추천 시스템 복습
user_NN = tf.keras.models.Sequential([
tf.keras.layers.Dense(256, activation='relu’),
tf.keras.layers.Dense(128, activation='relu’),
tf.keras.layers.Dense(32)])
# 세 개의 Dense layer를 결합한 것
# 기본적으로 ReLu 함수를 많이 씀
item_NN = tf.keras.models.Sequential([
tf.keras.layers.Dense(256, activation='relu’),
tf.keras.layers.Dense(128, activation='relu’),
tf.keras.layers.Dense(32)])
# create the user input and point to the base network
input_user = tf.keras.layers.Input(shape=(num_user_features))
vu = user_NN(input_user) # vu라는 레이어를 정의; inputUser를 연결하고(붙이고) vu라고 정의
vu = tf.linalg.l2_normalize(vu, axis=1)
# normalize |vu| to 1 (학습을 잘하기 위해서 배치하는 것)
# create the item input and point to the base network
input_item = tf.keras.layers.Input(shape=(num_item_features))
vm = item_NN(input_item)
vm = tf.linalg.l2_normalize(vm, axis=1) # normalize |vm| to 1
# measure the similarity of the two vector outputs
output = tf.keras.layers.Dot(axes=1)([vu, vm]) # special layer
# specify the inputs and output of the model
model = Model([input_user, input_item], output)
# Specify the cost function
cost_fn = tf.keras.losses.MeanSquaredError()
| 1의 방향 | ||
|---|---|---|
| 0의 방향 | 0 | 0 |
| 0 | 0 |
강화학습 복습
머신러닝의 세 가지 기둥
- supervised learning (x를 넣었을 때 y가 나오도록 하는 방식을 찾도록)
- unsupervised learing (스스로 패턴을 학습하도록)
- Reinforcement learning (y를 정의하기 어렵기 때문에 reward를 주는 것)
왜 강화학습인가?
- 일일히 y를 알려주기 어려울 정도로 많은 경우가 존재할 때
- reward를 잘 설정하면, 스스로 잘 깨달을 수 있음
강화학습의 용어
- State S : 여러 가지 상황
- Action a : 우리가 알고 싶은 것 (이 state가 있을 때, 적절한 a는 무엇인가?)
- Task : s와 a를 매칭하는 함수
- Reward : 각각의 상태에 대해 좋은 상태인지(positive), 아닌지(negative) 알려줄 수 있음
(S, a) pair : 너무 많은 경우가 있어서 하나하나 정의하기 어려움
R(s) : 이 경우에는 가능함!
- 각 state가 바람직한 상황인지 알려줌
- 일일히 정확한 y를 알려주지 않아도, (optimal action을 정의하지 않아도) 스스로 a를 찾아낼 수 있음

화성 탐험 예제
-
1번 state는 유용한 광물이 많다고 판단, reward 100 지정
-
6번 state는 1번 만큼은 아니라고 판단, reward 40 지정
-
action : 가능한 동작(행동)들을 정의함. 이 예제에서는 left, right
-
S에 대해서 어떤 action을 취해야 할 지 학습함
-
reward는 state마다 주어짐
-
reward를 어떻게 합칠지 (state별로 reward가 달라지기 때문에) 문제인데 가장 기본적인 것 중 하나는 뒤로 갈 수록 reward를 (가치를) 떨어뜨림
S -[a선택]-> S'로 바뀜 -[b선택-]> S''로 바뀜 -[a선택]-> S''' -
𝑠: a state
𝑎: an action
𝑅(𝑠) : the reward from the state 𝑠
𝑠' : a new state resulting from the action a
chapter 03 The Return in Reinforcement Learning
The concept of a return
- Rewards you can get quicker are maybe more attractive than rewards that take you a long time to get to
- (ex) a 5-dollar bill now vs. a 10-dollar bill after 1 hour
- 1억을 지금 받아서 은행에 넣고 예금 이자 받기 vs 1억 1년 뒤 받기
Return
- 강화 학습에서 반환은 보상들의 합을 할인 계수로 가중치를 주어 정의
- Return = 𝑅1 + 𝛾𝑅2 + 𝛾^2𝑅3 + ⋯ (until terminal state)
- 𝑅𝑖 : the reward on the 𝑖th step
- 𝛾: a discount factor (a number less than 1) (e.g., 0.9, 0.99, or even 0.999)
이러한 모습을 Discount Factor(지금 얻는 것과 나중에 얻는 것이 달라질 때)라고 함 (이러한 개념이 통하는 경우가 많음. 만약 전부 1로 결정할 경우 solution이 수렴되지 않는 경우가 종종 있음)
Discount factor
- 𝑅1 + 𝛾𝑅2 + 𝛾^2𝑅3 + ⋯
- 𝛾 has the effect of making the reinforcement learning algorithm a little bit impatient
- 첫 번째 보상은 완전한 가산점, 뒤로 갈 수록 조금씩 더 적은 가산점
- 더 빨리 보상을 받을 수록 전체 return 값음 더 높아짐
- 해석해보자면, 𝛾(감마)는 이자율이나 시간 가치를 나타낼 수 있음
- 만약 당신이 오늘 1달러를 가질 수 있다면, 미래에 1달러를 받는 것보다 조금 더 가치 있을 수 있음
- 𝛾는 미래의 1달러가 오늘의 1달러에 비해 얼마나 덜 가치 있는지를 나타냄
우리의 목표는 어떤 state에서 출발하든 return을 높이고 싶은 것
State: 4 → 5 → 6 ➔ return = 0 + (0.5)0 + (0.5)240 = 10
– State: 5 → 6 ➔ return = 0 + (0.5)40 = 20
– State: 6 ➔ return = 40
– State: 3 → 4 → 5 → 6 ➔ return = 0 + (0.5)0 + (0.5)20 + (0.5)340 = 5
– State: 2 → 3 → 4 → 5 → 6 ➔ return = 0 + (0.5)0 + … + (0.5)440 = 2.5
– State: 1 ➔ return = 100
Examples (𝛾 = 0.5)
– State: 1 ➔ return = 100
– State: 2 → 1 ➔ return = 0 + (0.5)100 = 50
– State: 3 → 2 → 1 ➔ return = 0 + (0.5)0 + (0.5)2100 = 25
– State: 4 → 3 → 2 → 1 ➔ return = 0 + (0.5)0 + (0.5)20 + (0.5)3100 = 12.5
– State: 5 → 6 ➔ return = 0 + (0.5)40 = 20
– State: 6 ➔ return = 40
summary
강화 학습에서의 반환(Return)
- discount factor에 따라 가중치를 주어 얻는 보상의 합
- positive 긍정적 보상 : 시스템에게 긍정적인 보상을 가능한 빨리 얻도록 자극
- negative 부정적 보상 : 시스템에게 부정적인 보상을 가능한 미래로 미루도록 자극
- 이제 강화학습 알고리즘의 목표를 공식화해보자!
chapter 04 : Making Decisions: Policies in Reinforcement Learning
어떤 action을 취해야 가장 return이 높아질까?
Formalization of Reinforcement Learning (강화 학습 알고리즘이 어떻게 행동을 선택하는지를 공식화)
- 강화 학습 문제에서 행동을 취하는 여러 방법
- 예를 들어, 항상 더 가까운 보상을 선택 or 항상 더 큰 보상을 선택
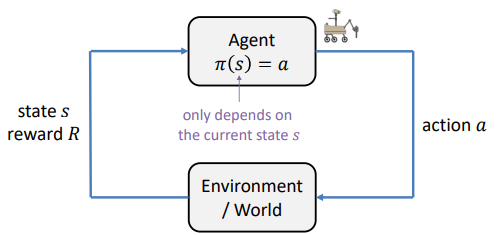
- 목표 : policy 𝝅(𝒔) = a라고 불리는 정책(policy)를 찾는 것 ; 어떤 상태 𝑠를 입력으로 받아서 취해야 할 행동 𝑎로 매핑하는 역할
policy
- 각 state에서 어떤 action을 취할지 나타내는 것 (=주어진 상태에서 취할 행동 𝑎를 알려주는 함수)
- 모두 왼쪽으로 가는 policy, 모두 오른쪽으로 가는 policy, 왼쪽으로 갔다가 오른쪽으로 가는 policy
- Find a policy 𝝅(𝒔) = 𝒂 that tells you what action 𝑎 to take in every state 𝑠 so as to maximize the return (반환을 최대화하기 위해 모든 상태 𝑠에서 취해야 할 행동 𝑎를 알려주는 정책 찾기!)
- return을 최대화하는 것을 policy
chapter 05 : Review of Key Concepts
Quick Review of Key Concepts
- return : discount factor를 통해
- 실제 문제는 state가 real number로 된 vector로 옴 & action도 굉장히 다양함
Markov Decision Process (MDP)
강화 학습의 형식화는 마르코프 결정 프로세스에 기반
- 미래가 현재 상태에만 의존하며 현재 상태에 이르기까지 발생한 것과는 무관하다는 것을 의미 (Refers to that the future only depends on the current state and not on anything that might have occurred prior to getting to the current state)
- 즉, 미래는 당신이 어디에 있는지에만 의존하며 여기에 도달하는 방법에는 의존하지 않음 (i.e., the future depends only on where you are, not on how you got here)
- 어떤 시점에서 다음을 예측할 때는 과거는 상관 없이, 현재(지금 상태)만 고려하겠다
마르코프 결정 프로세스(Markov Decision Process, MDP)는 강화 학습에서 사용되는 수학적인 프레임워크. 이는 순차적인 의사 결정 과정을 모델링하는데 사용. MDP는 다음과 같은 주요 요소로 구성:
상태(State): 시스템이 존재할 수 있는 상황이나 조건
행동(Action): 에이전트가 특정 상태에서 취할 수 있는 선택지
보상(Reward): 특정 상태에서 특정 행동을 취했을 때 주어지는 보상
상태 전이 확률(State Transition Probability): 에이전트가 특정 상태에서 특정 행동을 취했을 때 다음 상태로 이동할 확률
MDP는 마르코프 속성을 따름. 이는 미래 상태의 예측이 현재 상태에만 의존하며, 과거의 모든 행동이나 상태 변화는 현재 상태로부터 예측하는 데 필요하지 않다는 것을 의미
chatper 06 : State-Action Value Function Definition
지금 state에서 어떤 action을 취하면 어떤 reward가 들어오는지
State-Action Value Function (Q-Function)
- 강화 학습 알고리즘이 계산하는 주요 key quantity (A key quantity that reinforcement learning algorithm computes)
- The state-action value function 𝑸(𝒔, 𝒂) = 𝑹𝒆𝒕𝒖𝒓𝒏 if you
- s에서 어떤 action을 취했을 때, 가장 최선으로 행동해서 얻을 수 있는 최대의 return치
- 상태 𝑠에서 시작하여 행동 𝑎를 취한 후 최적으로 행동한다면 가장 높은 반환을 얻을 수 있는 행동을 취함
- 상태 𝑠에서 행동 𝑎를 취했을 때 얻을 수 있는 최대 반환(Start in state 𝑠 and take action 𝑎 and then behave optimally after that)
- Tells what is your highest possible return if you take action 𝑎 in state s
- 하지만 최적의 행동이 무엇인지 어떻게 알 수 있을까? (But how do we know what is the optimal behavior?)
- 모든 상태에서 취해야 하는 최상의 행동을 알고 있다면, 왜 여전히 𝑄 𝑠, 𝑎를 계산해야 할까? 왜냐하면 이미 최적 정책이 있기 때문임
- 나중에, 우리는 최적 정책을 찾기 전에도 𝑄(𝑠, 𝑎)를 계산하는 방법을 찾아낼 것
- 𝑄(2, →) = 0 + (0.5) 0 + (0.5)^2 0 + (0.5)^3 100 = 12.5
- 𝑄(2, ←) = 0 + (0.5) * 100 = 50
- 𝑄(4, ←) = 0 + (0.5) 0 + (0.5)^2 0 + (0.5)^3 100 = 12.5
- 어떻게든 Q(s,a)를 얻게 되면 이것이 즉 policy가 되는 것!! (각 state에서 Q(s,a)를 최대화하는 것을 찾음
- 각 state에 대해서 모든 Q(s,a)값을 구한 다음 최적의 policy를 선택
- The best possible return from state s is max Q(s,a)
- The best possible action in 𝑠 is the action 𝑎 that gives max Q(s,a)
- 상태 s에서의 최상의 return은 max Q(s,a)입니다.
상태 s에서의 최상의 action은 max Q(s,a)를 주는 행동 𝑎
Using Q(s,a)
- 모든 상태 𝑠와 모든 행동 𝑎에 대해 Q(s,a)를 계산하는 방법이 있다고 가정 (딥러닝 등)
- 어떤 상태 𝑠에 있다면 다양한 행동 𝑎를 살펴보기만 하면 됨
- Q(s,a)를 최대화하는 행동 a를 선택하면 되는 것
- status 𝑠에서의 최적 정책 𝜋(𝑠)는 Q(s,a)를 최대화하는 행동 a
- 가장 큰 biggest possible returnn 을 얻기 위해서는 가장 큰 biggest total return을 가져다 주는 행동 𝑎
chapter 07 : Bellman Equation 🪄 (가장 중요)
What is the Bellman Equation?
지금까지 공부한 것을 다시 정리해보자
만약 상태-행동 가치 함수 𝑄(𝑠, 𝑎) 를 계산할 수 있다면, 각 상태 𝑠에서 좋은 행동 𝑎를 선택할 수 있는 방법을 제공 (단순히 𝑄(𝑠, 𝑎) 값이 가장 큰 행동 𝑎를 선택)
어떻게 𝑄(𝑠, 𝑎)를 계산할까? 벨만 방정식!
