- CPU: 모든 시스템의 중심이 되는 범용 연산 장치
- GPU: 대규모 병렬 연산의 강자
- TPU: AI 시대를 위한 전용 가속기
- 목적과 특성에 따라 세 장치는 서로 보완적으로 활용됨
CPU(Central Processing Unit) - 범용 컴퓨팅의 중심
-
CPU(Central Processing Unit)는 컴퓨터의 핵심 두뇌로, 운영체제의 실행부터 소프트웨어 명령 처리, 입출력 제어까지 대부분의 일반 연산을 담당한다.
- 일반적으로 Intel Core 시리즈, AMD Ryzen 시리즈 등을 통해 쉽게 접할 수 있다.
역할
-
운영체제와 각종 프로그램 실행
-
논리적 분기 처리 및 복잡한 연산
-
I/O 관리 및 다양한 하드웨어 제어
장점
-
높은 범용성: 거의 모든 연산을 처리 가능
-
강력한 단일 코어 성능: 복잡한 순차·분기 연산에 우수
-
모든 컴퓨팅 환경에 필수적으로 존재
단점
-
병렬 연산에 제한 → 소수의 고성능 코어 중심
-
대규모 데이터 처리에서는 효율 및 속도 한계
GPU(Graphics Processing Unit) – 대규모 병렬 연산의 대표 주자
-
GPU(Graphics Processing Unit)는 수천 개의 작은 코어로 구성되어, 반복적이고 대규모 병렬 연산에 특화된 장치이다.
-
게임·그래픽 렌더링뿐 아니라 영상 처리, 시뮬레이션, AI 연산 등 현대 컴퓨팅에서 중요한 역할을 한다.
역할
-
3D 그래픽 렌더링
-
병렬 기반 행렬 연산 및 시뮬레이션
-
AI·머신러닝 모델 학습 가속
장점
-
강력한 병렬 처리 능력: 수천 개 코어가 동시에 작업 수행
-
그래픽뿐 아니라 과학, 금융, AI 등 다양한 분야에서 활용
-
AI/ML 학습에서 사실상 표준 가속기 역할
단점
-
분기 중심의 순차 연산에는 비효율적
-
전력 소모 및 발열이 크며 냉각이 필요
-
CPU 없이 독립적인 시스템 구성 어려움
TPU(Tensor Processing Unit) – 딥러닝 전용 가속기
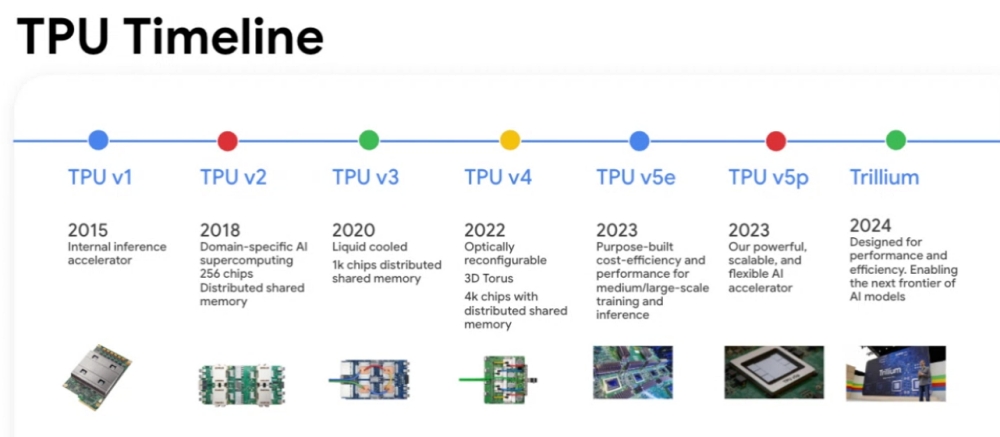
-
TPU(Tensor Processing Unit)는 Google이 개발한 딥러닝 전용 ASIC으로, 이름 그대로 대규모 Tensor(행렬·벡터) 연산에 최적화되어 있다.
-
대형 신경망의 학습·추론을 기존 CPU나 GPU보다 높은 속도와 효율로 처리하도록 설계되었다.
역할
-
딥러닝 모델 학습 및 추론 가속
-
대규모 행렬 연산 처리
-
Google Cloud 기반 AI 서비스 최적화
장점
-
AI 특화 성능: GPU보다도 빠르게 동작하도록 설계된 전용 구조
-
전력 효율 우수: 동일 성능 대비 에너지 사용 감소
-
TPU Pod 구성으로 확장성 확보
단점
-
범용성 부족: AI 외의 응용 분야에서는 활용 어려움
-
주로 Google Cloud 기반에서만 접근 가능
-
TensorFlow 중심 최적화 → 타 프레임워크와의 호환성 제한
TPU가 중요한 이유
-
ChatGPT 같은 대규모 언어 모델, 자율주행, 이미지 인식, 추천 시스템 등 AI 기술은 방대한 양의 행렬 연산을 요구한다.
-
GPU가 AI 발전을 이끈 ‘범용 병렬 엔진’이었다면, TPU는 딥러닝 전용 엔진으로 더 높은 효율과 전력 절감을 제공한다.

비유로 보는 CPU · GPU · TPU
-
CPU = 총괄 매니저 / 헤드셰프
-
어떤 작업이든 가능하나, 혼자 처리하므로 속도에 한계
-
전체 시스템 흐름을 조율하는 역할
-
-
GPU = 대규모 조리 인력팀
-
단순·반복 작업을 빠르게 처리
-
병렬 작업에 최적화되어 대량의 동일 연산을 수행
-
-
TPU = 특정 작업을 위한 자동화 기계
-
특정 연산(행렬 연산)에만 특화
-
범용성은 부족하지만 해당 작업만큼은 가장 빠르고 효율적
-
TPU 시대를 위한 과제
TPU가 차세대 AI 가속기로 자리 잡기 위해서는 다음과 같은 발전이 필요하다.
-
범용성 확대: TensorFlow 중심에서 벗어나 PyTorch 등 다양한 프레임워크 지원
-
개발자 접근성 강화: Google Cloud 외 환경에서 활용 가능성 확대
-
에너지 효율 향상: 거대 모델 증가 추세에 따라 전력 관리 최적화 필요
