1. 인코딩의 개념
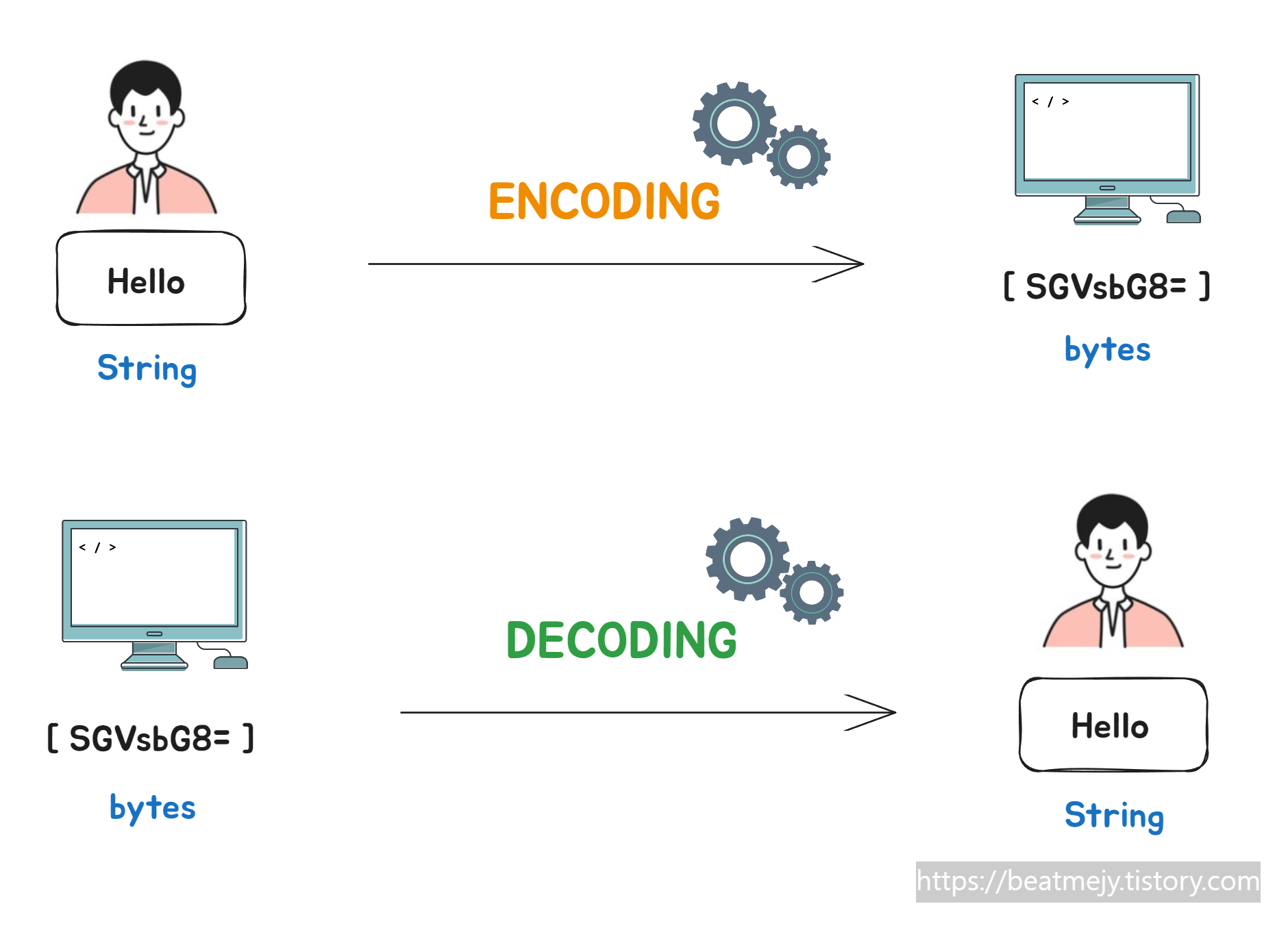
인코딩은 문자를 컴퓨터가 처리할 수 있도록 바이트(byte) 로 변환하는 규칙이다.
-
문자 → 바이트 : encode
-
바이트 → 문자 : decode
한국어 환경에서 가장 중요한 인코딩은 다음 세 가지다.
-
UTF-8
-
EUC-KR
-
CP949(MS949)
2. UTF-8
특징
-
유니코드 기반 전 세계 문자 표현 가능
-
가변 길이 인코딩(1~4 byte)
-
현대 시스템의 기본 표준
-
이모지 및 특수문자 지원
실무 장점
-
다국어 안전
-
웹, DB, API 기본 인코딩
-
Python의 기본 인코딩도 UTF-8
예시
s = "안녕하세요"
b = s.encode("utf-8")
print(b)3. EUC-KR
특징
-
과거 한국어 표준 인코딩
-
1~2 byte
-
표현 가능한 글자 수가 제한적(약 2,350자)
단점
-
확장 한글, 신조어 등을 표현하지 못함
-
UTF-8과 호환성이 낮음
4. CP949(MS949)
특징
-
Microsoft가 EUC-KR을 확장한 한국어 인코딩
-
EUC-KR의 상위호환
-
표현 가능한 한글 약 8,822자
-
윈도우에서 가장 흔하게 사용
-
공공기관 CSV/엑셀 파일에서 자주 등장
문제를 일으키는 이유
-
EUC-KR과 유사하지만 동일하지 않음
-
UTF-8 파일을 CP949로 읽으면 글자가 깨짐
-
CP949 파일을 UTF-8로 읽어도 마찬가지로 깨짐
5. 글자 깨짐이 발생하는 원리
깨짐의 원인은 단순하다.
-
원래 UTF-8 데이터를 CP949로 decode
-
원래 CP949 데이터를 UTF-8로 decode
encode 방식과 decode 방식이 다르면 글자가 깨진다.
6. 실무에서 가장 흔한 깨짐 상황
1) UTF-8 파일을 CP949로 읽었을 때
open("data.csv", encoding="cp949")2) 공공기관 CSV(대부분 CP949)를 UTF-8로 읽었을 때
open("data.csv", encoding="utf-8")3) 크롤링(API) 데이터는 UTF-8인데 엑셀에서 열면 CP949로 해석하는 경우
7. 어떤 인코딩을 언제 사용할까?
기본 규칙
- 기본/권장 인코딩: UTF-8
예외 상황
- 공공기관/정부 사이트에서 내려받은 CSV는 대부분 CP949
pd.read_csv("file.csv", encoding="cp949")8. 파일 인코딩 자동 감지
어떤 인코딩인지 확신이 없을 때:
import chardet
with open("file.csv", "rb") as f:
print(chardet.detect(f.read()))출력 예시:
{'encoding': 'EUC-KR', 'confidence': 0.99}9. 잘못 디코딩된 문자열 복원 방법
CP949로 잘못 디코딩된 UTF-8 문자열 복원
value.encode("cp949").decode("utf-8")UTF-8로 잘못 디코딩된 CP949 문자열 복원
value.encode("utf-8").decode("cp949")복원의 핵심은 깨진 문자열의 현재 상태를 기준으로 encode → decode 순서를 역추적하는 것이다.

All views expressed here are solely my own and do not represent those of any affiliated organization.