https://tyami.github.io/machine%20learning/decision-tree-3-c4_5/
의사결정 나무 (Decision Tree) C4.5 알고리즘
-
C4.5 알고리즘이 ID3알고리즘에 비해 개선된 점은 아래와 같이 요약할 수 있습니다.
-
정교한 불순도 지표 (Information gain ratio) 활용
-
범주형 변수 뿐 아니라 연속형 변수를 사용 가능
-
결측치가 포함된 데이터도 사용 가능
-
과적합을 방지하기 위한 가지치기
-
개선점 1: 정교한 불순도 지표
-
ID3 알고리즘에서는 각 시점에서 모든 지표에 대한 분기 전후의 엔트로피를 기반으로 Information Gain (IG)을 계산하고, 이를 최대화하는 방향으로 지표를 결정했습니다.
- 하지만 이 알고리즘에는 한계점이 존재합니다.
Information Gain의 한계점
- Windy라는 지표로 분기했을 때 데이터가 위와 같이 분기된다고 가정해봅시다. 이 경우의 Information Gain은 0.5568입니다.
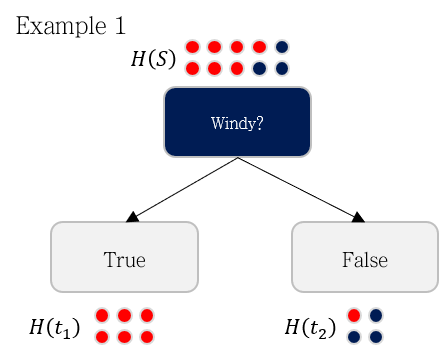
- 다른 지표인 With whom이라는 지표로 분기했을 때는 Information Gain이 0.6813이 나옵니다.
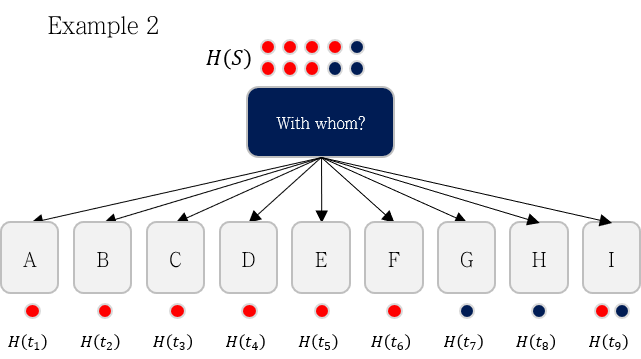
-
두 경우를 비교했을 때, With whom 지표가 더 효과적인 지표라고 말할 수 있을까요?
- With whom 지표는 데이터를 너무 잘게 분해하기 때문에 좋은 지표라고 볼 수 없습니다.
Information Gain Ratio (GR)
-
C4.5 알고리즘에서는 이와 같은 문제를 해결하기 위해, Information Gain Ratio라는 지표를 사용하였습니다.
-
는 ID3 알고리즘에서의 Information Gain을 의미하며,
-
는 Intrinsic Value를 의미합니다.
-
- 특정 지표로 분기했을 때 생성되는 가지의 수를
이라고 하고, 번째 가지에 해당하는 확률을
라고할 때, Intrinsic Value는 아래와 같습니다.
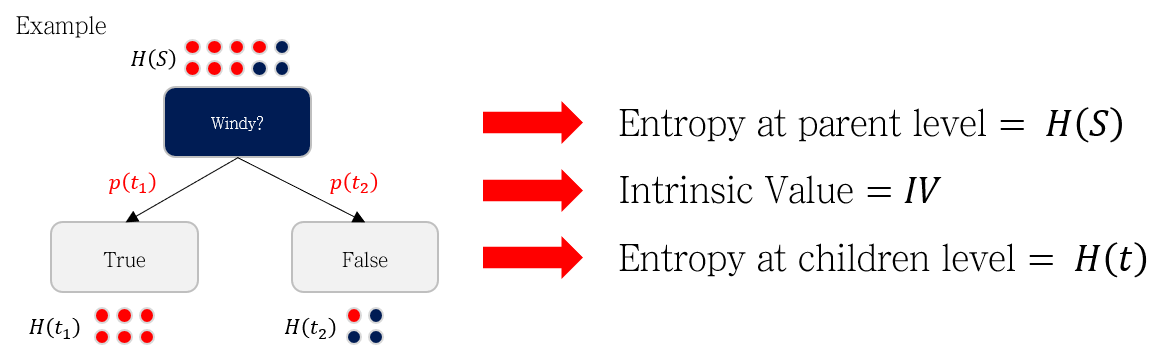
Information Gain Ratio 차이점 예시
예시로 든 두 가지 지표 Windy, With whom에 대한 Information Gain Ratio를 계산하여 차이점을 비교해봅시다.
- Windy 지표에 대한 Information Gain Ratio 계산
- With whom 지표에 대한 Information Gain Ratio 계산
Information Gain을 사용할 때는 두 지표 간 우열이 명확하지 않았지만, Information Gain Ratio(GR)를 사용하면 아래와 같은 결론에 도달한다.
-
Windy 지표의
-
With whom 지표의 $GR = 0.2182#
정리
IG(Information Gain) 과 IV(Intrinsic Value) 은 모양은 비슷하지만 완전히 다른 목적을 가진 두 개념이다.
- IG = 원래 불확실성 − 속성 A로 나눈 뒤 남은 불확실성
- IV는 속성 값의 분포 엔트로피이며 “속성이 본질적으로 얼마나 많은 가지(branch)를 만드는지”를 측정한다.
-
Information Gain (IG)의 계산식
- IG는 “어떤 속성으로 분기했을 때 불확실성이 얼마나 줄어드는가”를 계산한다.
-
(H(S)): 전체 데이터의 엔트로피
-
(H(S, A)): 속성 A로 분기했을 때의 가중평균 엔트로피
- IG는 “어떤 속성으로 분기했을 때 불확실성이 얼마나 줄어드는가”를 계산한다.
-
Intrinsic Value (IV)의 계산식
- IV는 “해당 속성이 데이터를 몇 개의 그룹으로, 얼마나 골고루 나눴는가”를 계산한다.
-
는 각 분기 그룹의 비율
-
클래스 정보(Yes/No 등)는 관여하지 않음
- IV는 “해당 속성이 데이터를 몇 개의 그룹으로, 얼마나 골고루 나눴는가”를 계산한다.
차이 ① 목적이 다름
| 개념 | 목적 |
|---|---|
| IG | 속성이 Play를 얼마나 잘 예측하는가 (정보 감소량) |
| IV | 속성이 데이터를 얼마나 많이/균등하게 쪼개는가 (분할 복잡성) |
차이 ② 계산에서 사용하는 정보가 다름
| 사용 정보 | IG | IV |
|---|---|---|
| Play(Yes/No) 클래스 정보 | 사용됨 | 사용 안 함 |
| 속성 값의 분포 | 2차적으로 고려 | 주요 요소 |
차이 ③ 수식의 구조 차이
IG는 엔트로피 감소량
IV는 속성 분포의 엔트로피
둘을 왜 함께 쓰는가? (ID3 → C4.5 개선)
-
IG만 사용하면 문제가 생김:
-
문제: 값 종류가 많으면 항상 IG가 커짐
- 예) 주민번호, 전화번호 같은 독립된 값 → 모두 다르게 분기 → IG 최대.
-
-
Information Gain Ratio 사용
-
IV가 크면(=분기가 너무 많으면) GR 값은 작아진다.
-
-
GR(Information Gain Ratio)는 IG ÷ IV 로 균형을 맞춘 값이다.
-
IG는 “얼마나 잘 예측하냐”
-
IV는 “얼마나 많이 나누냐”
-
개선점 2: 연속형 변수를 사용 가능
-
C4.5 알고리즘에서의 두번째 개선점은 범주형 변수 (discrete variables)뿐 아니라 연속형 변수 (continuous variables)를 입력값으로 넣을 수 있다는 점입니다.
-
아래 테이블과 같은 데이터가 있다고 생각해봅시다.
Temperature 변수는 연속형 변수입니다.
Temperature Play 36 No 35 No 22 Yes 24 Yes 20 Yes 35 No 31 Yes 30 No 29 Yes 28 Yes 25 Yes 26 Yes 29 Yes 27 No
-
연속형 변수를 어떻게 나누면 될까요? 간단하게 생각해보면 특정 threshold 초과/이하의 값으로 나누면 되겠지요.
-
먼저 데이터를 변수값에 따라 정렬합니다.
-
그 후 Threshold 를 모든 breakpoints로 설정하면서 분기에 따른 불순도를 계산합니다.
-
이후 불순도를 최소화하는 지표를 선택하는 것처럼, 불순도를 최소화하는 threshold를 사용합니다.
-
-
그러면 여기서 breakpoints는 어떻게 정하게 될까요? 여기에는 아래 그림과 같이 크게 세가지 방법이 있습니다.
-
값이 바뀌는 모든 지점을 breakpoints 로 설정
-
Output 클래스가 바뀔 때만 breakpoints로 설정
-
Q1, Median, Q3 값을 breakpoints로 설정
-
방법 1을 예시
모든 지표 X 가능한 모든 breakpoints에 대해 Information Gain을 계산하여 비교한 뒤, 최적의 지표 + 최적의 threshold 조합을 선택하여 분기하면 된다.
위의 모든 threshold 후보들 중에서 가장 큰 Information Gain은 을 갖는
-
따라서 Temperature 지표에서 최적 threshold는 33도이다.
-
모든 지표 X 모든 breakpoints에 대해 Information Gain을 계산하여 비교한 뒤, 최적의 지표 X breakpoints 조합을 찾아 분기를 진행하면 됩니다.
개선점 3: 결측치가 포함된 데이터 사용 가능
-
C4.5 알고리즘의 세번째 개선점은 결측치가 포함된 데이터에도 사용이 가능하다는 것입니다.
-
아래와 같은 데이터가 있다고 생각해봅시다.
Outlook Play Sunny No No Yes Rain Yes Rain Yes Rain No Overcast Yes No Yes Yes Yes Overcast Yes Overcast Yes Rain No
-
Weighted Informaiton Gain
-
결측값(missing value)이 있는 경우, 속성 A의 실제 기여도를 반영하기 위해 Weighted Information Gain을 사용한다.
-
14개의 데이터 샘플 중 6개 샘플에 대해서는 Outlook 변수의 값이 결측치 (missing value)로 되어있는 상태입니다.
- 일반적으로는 이런 경우 분기 자체가 불가능하지만, C4.5 알고리즘에서는 이 문제를 Information Gain 을 계산하는 수식에 약간의 변화를 주어 해결했습니다.
-
Entropy는 Non-missing value로만 계산
-
Information Gain는 Weighted Information Gain로 변경
- IG(S,A): 원래의 Information Gain
- F: 해당 속성 A에서 실제로 값이 존재하는 비율
- 따라서 결측치가 많을수록 F가 작아져 그 속성이 트리에 미치는 영향도 줄어든다.
-
Intrinsic Value는 missing value를 하나의 클래스로 보고 모든 데이터로 계산
예시
1단계: Entropy는 Non-missing value로만 계산
2단계: Information Gain → Weighted Information Gain 계산
결측값이 있는 경우
3단계: Intrinsic Value 계산
Missing value를 하나의 클래스로 보고 총 4개의 클래스(sunny=1, rain=4, overcast=3, missing=6)로 계산한다.
개선점 4: 과적합을 방지하기 위한 가지치기
- 의사결정 나무가 깊어질수록, training data에 대해서는 잘 분류하지만, 새로운 종류의 데이터 (test data)는 잘 분류하지 못하는 과적합 (overfitting) 문제가 발생하게 됩니다.
가지치기 (Pruning)
-
의사결정 나무가 너무 깊어지지 않도록 중간에 노드를 잘라주는 가지치기 (pruning) 과정이 필요합니다.
-
가지치기에는 사전 가지치기(pre-pruning)와 사후 가지치기(post-pruning) 과정이 있습니다.
-
사전 가지치기: 의사결정 나무를 완성하기 전에 가지치기를 수행합니다
-
사후 가지치기: 의사결정 나무를 완성한 후에 가지치기를 수행합니다.
-
이 중, C4.5 알고리즘에서는 사후 가지치기 알고리즘을 적용했습니다.
사후 가지치기 (Post-pruning)Permalink
-
Data segmentation 사후 가지치기는 의사결정 나무가 완성된 후에 가지치기를 진행하는 방식입니다.
- 따라서 데이터를 training/test 데이터가 아니라 training/pruning/test 데이터로 나눕니다.
-
Complete decision tree with training data Training data만으로 의사결정 나무를 만듭니다.
-
Pruning with test data Pruning data로 가지치기를 수행합니다.
-
상위 노드부터 차례차례 e값을 계산합니다.
-
자식노드들의 e값의 weighted sum 값과 부모노드의 e 값을 비교합니다.
-
만약 부모노드의 e값이 더 작다면, 해당 분기는 진행하지 않고 가지치기를 수행합니다.
-
-
- Prediction with test data 완성된 pruned decision tree를 이용해 Test data 에 대한 결과를 예측합니다.
