복습을 해봅시다

Q(S,a)=Return if you
- 손으로 계산할 수 없음
- 어떻게 학습할 것인지가 주요한 포인트!
- 최선을 다 했을 때 기대되는 return
- Bellman Equation을 통해 이를 계산할 수 있음
우리는 optimal policy는 알 수 없음
- 이미 알고 있다면, 굳이 Q(s,a)를 구할 필요가 없음
- 다만 각 state에서 left로 움직였을 때와 right로 움직였을 때 Q(s,a)가 어떻게 되는지 비교하고 그 중 Q가 큰 방식을 선택한다
Continuous state : 어떤 값이 올 지 모름
- discrete state가 아닌, vector로 표현할 것임
- 𝑠 = [𝑥, 𝑦, 𝑧,𝜙, 𝜃, 𝜔, 𝑥ሶ, 𝑦ሶ, 𝑧ሶ,𝜙ሶ, 𝜃ሶ, 𝜔ሶ]
- action에 대한 선택가 매우 중요함
- reward에 대한 설계가 매우 중요함
- 원하는 behavior를 명확히 명시해주지 않으면 강화학습이 잘 이뤄지지 않음
Chapter 13 : Continuous State Spaces
Learning the State-Action Value Function
주요 아이디어는 신경망을 훈련시켜 상태-행동 가치 함수 Q(s, a)를 계산하거나 근사하는 것. 이를 통해 좋은 행동을 선택 가능
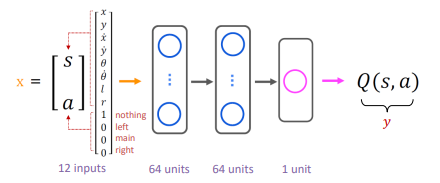
😎 이런 (s,a)를 주면 이런 Q(s,a)가 나와야 해
We’re going to train a neural network that (다음과 같이 신경망을 훈련시킬 예정)
– Inputs the current state 𝑠 and an action 𝑎 (→ the input 𝑥)
– Then computes or approximates 𝑄(𝑠, 𝑎) (→ the target 𝑦)
- 현재 상태 s와 행동 a를 입력으로 받음 (입력 x로 표시됨)
- 그 후에는 Q(s, a)를 계산하거나 근사 (타겟 y로 표시됨)
After we train the neural network (신경망을 훈련한 후에는 다음과 같이 사용)
– In a state 𝑠, we use the neural network to compute -> 𝑄(𝑠, nothing), 𝑄(𝑠, left), 𝑄(𝑠, main), 𝑄(𝑠, right)
– We then pick action 𝑎 that maximizes 𝑄(𝑠, 𝑎)
- 특정 상태 s에서, 신경망을 사용하여 계산: Q(s, nothing), Q(s, left), Q(s, main), Q(s, right)
- 이 예제에서는 4개의 숫자를 구해야 함
- 그 후에는 Q(s, a)를 최대화하는 행동 a를 선택
NOTE!!!
Notice that RL is different from supervised learning (강화 학습은 지도 학습과는 다르다는 점을 주목)
-
What we’re going to do is not to input a state and output an action (우리가 하는 것은 상태를 입력으로 받고 행동을 출력하는 것이 아님)
-
What we’re going to do is to input a state-action pair and output 𝑄(𝑠, 𝑎) (우리의 목표는 상태-행동 쌍을 입력으로 받고 𝑄(𝑠, 𝑎)를 출력하는 것)
-
Using a neural network inside the RL algorithm this way turns out to work
pretty well (잠깐만 neural network를 쓰는 것 ; 강화 학습 알고리즘 내부에서 신경망을 사용하는 것은 상당히 잘 작동) -
Question: "How do we train a neural network to output 𝑄(𝑠, 𝑎)? 신경망을 어떻게 훈련하여 𝑄(𝑠, 𝑎)를 출력?
- We will use the Bellman’s equations to create a training set with lots of
examples (𝑥, 𝑦) = ((𝑠, 𝑎),𝑄(𝑠, 𝑎)) 벨만 방정식을 사용하여 많은 예제(𝑥, 𝑦) = ((𝑠, 𝑎),𝑄(𝑠, 𝑎))로 이루어진 훈련 세트를 만들 것
- Then we’ll use supervised learning exactly as you learned in the 2nd course 그런 다음 2번째 과정에서 배운 것과 똑같이 지도 학습을 사용할 것
- But how do we get the training set with (𝑥, 𝑦) = ((𝑠, 𝑎),𝑄(𝑠, 𝑎)) to train a
neural network?
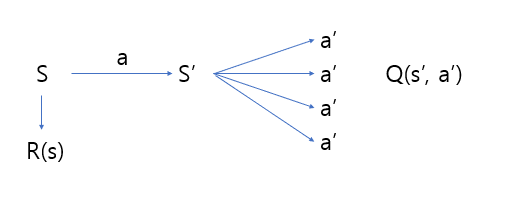
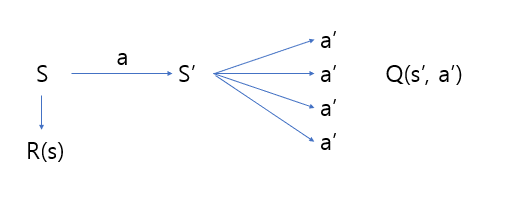
Using the Bellman Equation
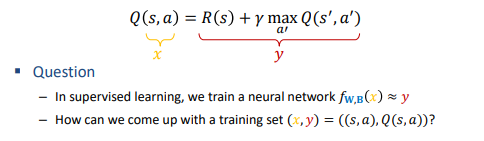
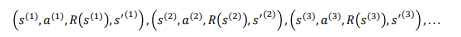
s(1)에서 a(1) 행동을 취했더니 R(s(1)) 보상이 왔고, 다음 state는 s'(1)이 되었다.
질문: "지도 학습에서 우리는 신경망 𝑓𝐖,𝐁를 훈련시켜 𝑥에 대해 𝑦를 예측합니다. 그렇다면 (𝑥, 𝑦) = ((𝑠, 𝑎),𝑄(𝑠, 𝑎)) 훈련 세트를 어떻게 얻을 수 있을까요?"
우리가 할 일은 다음과 같음:
다양한 시도를 해보고 많은 예제를 관찰
- 특정 상태 𝑠에서 어떤 행동 𝑎를 취함 (좋은 행동일 수도 있고 나쁜 행동일 수도 있음)
그런 다음 어떤 보상 𝑅𝑠를 받고 새로운 상태 𝑠'에 도달. - 이러한 시퀀스를 반복하며 상태-행동 쌍과 그에 따른 보상을 수집 가능. 이러한 데이터를 사용하여 상태-행동 쌍에 대한 𝑄(𝑠, 𝑎) 값을 얻어 훈련 세트를 구성 가능. 이러한 프로세스를 통해 강화 학습에서 신경망을 훈련하는 데 사용할 데이터를 생성 가능
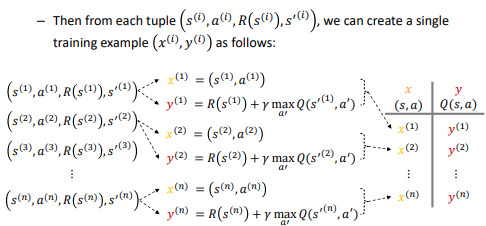

- 지금 훈련 중인 network를 사용하면 (믿을 수는 없지만) q(s,a) 방송은 더러움
- replay buffer :
// initial random guess of 𝑄(𝑠, 𝑎)
Initialize a neural network 𝑄 randomly
// improves to get a better estimate of 𝑄(𝑠, 𝑎)
Repeat {
Take actions and get 𝑠, 𝑎, 𝑅 𝑠 , 𝑠
′
Store 10,000 most recent 𝑠, 𝑎, 𝑅 𝑠 , 𝑠
′ tuples
Train the neural network:
Create a training set of 10,000 examples using
𝑥, 𝑦 = (𝑠, 𝑎), 𝑅 𝑠 + 𝛾 max Q(s',a'))
Train 𝑄𝑛𝑒𝑤 such that 𝑄𝑛𝑒𝑤 𝑠, 𝑎 ≈ 𝑦
Set 𝑄 = 𝑄𝑛𝑒𝑤
}
- 신경망 모델에 넣고 끝나는 것이 아니라 계속해서 새로운 것을 학습
= 오히려 나빠질 수도 있음
정리를 하자면
- 정말 무작위한 추정으로 𝑄(𝑠, 𝑎)을 시작합니다.
- 그런 다음 벨만 방정식을 사용하여 반복적으로 𝑄(𝑠, 𝑎)의 추정치를 개선하려고 노력합니다.
- 이 과정을 반복함으로써, 𝑄(𝑠, 𝑎)에 대한 추측이 점점 개선됩니다.
- 다음 모델을 훈련할 때, 𝑄(𝑠, 𝑎)에 대한 더 나은 추정치를 얻을 수 있습니다.
- 충분한 시간을 들여 이 알고리즘을 실행하면 실제 𝑄(𝑠, 𝑎)의 꽤 좋은 추정치가 될 것입니다.
- 계속 반복하면서 조금 더 나은 Q(s,a)로 개발함
방금 보신 알고리즘은 DQN 알고리즘이라고 합니다.
- Deep Q-Network의 약자로, 수렴하는 데 시간이 오래 걸릴 수 있거나 완벽하게 작동하지 않을 수 있지만, 일정 수준에서는 작동할 것입니다.
chatper 14 : Algorithm Refinement:Improved Neural Network Architecture
지금까지 one-hot encoding을 보면서 답답하지 않았는가..?
action이 possible 개수가 10개가 넘을 경우, 10개를 전부 돌리기에는 너무 무리임
결론 : ouput을 4개로 만들자!
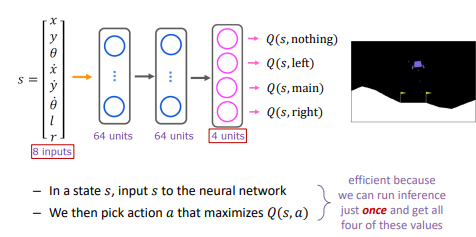
More Efficient Architecture for DQN
이 알고리즘을 훨씬 효율적으로 만드는 신경망 구조가 변경
- 대부분의 DQN 구현체는 이 보다 효율적인 구조를 사용합니다.
- 우리가 이전에 보았던 신경망 구조와는 다릅니다.
s를 밀어넣으면 각 Q(s,a)가 바로 나오도록 바꾸는 것 (한 큐에 전부 구할 수 있음)
- 이 변경으로 인해 𝑅 𝑠 + 𝛾 max 𝑎′ 𝑄(𝑠 ′, 𝑎′)을 계산하는 것도 훨씬 효율적으로 할 수 있게 되었습니다.
- 이제 모든 행동 𝑎′에 대한 𝑄(𝑠 ′, 𝑎′) 값을 동시에 얻을 수 있기 때문입니다.
