GCP Professional Data Engineer 시험 정리

GCP Professional Data Enginer 시험을 준비하면서 도움이 됬던 팁이나 후기를 정리하여 올립니다. coursera 의 자격증 준비 과정을 수강했고 해당 과정에는 실습도 다수 포함되어 있어서 서비스 이해에 큰 도움이 됬습니다. 하지만 해당 과정만 듣고서 시험 합격은 어렵다고 보고 추가로 덤프 사이트를 참고 했습니다. 덤프 사이트는 passnexam 이고 거의 모든 문제가 해당 덤프에서 나왔습니다.
Service List
Cloud SQL
- 친숙함: 대부분의 MySQL 문과 함수, 프로시저, 트리거, 뷰를 지원.
- Fully-managed: MySQL, PostgreSQL, SQL Server용 완전 관리형 관계형 데이터베이스 서비스.
- 지원하지 않음: 파일 및 플러그인과 관련된 함수나 사용자 정의 명령문 및 함수.
- Flexible pricing: 사용량 또는 시간당 지불할 수 있습니다. 백업, 복제 등이 자동으로 관리.
- 어디서든 접근 : 고정 IP 주소를 할당할 수 있고 일반적인 SQL 커넥터 라이브러리를 사용할 수 있음.
Auth Proxy
승인된 네트워크나 SSL 구성 없이도 인스턴스에 안전한 액세스를 제공하는 Cloud SQL 커넥터.
로컬 환경에서 로컬 클라이언트를 실행하여 작동합니다. 애플리케이션은 데이터베이스에서 사용하는 표준 데이터베이스 프로토콜을 사용하여 Cloud SQL 인증 프록시와 통신합니다.
Cloud Spanner
Properties:
- 트랜잭션 일관성을 갖춘 글로벌 완전 관리형 관계형 데이터베이스
- Data in Cloud Spanner is strongly typed: you must define a schema for each database, and that schema must specify the data types of each column of each table.
- 보조 인덱스
- 노드 추가로 더 많은 처리량을 지원
Interleaving table
테이블이 자주 조인될 때 동일한 물리적 공간에 배치. 조인 성능을 향상.
Cloud Bigtable
Properties:
• Millisecond latency, NoSQL. 빅쿼리보다 빠르다.
• Access is designed to optimize for a range of Row Key prefixes
• Access control
• Choosing between SSD and HDD
피해야 할 row key
타임스탬프로 시작되는 row key, 그룹화되지 않게 하는 row key, 자주 업데이트되는 식별자
가장 최근 데이터 조회
역방향 타임스탬프로 row key를 설정
Cloud Storage
영구 저장, 다른 서비스를 위한 스테이징 영역
접근
- 세분화된 접근 제어: Project, Bucket, or Object
- IAM roles, ACLs, and Signed URLS
특징
- 버전 관리
- 암호화: default (Google), CMEK, CSEK Lifecycles
- Change storage class
- Streaming
- Data transfer/synchronization
- Storage Transfer Service
- JSON and XML APIs
모범 사례
- Traffic estimation
Firestore
특징
• NoSQL document 데이터베이스
• ACID transactions
• 수요에 따라 손쉽게 확장 또는 축소, 유지보수 중단 시간 없음
• 완전 관리형, 서버리스
BigQuery
설계원칙
if data is time based or sequential, find partition and cluster option.
if data is not time based, always look for denomalize / nesting option.
BigQuery ML
GoogleSQL 쿼리를 사용하여 머신러닝 모델을 만들고 실행할 수 있습니다. 모델을 만들 때 TRANSFORM 절을 사용하면 모든 사전 처리를 지정할 수 있습니다.
Google Stackdriver
분산 로그, 메트릭, 이벤트를 GCP의 Stackdriver에서 한 곳에 수집하여 모니터링에 대한 다양한 서비스를 제공. Cloud(GCP, AWS) 환경이 아닌 On-Prem 환경에서도 Stackdriver를 사용할 수 있다.
DataStudio
웹 기반의 데이터 시각화 도구. BigQuery 와 연동해서 사용가능
Disable Cache
기본적으로 성능을 개선하고 쿼리 양을 줄이기 위해 데이터를 캐시합니다. 이로 인해 캐시된 데이터가 최신이 아니므로 시각화에 1시간 미만의 데이터가 표시되지 않을 수 있습니다. 이 문제를 해결하려면 보고서 설정을 편집하여 캐싱을 비활성화해야 합니다.
DataFlow
Apache Beam SDK를 활용해 배치와 스트리밍 데이터 프로세싱 파이프라인을 구현할 수 있도록 해주는 GCP의 서비스이다.서버와 인프라에 대한 고려 없이 서버리스로 데이터 파이프라인을 설계.
Apache Beam
ETL, batch, streaming 파이프라인을 처리하기 위한 unified programming model. 다양한 랭귀지와 다양한 runner를 지원. Beam SDK를 통해 다양한 runner( Mapreduce, Spark, Flink 등)에서 데이터를 처리 가능. 매년 더 발전된 분산처리엔진이 나오고 있는데, 이 트랜드를 따라가면서 각자의 장단점에 따라 하나를 선택하기도 쉬운 일이 아니기에 Beam을 통해 원하는 랭귀지로 개발하고, 러너는 원하는 것으로 선택하자는 것.
Windowing
Streaming Data 같은 데이터가 끊이지 않고 들어오기 때문에 이를 위해 시간을 기준으로 작업을 끊어서 처리 하는데 이를 Windowing이라고 합니다.
- fixed windows(tumbling) : 일정 시간 단위로 시간 윈도우를 쪼개는 개념.
- sliding windows(hopping) : 현재시간으로부터 N 시간의 데이터를 특정 시간마다 추출. 다른 윈도우와 중첩되는 윈도우. Moving averages of data.
- session windows : 세션은 사용자가 시스템을 사용한 후 사용이 끝날때까지의 기간을 정의 하며, 시간에 따라 불규칙하게 분산 된 데이터 처리에 유용합니다. user session data, click data and real time gaming analysis.
Job 중단
- Cancle: Job 중단시 모든 프로세싱중인 데이터 소멸
- Drain: 버퍼에 저장되어있는 데이터는 모두 진행시키고 Job을 중단
트리거
처리중인 데이터를 언제 다음 단계로 넘길지 결정하는 기준
- Time trigger : 일정 시간 주기로 트리거
- Elements Count : 데이터가 일정 개수 이상 들어올시
- Punctuations : 특정 데이터가 들어오는 순간 트리거링.
워터마크
실제 데이터가 시스템에 도착하는 시간을 예측
DataFusion
Dataproc
Managed Hadoop service
Graceful Decommissioning
진행 중인 작업이 Cloud Dataproc 클러스터에서 삭제되기 전에 완료될 수 있도록 합니다.
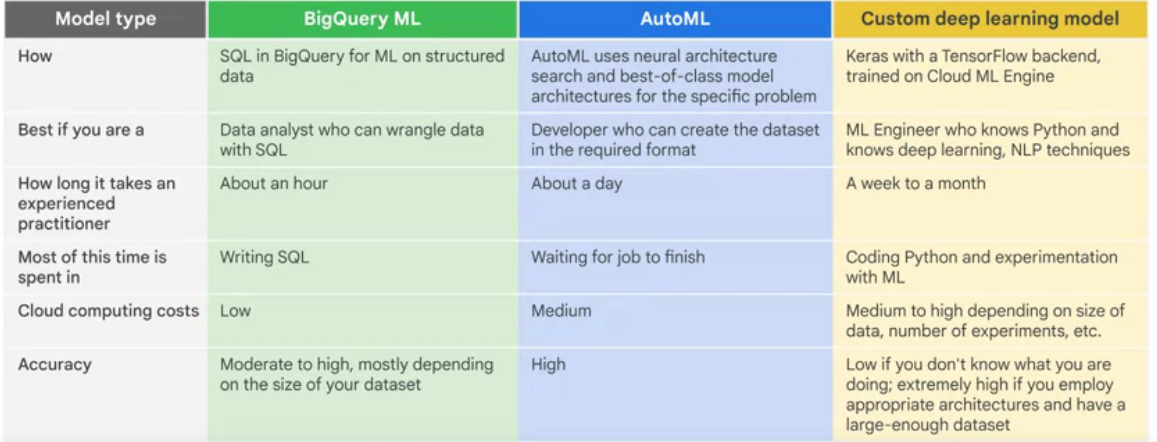
AutoML
liner regression
If you are forecasting that is the values in the column that you are predicting is numeric
logistics regression
If you are classifying, that is buy or no buy, yes or no, you will be using logistics regression
Regularization
use L1 regularization becuase we know the feature is a strong feature. L2 will evenly distribute weights
- Dimensionality Reduction : 데이터의 양을 축소
- Threading : 병렬로 ops를 동작
- DropOut : 선택적으로 노드를 드롭. 과적합시에 사용.
Pub/Sub
- pull mode : push mode could continue to overwhelm the system. lower latency, more-real-time
- push mode : new event data to be pulled for processing on demand. Pull is ideal for large volume of messages, and uses batch delivery
Dialogflow
모바일 앱, 웹 애플리케이션, 기기, 봇 등에 설계하고 통합할 수 있는 자연어 이해 플랫폼.
Cloud Text-to-Speech를 사용하여 에이전트에서 음성 응답도 생성.
Exam Tip
Designing Data Processing Systems
관리형 서비스에는 여전히 오버헤드가 존재. 서버리스 서비스는 관리형 서비스에 비해 오버헤드를 최소화.
Managed services
- Cloud SQL
- Cloud Spanner
- Cloud Bigtable
- Dataproc
Serverless services
- Cloud Storage
- Firestore : NoSQL document DB. Automatic scailing.
- BigQuery
- Dataflow
Design data pipelines
users use roles to limit access to only Dataflow resources, not just the project
Dataflow 와 DataPrep의 차이
Dataflow는 no coding. 편리하지만 더 제한이 크다. Dataflow는 원하는 모든 데이터 소스를 활용 가능.
Design Data Processing Infrastructure
온프레미스 위치에서 데이터를 전송할 때는 gsutil을 사용. 다른 클라우드 스토리지 공급자로부터 데이터를 전송할 때 Storage Transfer Service를 사용. 그렇지 않으면 상황에 맞게 두 도구를 모두 고려.
또한 gsutil은 작은 전송 크기(최대 1TB)를 지원할 수 있지만 온프레미스 데이터용 Storage Transfer Service는 대규모 전송(최대 페타바이트 데이터, 수십억 개의 파일)용으로 설계되었습니다.
Partner Interconnect는 지원되는 서비스 제공업체를 통해 온프레미스 네트워크와 VPC 네트워크 간의 연결을 제공.
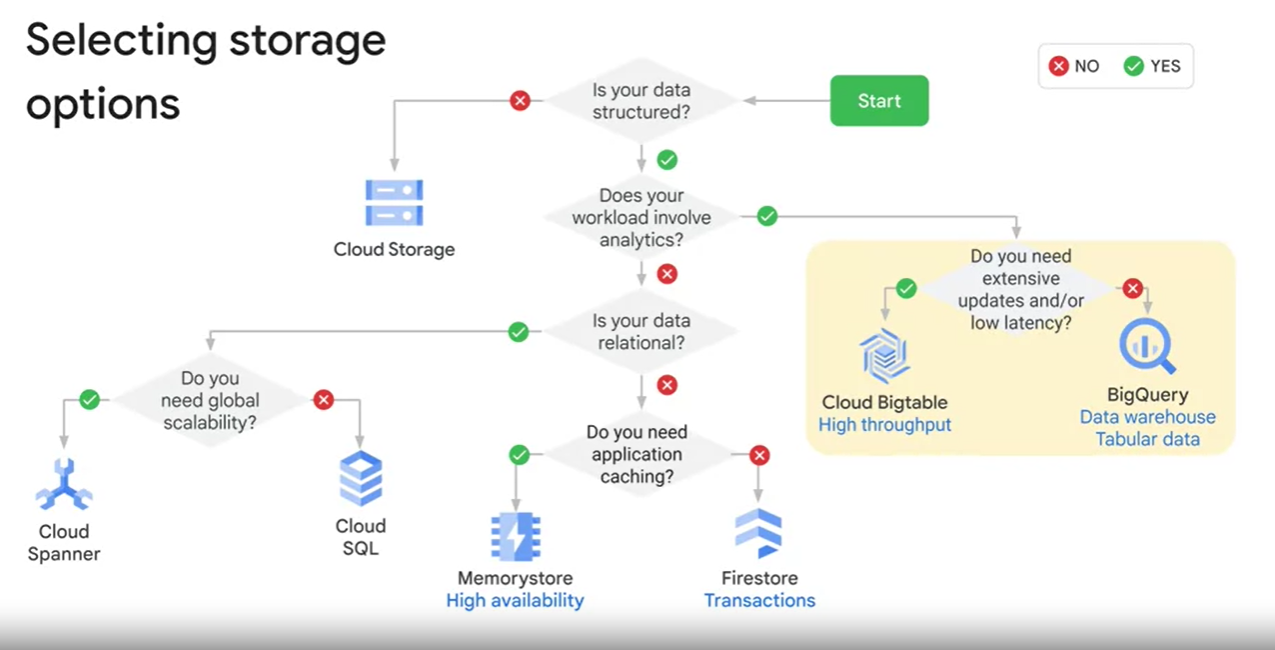
Building Data Structures and Databases
Analysis and Optimization
Four key elements of work
- I/O: How many bytes did you read:
- Shuffle: How many bytes did you pass to the next stage?
- Materialization: How many bytes did you write to storage?
- CPU work: User-defined fuctions
Prevent Overfitting
- Get more training examples Most Voted
- Use a larger set of features
- Decrease the regularization parameters
Prevent Underfitting
- Increase the complexity of your model
Designing for Security
IAM resource hierachy
- Organization(example.com) -> Folders -> Projects -> Resources(BigQuery, Cloud Storage)
- 상위 정책이 하위 정책보다 더 열려있다면 더 상위 정책이 하위 정책을 덮어쓴다.
Encryption of VM and Storage

Prevent data leaking
Cloud DLP : 텍스트 또는 이미지 에서 민감한 정보(전화번호, 신용카드, 이메일 등)가 있는 부분을 검사하고 수정하는 기능을 API형태로 제공
Learning의 종류
지도 학습 (Supervised Learning)
컴퓨터에게 정답(Label)이 무엇인지 알려주면서 컴퓨터를 학습을 하는 방법. 정확도가 높지만 시간이 오래 걸림.
비지도 학습 (Unsupervised Learning)
정답을 알려주지 않고 비슷한 데이터를 군집화 하여 미래를 예측하는 학습 방법. 사용자가 직접 목표 값에 개입할 필요가 없어 속도가 빠르지만 정답이 정해져있지 않으므로 분류 기준과 군집을 예측할 수 없으며, 모델 성능을 평가하기 어렵다는 단점이 있습니다.
강화 학습(Reinforcement Learning)
분류할 수 있는 데이터가 존재하는것도 아니고 데이터가 있다 해도 정답이 따로 정해져 있지도 않으며, 자신이 한 행동에 대해 보상(reward)을 받으며 학습하는 것을 말합니다.
https://reoim.tistory.com/entry/GCP-%EC%9E%90%EA%B2%A9%EC%A6%9D-%ED%9B%84%EA%B8%B0-Google-Cloud-Certified-Professional-Data-Engineer
https://woongjun-warehouse.tistory.com/97
https://blog.naver.com/PostView.naver?blogId=lbhhoya&logNo=222236221417
https://www.coursera.org/professional-certificates/gcp-data-engineering
https://www.coursera.org/specializations/gcp-data-machine-learning?
https://www.coursera.org/learn/preparing-cloud-professional-data-engineer-exam

"Dataflow는 no coding. 편리하지만 더 제한이 크다. Dataflow는 원하는 모든 데이터 소스를 활용 가능."
이 문장에서 Dataflow는 no coding.이 아니라 Dataprep는 no coding. 아닌가요?
오타가 있는거 같아서요!