[1] 모델 선정 과정
모델
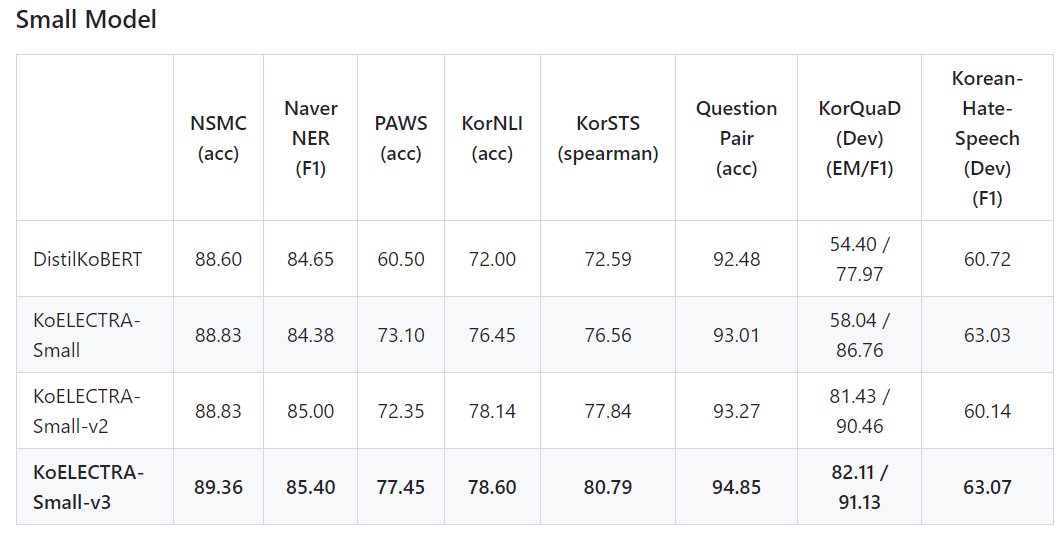
- KoBERT : 최근 프로젝트에서 가장 많이 사용되는 모델. Vocab size가 8002개로 상대적으로 작음
- HanBert : Tokenizer로 인해 Ubuntu 환경에서만 사용 가능
- ✔️ KoELECTRA : 한국어 문제에 적합하도록 ELECTRA 모델을 fine-tuning한 것을 가리키는 특별한 모델로 기존의 BERT와 같은 MLM 학습이 아닌Generator(G), discriminator(D)를 이용한RTD(Replaced Token Detection) pre-training 학습 방법을 사용
[2] 기초 개념
📖 Tokenization
Wordpiece Vocabulary에 관한 깃허브 링크
토크나이제이션(tokenization) : 자연어 처리에서 텍스트를 작은 단위로 나누는 과정
작은 단위는 주로 토큰(token)이라고 불리며, 문장이나 문서를 이러한 토큰들의 집합으로 분해. 목적은 주어진 텍스트를 이해 가능한 작은 의미 단위로 나누어서, 모델이 단어, 구두점, 형태소 등의 의미적으로 의미 있는 부분으로 이해할 수 있도록 하는 것
tokenization의 종류
-
Morphological Analysis (형태소 분석) 기반 토크나이저 (Mecab):
형태소 분석을 기반으로 문장을 토큰으로 나누는 방식입니다. 한국어의 경우, Mecab은 대표적인 형태소 분석기 중 하나로, 단어를 의미 단위로 나누는 작업을 수행합니다. -
✔️Subword Tokenization (Wordpiece, Sentencepiece):
단어를 부분 단어(subword)로 나누는 방식입니다. 단어 내의 의미 단위를 나누는데 유용하며, 미리 정의된 어휘 사전을 사용하여 문장을 부분 단어로 분할합니다. Sentencepiece는 특히 단어보다 더 작은 단위로 토큰화할 수 있도록 설계되었습니다.
BERT, ELECTRA 등 대다수의 모델은 Wordpiece를 사용하고 있으며, transformers에서도 공식적으로 Wordpiece만 지원하기 때문에 이번 프로젝트에서는 subword tokenization 방식 채택
Transformers 라이브러리만 있으면 모델을 곧바로 사용 가능하게 만드는 것이 목표이기에 Sentencepiece, Mecab을 사용하지 않고 원 논문과 코드에서 사용한 Wordpiece를 사용
📖ELECTRA 논문
ELECTRA = Efficiently Learning an Encoder that Classifies Token Replacements Accurately (효율적으로 토큰 대체를 정확하게 분류하는 인코더 학습)
- 기존 BERT를 비롯한 많은 language model들은 입력을 마스크 토큰으로 치환하고 이를 치환 전의 원본 토큰으로 복원하는 masked language modeling 태스크를 통해 pre-training
- 이런 모델들은 학습 시 상당히 많은 계산량을 필요로 하기 때문에 충분한 컴퓨팅 리소스가 없는 경우 문제가 발생
- ELECTRA는 이런 효율성 측면에 주목해 Replaced Token Detection (RTD)이라는 새로운 pre-training 방식을 제안함
🟩 MLM ; masked language modeling (마스크 언어 모델링)
State-of-the-art representation learning(현재의 최고 수준이거나 최고 수준에 해당하는 표현 학습 방법)은 일종의 denoising autoencoder(입력 데이터에서 노이즈를 제거하고 원래의 정확한 입력을 복원하는 신경망 구조) 학습임.
주로 입력 시퀀스의 토큰 중 약 15% 정도를 마스킹하고 이를 복원하는 masked language modeling (MLM)이라는 태스크를 통해서 학습함. 기존의 autoregressive language modeling 학습에 비해 양방향 정보를 고려한다는 점에서 효과적임.
-
토큰 마스킹: 먼저, 모델의 입력 문장에서 일부 단어를 랜덤하게 선택하여 가립니다. 즉, 해당 단어를 모델에게 보여주지 않습니다. 이것이 "마스킹" 단계입니다.
-
예측 단계: 가려진 단어를 모델이 예측하도록 합니다. 모델은 문맥을 기반으로 가려진 위치에 있는 단어를 추정하려고 노력합니다.
-
손실 계산: 실제로 가려진 단어와 모델이 예측한 단어 간의 차이를 측정하여 손실을 계산합니다. 일반적으로 교차 엔트로피 손실이 사용됩니다.
-
역전파와 파라미터 업데이트: 계산된 손실을 사용하여 모델의 파라미터를 업데이트합니다. 이 과정은 역전파를 통해 이루어지며, 모델은 가려진 단어를 정확하게 예측하도록 학습됩니다.
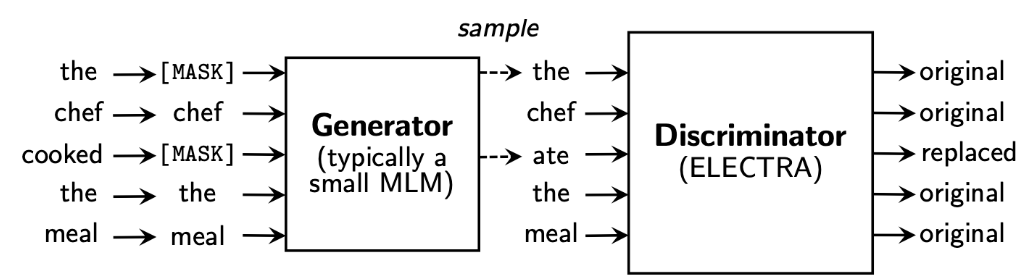
🟩 RTD ; Replaced Token Detection
RTD는 generator를 이용해 실제 입력의 일부 토큰을 그럴싸한 가짜 토큰으로 바꾸고, 각 토큰이 실제 입력에 있는 진짜(original) 토큰인지 generator가 생성해낸 가짜(replaced) 토큰인지 discriminator가 맞히는 이진 분류 문제임.
-
Generator에 의한 가짜 토큰 생성: 주어진 입력에서 일부 토큰을 선택하고, 이를 generator를 사용하여 현실적이고 일관된 가짜 토큰으로 대체합니다. 이는 입력의 일부를 마스킹하고, 그 부분을 생성된 토큰으로 채우는 것과 유사합니다.
-
Discriminator에 의한 이진 분류 문제: 생성된 가짜 토큰과 실제 원본 토큰을 함께 사용하여, discriminator는 각 토큰이 원본 토큰인지, 아니면 가짜 토큰으로 대체된 것인지를 예측하는 이진 분류 문제를 수행합니다.
-
학습: Generator와 Discriminator는 이러한 이진 분류 작업을 통해 상호적으로 학습됩니다. Generator는 더 현실적이고 혼동하기 어려운 가짜 토큰을 생성하도록, Discriminator는 더 정확하게 토큰을 식별하도록 조절됩니다.
-
ELECTRA의 특징: ELECTRA는 RTD 태스크로 입력의 15%가 아닌 모든 토큰에 대해 학습합니다. 이는 입력의 일부가 아닌 전체 토큰을 대상으로 함으로써 더 효과적인 학습을 가능하게 합니다. 또한 ELECTRA는 BERT보다 더 빠르게 학습되고, downstream task에서도 더 좋은 성능을 보입니다.
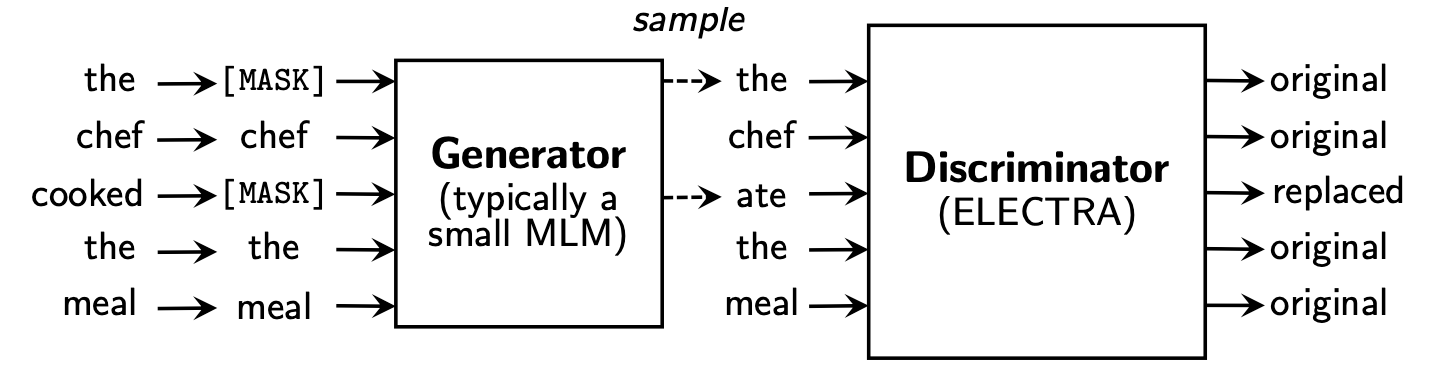
RTD 태스크를 통해 학습하기 위해서는 generator와 discriminator, 두 개의 네트워크가 필요
-
Generator (Replacement Generator):
- ELECTRA의 generator는 주어진 입력에서 일부 토큰을 선택하고 이를 가짜 토큰으로 대체하는 역할을 수행합니다. 이때 생성된 가짜 토큰은 실제로 그럴싸하게 보이게끔 만들어집니다. Generator는 학습 중에 Discriminator를 속이도록 노력하며, 높은 품질의 가짜 토큰을 생성할 수 있도록 학습됩니다.
-
Discriminator (Replaced Token Discriminator):
- ELECTRA의 discriminator는 주어진 입력에 대한 각 토큰이 원본 토큰인지 아니면 generator에 의해 생성된 가짜 토큰인지를 판별하는 역할을 수행합니다. Discriminator는 이진 분류 작업을 수행하며, 각 토큰에 대해 실제 원본인지 또는 가짜 토큰인지를 예측합니다. 학습 중에 Discriminator는 generator가 생성한 가짜 토큰을 정확하게 식별하도록, 즉 가짜 토큰과 원본 토큰을 잘 구분하도록 학습됩니다.
-
학습 상호작용:
- Generator와 Discriminator는 서로의 작업에 대한 경쟁적인 학습을 통해 발전합니다. Generator는 더 현실적인 가짜 토큰을 생성하여 Discriminator를 속이려고 노력하고, Discriminator는 가짜와 실제 토큰을 구분할 수 있도록 향상되어 갑니다. 이러한 학습 상호작용을 통해 모델은 입력의 15% 대신 모든 토큰에 대해 효과적으로 학습할 수 있습니다.
[3] 모델 fine tuning
KoELECTRA 개발 관련
KoELECTRA 데이콘 fine-tuning
HuggingFace KoElectra로 NSMC 감성분석 Fine-tuning
from transformers import ElectraModel, ElectraTokenizer
model = ElectraModel.from_pretrained("monologg/koelectra-base-discriminator") # KoELECTRA-Base
model = ElectraModel.from_pretrained("monologg/koelectra-small-discriminator") # KoELECTRA-Small
model = ElectraModel.from_pretrained("monologg/koelectra-base-v2-discriminator") # KoELECTRA-Base-v2
model = ElectraModel.from_pretrained("monologg/koelectra-small-v2-discriminator") # KoELECTRA-Small-v2
model = ElectraModel.from_pretrained("monologg/koelectra-base-v3-discriminator") # KoELECTRA-Base-v3
model = ElectraModel.from_pretrained("monologg/koelectra-small-v3-discriminator") # KoELECTRA-Small-v3이 중에서 # KoELECTRA-Small-v3 사용
ELECTRA는 먼저 대량의 데이터로 pre-training을 진행한 후, 그 중 일부를 discriminator라 불리는 작은 신경망으로 교체하고 해당 discriminator를 특정 태스크에 맞게 파인튜닝하는 방식으로 사용함. 여기서 주목할 점은 ELECTRA 모델이 BERT와 유사하지만 pooled_output을 리턴하지 않는다는 것임. 일반적인 BERT 모델에서는 pooled_output은 문장 레벨의 임베딩을 제공하는데, ELECTRA에서는 이 부분이 생략되어 문장 레벨의 임베딩을 따로 제공하지 않음.
A. 전처리
Hugging Face의 Transformers 라이브러리에서 제공하는 AutoTokenizer를 사용하여 KoELECTRA의 토크나이저를 활용하고자 함.
🟩 AutoTokenizer
from transformers import AutoTokenizer
# KoELECTRA의 토크나이저 불러오기
tokenizer = AutoTokenizer.from_pretrained("monologg/koelectra-small-v2-discriminator")
# 예시 문장 토큰화
text = "안녕하세요, Hugging Face Transformers 라이브러리를 사용해봅시다."
tokens = tokenizer.tokenize(tokenizer.decode(tokenizer.encode(text)))
print(tokens)
# 결과 : ['[CLS]', '안녕', '##하', '##세요', ',', 'H', '##ug', '##g', '##ing', 'F', '##ace', 'Trans', '##form', '##ers', '라이브러리', '##를', '사용', '##해', '##봅', '##시다', '.', '[SEP]']
