논리 흐름과 정보의 배치
오픈AI의 챗GPT는 약 1만여 개의 GPU(Graphic Processing Unit)로 사용자의 질문에 대한 연산을 처리한다. GPU 기반 AI 연산 체계는 초기 도입비, 설계가 쉬운 장점이 있지만, 막대한 전력과 운영비용이 단점으로 지적된다. 특히, 점점 커지는 AI 모델과 데이터셋으로 연산량이 폭증하면서 높은 전력소모와 비용이 업계의 큰 고민이 되고 있다.
A. 문제 제기
- 챗GPT 등 대형 AI는 GPU 사용 중심, 고비용·고전력 문제 부상
B. GPU 기반 → NPU로 변화
-
GPU 고전력 한계, NPU 등 AI 특화 반도체 필요성 부각
-
NPU의 장점: 분산병렬처리, 저전력
C. NPU와 AI 반도체의 세대 구분
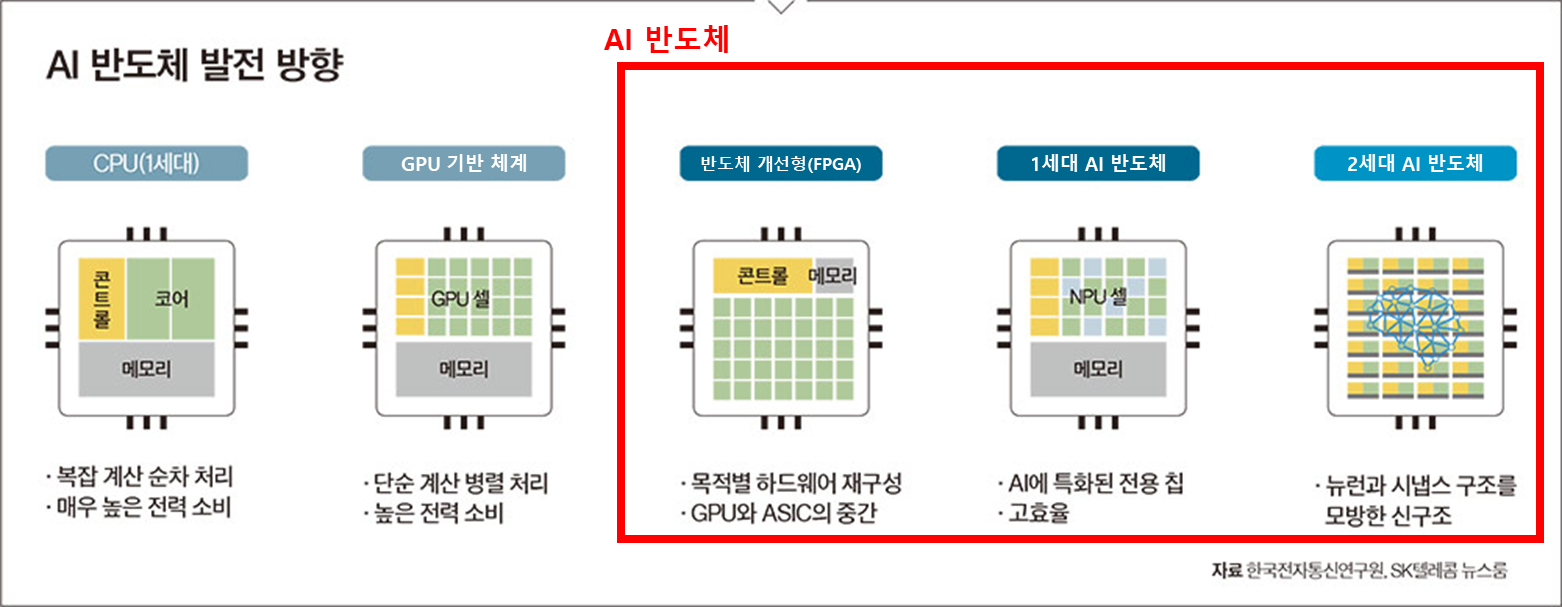
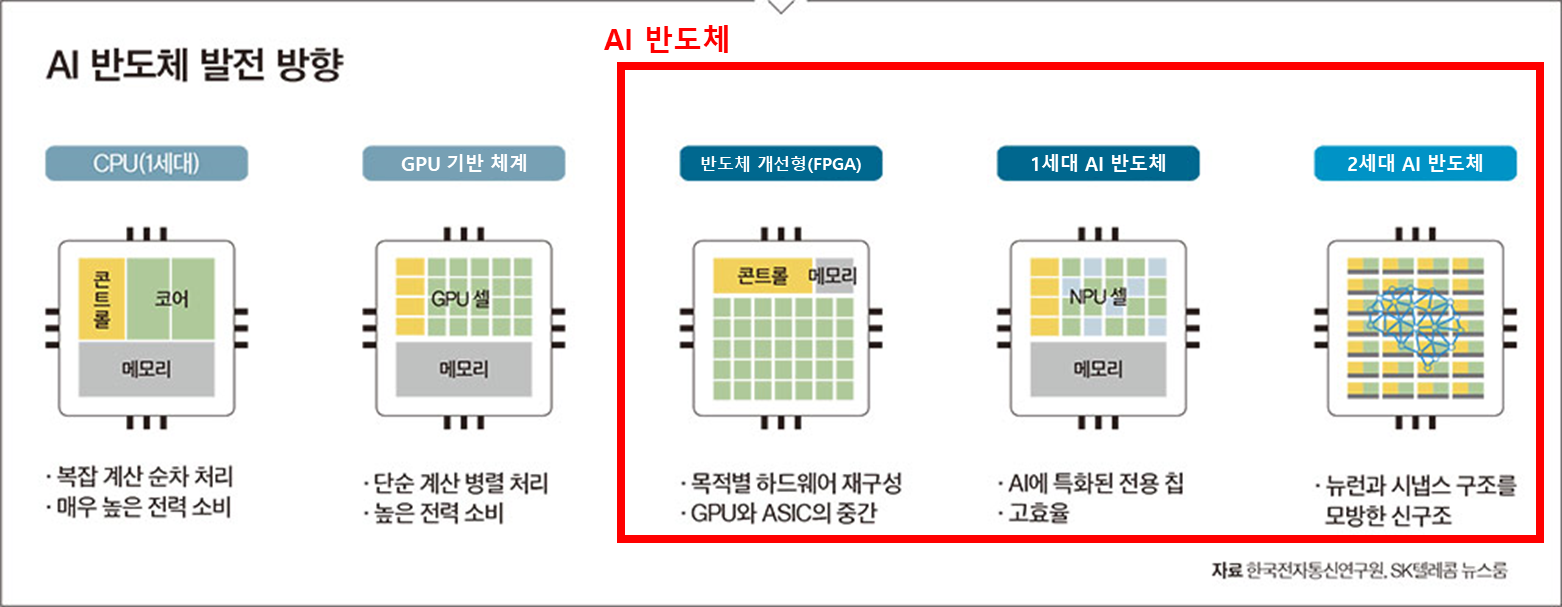
① 기존 개선형 (CPU, GPU, FPGA 등)
② 1세대 AI 반도체 (맞춤형, 고성능·저전력, 가격은 높음)
③ 2세대 AI 반도체 (비(非) 폰노이만, 범용성, 저비용·저전력)
| 기존 개선형 | 1세대 AI 반도체 | 2세대 AI 반도체 | |
|---|---|---|---|
| 핵심특징 | 범용 CPU, GPU, FPGA 기반 | 맞춤형(ASIC/SoC) AI 특화, 고성능 | 비(非) 폰노이만, 메모리컴퓨팅, 범용성 |
| 대표 기업/제품 | NVIDIA GPU Intel CPU Xilinx FPGA | 구글 TPU(1~3rd gen) 모빌린트 ARIES 텐실리카 DNA 삼성 NPU(엑시노스 IP) | 삼성 PIM(Processing-In-Memory) SK하이닉스 AiM 모빌린트 REGULUS IBM TrueNorth(뉴로모픽) |
| 구현 방식 | 범용 병렬·일반 로직 연산 | AI 연산구조 최적화 ASIC | 메모리 직접 연산, 신경망 모방 등 |
| 예시 | NVIDIA A100/H100/GH200 Intel Xeon Xilinx Versal | Google TPU(Tensor Processing Unit, v1-3) 모빌린트 ARIES Cerebras WSE-2 | 삼성 PIM(HBM-PIM 등) SK hynix AiM 모빌린트 REGULUS |
| 기타 | 범용성·유연성 우위, 전력효율 낮음 | 연산·전력효율 우수, 맞춤형(범용성↓) | 차세대 혁신, 전력·성능 혁신 기대 |
NVIDIA의 고성능 GPU/AI 칩은 어디?
- NVIDIA의 주요 고성능 AI 칩(GPU 기반)들은 “① 기존 개선형”에 해당합니다.
- NVIDIA의 A100, H100, 등은 “GPU 기반”이지만 AI에 최적화된 추가 하드웨어(텐서코어 등)를 내장한 범용 GPU
- 본질적으로 GPU(그래픽처리장치)의 연산 구조를 극단적으로 확장·개량한 것 → CPU·GPU 개선형에 가까움
- FPGA처럼 범용 프로그래밍 가능, 다양한 AI모델(딥러닝, HPC 등)에 적합
- 실제로 현재 LLM, 챗GPT 등 거대 AI 회사들이 사용하는 것은 이 ‘고성능 GPU’(한 세대 전이라면 FPGA도 있음)입니다.
※단,NVIDIA는 최근 “특화 AI 가속기”, 즉 특정 AI 연산에 초점 맞춘 칩(예: 텐서RT, 도메인 특화 ASIC 등)도 개발하지만 업계에서 일반적으로 “NVIDIA AI 칩”이라고 할 때는 ① 기존 개선형에 분류됩니다.- 2세대 AI 반도체(비(非) 폰노이만)와의 차이
- NVIDIA의 주력 제품군은 아직까지 기존의 “폰 노이만”(CPU, GPU 구조 기반)의 한계를 극복하는 것보다는 그 구조 내에서 병렬성과 효율을 극대화한 형태입니다.
D. 국내 AI 반도체 기업 사례
-
모빌린트: ARIES(1세대), REGULUS(2세대, 5W 이하 구동)
-
딥엑스: DX-M1(전력소모 20배↓, 제조비용↓)
-
사피온: X330(연산 4배↑, 전력 2배 효율↑, SKT AI 팜에 적용)
E. 정부 정책 (2024년 1월)
- K클라우드: 국산 AI 반도체 개발, 데이터센터 적용, 대규모 투자(8262억/2030년까지)
F. 글로벌 트렌드
- 오픈AI, 구글, 메타, 애플 등 글로벌 기업 격전
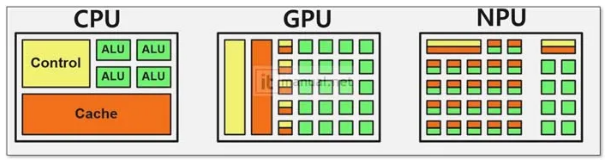
CPU(중앙처리장치) 기본 구조도
CPU는 일반적으로 아래와 같은 주요 구성요소로 이루어집니다.
------------------------------
| CPU |
|-----------------------------|
| 연산장치(ALU) |
| 제어장치(Control Unit) |
| 레지스터(Register) |
| 캐시 메모리(Cache) |
|-----------------------------|
| BUS |
-------------------------------
ALU(산술논리연산장치): 연산 수행
-
Control Unit(제어장치): 명령을 해석하고 제어
-
Register(레지스터): 임시 저장 공간
-
Cache(캐시): 고속 메모리로, 주기억장치와 CPU 속도 차이 해소
GPU(그래픽처리장치) 기본 구조도
GPU는 병렬처리에 최적화된 구조로, 여러 개의 코어와 스트림 프로세싱 유닛을 가지고 있습니다.
------------------------------------------
| GPU |
|------------------------------------------|
| 여러개의 SM(Stream Multiprocessor) |
| └─ 여러개의 CUDA Core/ALU |
| 제어장치(Control Unit) |
| 레지스터(Register File) |
| 공유메모리(Shared Memory) |
| 글로벌 메모리(Global Memory) |
|------------------------------------------|
| BUS |
-------------------------------------------
SM(스트림 멀티프로세서): 다수의 연산 유닛(코어) 묶음
-
CUDA Core/ALU: 실제 연산 수행 (Nvidia GPU 기준)
-
Shared Memory: SM 내에서 데이터 공유
-
Global Memory: GPU 전체에서 접근하는 주기억장치
NPU(뉴럴처리장치) 기본 구조도
NPU는 AI 연산에 특화된 각종 연산 유닛으로 구성됩니다.
------------------------------------------
| NPU |
|------------------------------------------|
| 매트릭스 연산 유닛(Matrix Unit) |
| 컨볼루션 유닛(Convolution Unit) |
| 활성화/정규화 유닛(Activation/Norm) |
| 메모리 컨트롤러(Memory Controller) |
| 버퍼(Buffer) |
|------------------------------------------|
| BUS |
-------------------------------------------
Matrix Unit/Convolution Unit: AI 연산 (행렬 곱/합성곱) 전용 하드웨어
-
Activation/Norm: 비선형 연산, 정규화 연산 전용 블록
-
Memory Controller/Buffer: 대용량 연산 데이터 임시 저장
