https://tyami.github.io/machine%20learning/decision-tree-4-CART/
의사결정 나무 (Decision Tree) CART 알고리즘
-
CART는 ID3알고리즘과 비슷한 시기에, 별도로 개발된 알고리즘으로 Classification And Regression Tree의 약자입니다.
-
이름 그대로 Classification뿐 아니라 Regression도 가능한 알고리즘인데, 이 외에도 앞서 소개한 알고리즘들과 몇 가지 차이점이 존재합니다.
-
불순도: Gini index
-
Binary tree
-
Regression tree
-
불순도: Gini index
-
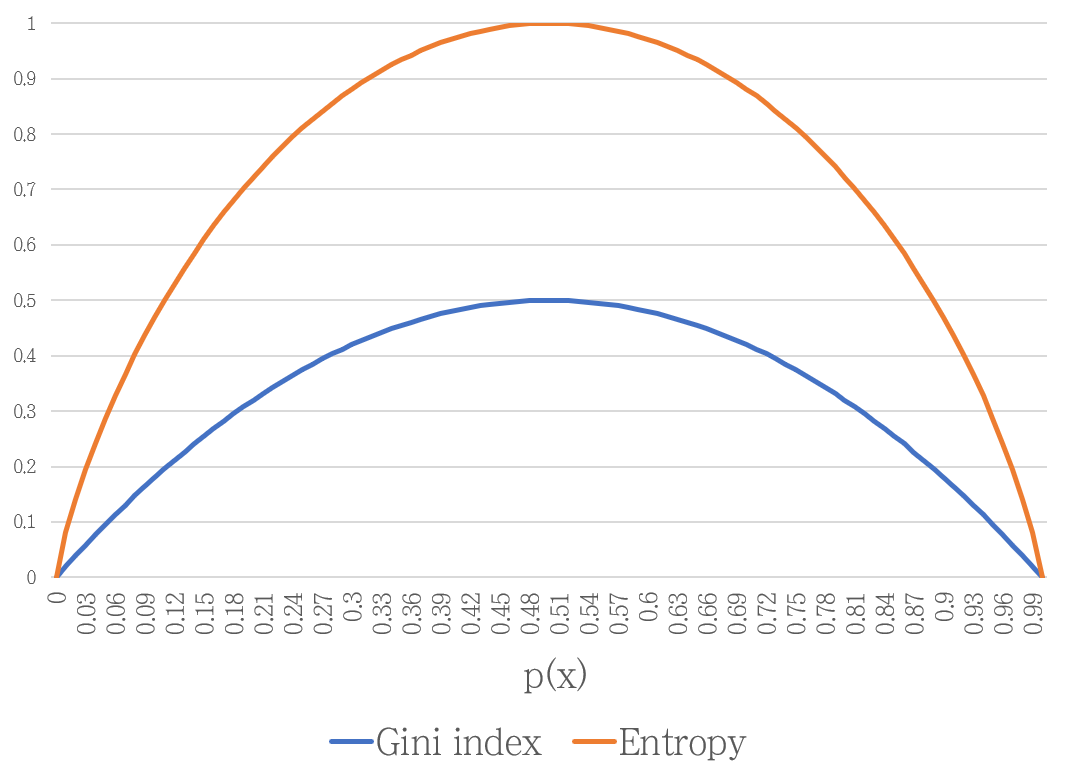
Gini index는 엔트로피와 같은 불순도 (Impurity) 지표입니다.
- 개 사건의 집합 에 대한 Gini index 는 아래 수식으로 표현됩니다.
-
Gini index는 엔트로피와 같이 분류가 잘 될 때 낮은 값을 갖습니다.
- 따라서 CART 알고리즘에서는 모든 조합에 대해 Gini index를 계산한 후, Gini index가 가장 낮은 지표를 찾아 분기합니다.
Binary tree
-
CART 알고리즘의 또 하나의 특징으로는 가지 분기 시, 여러 개의 자식 노드가 아닌 단 두 개의 노드로 분기한다는 것 입니다 (Binary tree).
-
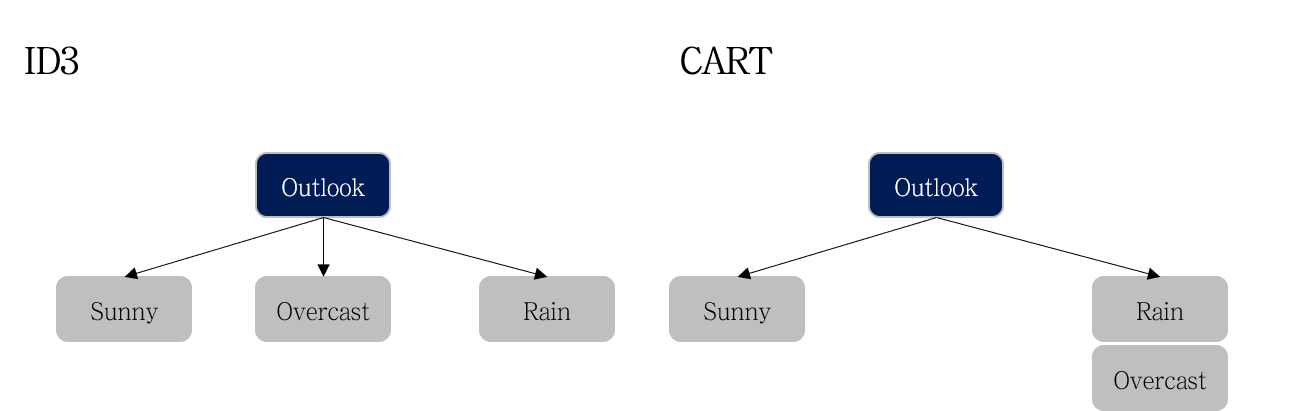
좌측은 ID3 알고리즘, 우측은 CART 알고리즘의 분기를 나타냅니다.
-
ID3 의 경우 모든 클래스 (e.g., Sunny, Overcast, Rain) 로 가지가 뻗어져나갑니다. 따라서 ID3 알고리즘의 경우 지표별 Information Gain을 한 번씩만 계산하면 됩니다.
-
-
반면, CART는 ‘하나의 클래스와 나머지’와 같이 가지가 생성됩니다. 따라서 아래 예시와 같이 모든 지표 X 모든 클래스 개수만큼 비교가 필요합니다.
-
-
-
-
-
-
-
$IG(\text{Play}, \text{Humidity} = \text{high})$
-
-
-
-
-
Regression tree
-
Classification And Regression Tree 라는 이름답게, CART 알고리즘은 Regression(회귀)를 지원합니다.
- 회귀는 쉽게 말해, 결과값이 성별, 등급과 같은 몇 개의 클래스값이 아니라, 온도, 가격 등 다양한 값이 존재하는 문제를 말합니다.
-
회귀 트리 (Regression Tree)의 방법은 간단합니다. 분기 지표를 선택할 때 사용하는 index를 불순도 (Entropy, Gini index)가 아닌, 실제값과 예측값의 오차를 사용합니다.
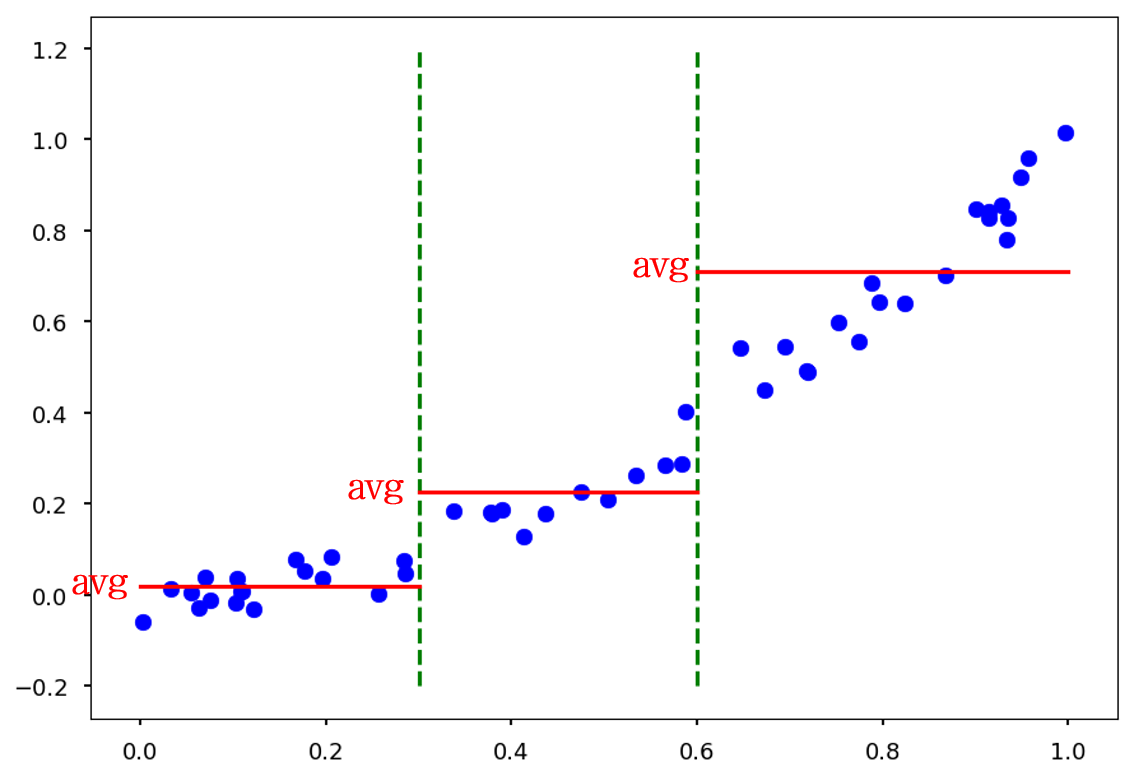
-
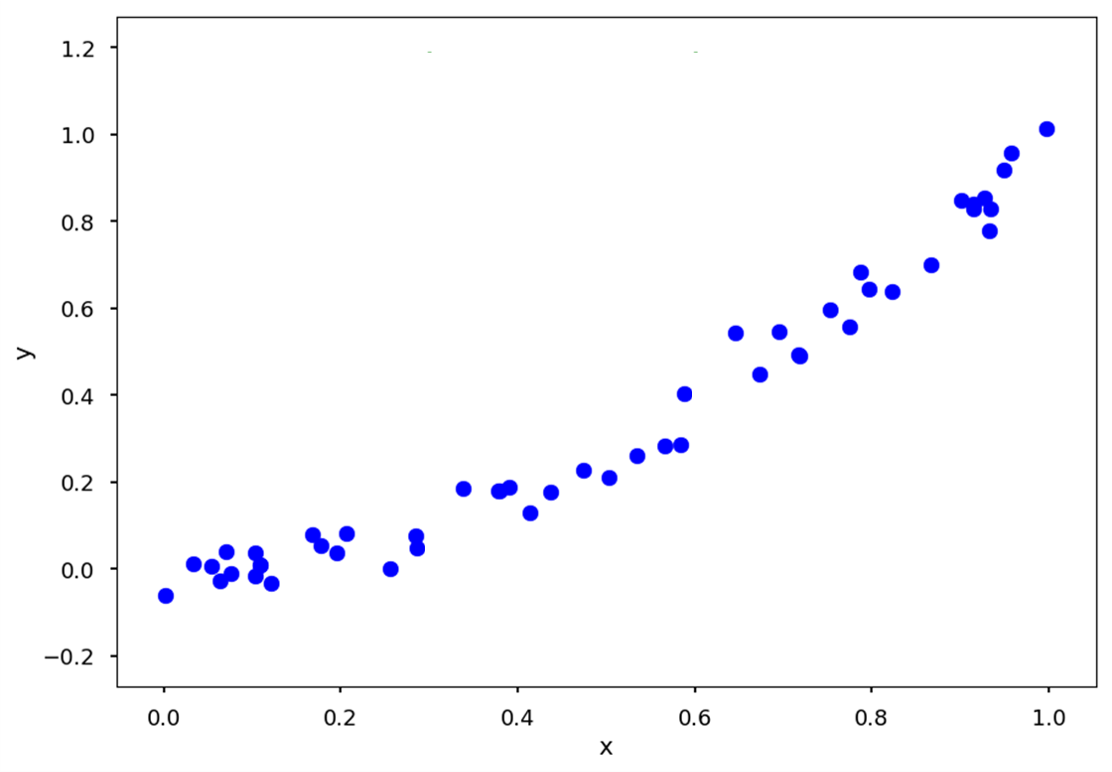
위와 같은 트렌드를 갖는 데이터를 기반으로, x에 따라 y를 예측하는 의사결정 나무를 만들고자 합니다.
-
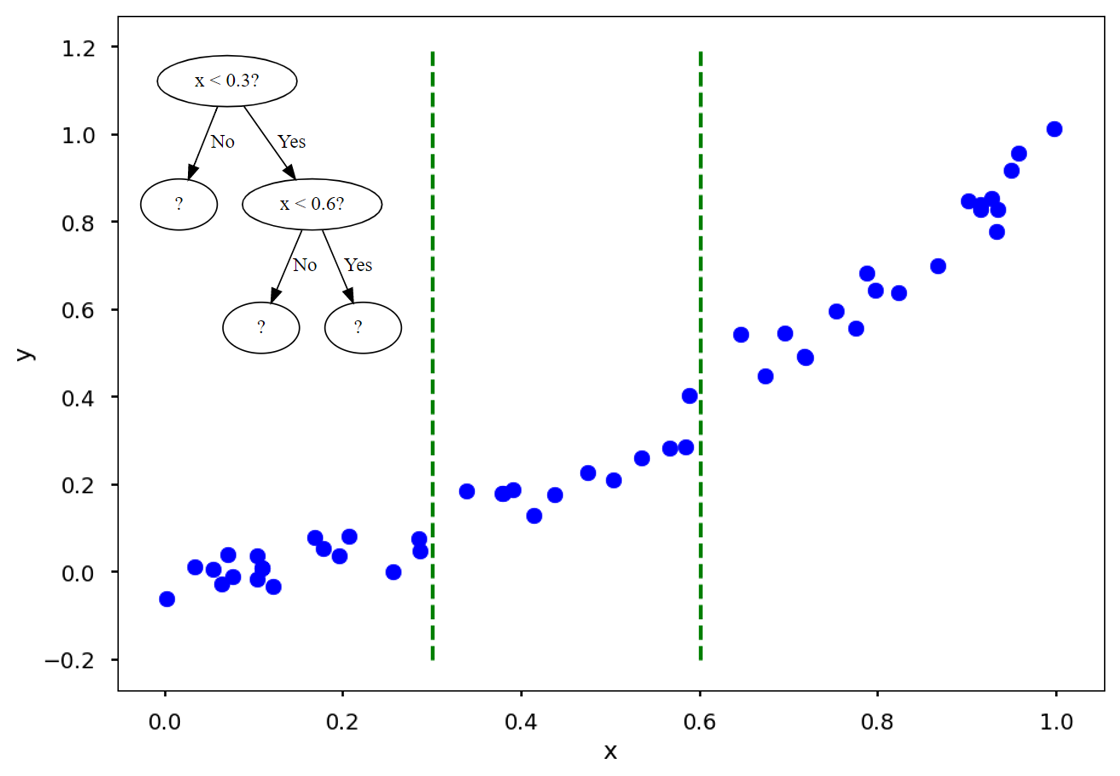
예를 들어 이렇게 과 을 지표로 하는 나무는 두 개의 초록 점선으로 데이터를 나눌 것입니다.
-
그리고는 각 구간의 x값이 들어올 경우, training data (파란 점)의 평균값 (빨간 실선)을 예측값으로 내놓습니다.
- 나무의 깊이가 깊어질수록, 다시 말하면 데이터를 나누는 초록 점선이 촘촘하게 생길 수록 예측값과 실제값의 오차는 줄어들 것입니다.
RSS 정의 (Residual Sum of Squares)
-
실제값과 예측값의 오차는 또는 등으로 표현할 수 있습니다.
-
잔차제곱합(RSS)은 다음과 같습니다.
-
: 번째 영역(region 또는 box)
-
: 영역 내 훈련 데이터의 평균 반응값
-
Binary Tree 분기에서의 MSE 기반 오차 계산
-
특정 분기에서 왼쪽·오른쪽 노드의 오차는 각각 다음과 같이 정의합니다.
-
왼쪽 노드 오차 :
-
오른쪽 노드 오차 :
-
-
각 노드의 샘플 수를 , , 총 샘플 수를 이라 하면, 전체 오차 함수 ( J(k, t_k) ) 는 다음과 같습니다.
Decision Tree의 단점: 과적합에 취약
-
의사결정 나무 알고리즘은 간단하면서 효과적인 알고리즘이지만, 과적합 (Overfitting)에 취약하다는 단점이 존재합니다.
-
만약 Regression의 예시에서 모든 Training data가 개별 구간을 갖도록 의사결정 나무가 생성된다면 이 모델은 과적합된 모델이라고 할 수 있습니다.
- 즉, Training data에 너무 과도하게 학습된 모델입니다.
-
따라서 이러한 과적합을 막기 위해, 가지치기 (pruning) 과정을 수행합니다.
-
알고리즘에 따라 아래 예시와 같이 다양한 방법으로 사전 가지치기 (pre-pruning) 또는 사후 가지치기 (post-pruning)를 하기도 하지만, 단일 모델의 한계점은 여전히 존재합니다.
-
나무의 최대 깊이 (depth)를 제한
-
자식 노드의 최소 샘플 수를 설정
-
impurity/error 의 최소값을 설정
-
impurity/error 변화값의 최소값을 설정
-
이 문제를 해결하기 위해 사람들은 의사결정 나무를 여러개 만들어, 예측 결과를 종합하는 앙상블 (Ensemble) 알고리즘을 고안하였습니다.
