아 실행 가능한 로봇 제어 코드를 생성
- Few-shot 프롬프트 기법을 통해, 기존 예시를 참고하여 재귀적으로 함수 구조를 완성하고 API 호출 형태로 코드 생성
- 생성된 코드는 안전성 검증 및 사용자 피드백 과정을 거쳐 실제 로봇 제어에 반영
3.4 In-context Learning (ICL) for Decision-Making
- 사전 학습된 모델 파라미터를 업데이트 하지 않고, 프롬프트 내 예시를 통해 새로운 상황에 바로 추론하는 기법
- 상황이 빠르게 변하는 로봇 환경에서 추가 학습 없이 모델이 프롬프트 예시만으로 즉각적인 의사결정 가능
- Chain-of-Thought 기법을 통해 복잡한 문제를 단계별로 해결할 수 있도록 중간 추론 단계를 명시적으로 생성
3.5 Robot Transformers
- Transformer 기반의 로봇 정책 모델(e.g. RT-1, RT-2)을 사용하여, 인식(perception), 의사 결정(decision-making), 제어(control)를 하나의 모델(네트워크 내에서 동시에)로 학습
- 대규모 로봇 경험 데이터셋을 통해 다양한 작업을 하나의 모델로 일반화 → 서로 다른 로봇 플랫폼에서도 동일한 정책을 적용할 수 있도록 설계
- Transformer 기반 정책에서는 입력으로 주어진 이미지 및 텍스트 임베딩을 받아, 내부의 다층 self-attention과 FFN을 거쳐 최종 행동 분포를 출력
- 행동은 6-DoF pose, 그리퍼 동작, 종료 명령 등으로 구성되며, 각 행동이 적절한 확률 분포를 가지도록 학습됨
3.6 Open-Vocabulary Robot Navigation and Manipulation
- 미리 정의된 고정 클래스 대신, 자연어로 표현된 개방형 어휘(open vocabulary)를 사용하여 로봇이 새로운 객체나 목표를 인식하고 조작
- VLM은 덱스트 임베딩과 이미지 임베딩의 cos 유사도를 계산하여, 자연어 설명과 일치하는 객체를 인식 ⇒ 학습데이터에 없는 새로운 환경이나 객체에 대해서 유연하게 대처 가능
- 로봇 navigation에서는 사용자가 “빨간 의자를 향해 가라”와 같이 명령할 때, CLIP과 같은 모델이 “빨간 의자”에 해당하는 객체를 실시간으로 탐지하고, 경로 계획에 반영
- 개방형 어휘를 활용해 사전 학습된 카테고리 외의 객체도 인식 및 조작 가능
4. Perception
4.1 Open-Vocabulary Object Detection and 3D Classification
- 사전에 정해진 고정 클래스(label)에 의존하지 않고, 개방형 어휘(open vocabulary)를 기반으로 객체를 인식
- 로봇이 다양한 환경에서 미리 정의되지 않은 객체들도 인식 가능
- Vision-Language Models (VLMs):
- CLIP, OWL‑ViT 등과 같은 VLM들이 활용됨. 이들 모델은 이미지와 텍스트를 동일 임베딩 공간으로 정렬하여, 자연어 설명과 이미지 간의 코사인 유사도를 계산
- 예를 들어 “빨간 의자”라는 자연어 설명과 일치하는 객체를 이미지 내에서 탐지하고 분류
- 3D Classification:
- 2D 이미지 정보 외에도, LiDAR나 RGB‑D 센서 등에서 얻은 3D 데이터로 객체의 입체적 특징을 분석하여 분류
- 이러한 3D 분류 기법은 로봇이 공간 내에서 객체의 형태나 위치 등 입체 정보를 효과적으로 활용할 수 있도록 함
4.2 Open-Vocabulary Semantic Segmentation
- 이미지 내의 각 픽셀 단위로 객체 또는 배경 등 의미적 영역을 분할하여, 자연어 기반의 라벨을 부여
- 개방형 어휘 기반 세분화는, 사전에 미리 정해진 클래스 대신, VLM을 통해 자연어로 표현된 라벨과 픽셀 정보를 매칭하는 방식으로 이루어짐
- 최신 모델인 SAM(Segment Anything Model) 등은 실시간 세분화에 적합한 성능을 제공하며, 이를 통해 로봇은 환경의 세밀한 시맨틱 정보를 획득 가능
4.3 Open-Vocabulary 3D Scene and Object Representations
- 로봇이 3D 공간에서 장면(scene)과 객체(object)를 인식하고 표현할 수 있도록, 언어적 정보와 3D 데이터를 결합
- Language Grounding in 3D Scene:
- 3D 점군(point cloud) 데이터나 신경 장면 표현(NeRF 등)을 사용하여, 3D 장면 내에서 특정 객체나 영역에 해당하는 언어 표현을 추출
- 이 과정을 통해 로봇은 “어디에 어떤 객체가 있는지”를 보다 명확하게 파악 가능
- Scene Editing 및 Object Representations:
- 인식된 3D 장면 정보를 바탕으로, 객체의 위치, 모양, 그리고 상호 관계를 정량적으로 표현
- 이를 활용하여, 장면 내 객체의 이동, 추가 또는 제거와 같은 편집 작업에도 적용 가능
4.4 Learned Affordances
- 로봇이 환경 내의 객체들에 대해 “어떤 행동을 취할 수 있는지”를 판단하도록, 객체의 행동 가능성을 학습
- 시각적 특징과 객체의 기능적 속성을 결합하여, 로봇이 “이 객체는 잡을 수 있다” 또는 “밀 수 있다”와 같은 판단을 내릴 수 있도록 함
- 이러한 affordance 모델은 로봇의 조작 작업에서 객체와 상호작용할 때 필수적인 정보를 제공
4.5 Predictive Models
- 현재 상태와 과거의 관측 데이터를 바탕으로, 미래의 상태나 로봇의 행동 결과를 예측할 수 있도록 하는 모델들을 다룸
- Predictive Models는 로봇 제어 및 계획에 중요한 역할을 하며, 이를 통해 로봇은 동적 환경에서 안정적인 의사결정을 내릴 수 있음
- 예측 모델은 시뮬레이션 기반의 예측, 동적 시스템 예측, 강화 학습에서의 미래 상태 예측 등 다양한 접근법을 포함

로봇 소프트웨어 개발자입니다. AI 공부도 합니다.