
지난시간에는!
reward가 매우 중요함 !!
state가 주어지면 어떤 actio을 할 지 policy 세우기
- Q function : Q(s, a) s상태에서 a할 때 얼마만큼의 보상을 받을지 알려주는 것
- 어떤 s 상태에서 모든 a에 대해 Q(s,a)를 구하기
벡터 두 개를 합치면 x = [s a]라는 벡터를 얻을 수 있음!!
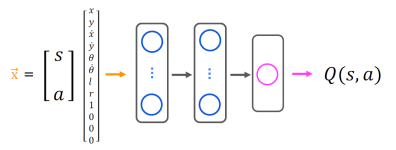
Bellman’s equations을 사용하면 되겠다! 🪄🪄 <매우 중요>
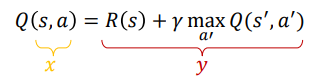
Q(s',a')은 현재 network에서 얻어옴 (지금은 최선이 아닐지라도, 이후에 계속해서 학습하면 이후의 network는 정확해질 것임)
DQN algorithm라고 한다
# initial random guess of 𝑄(𝑠, 𝑎)
Initialize a neural network 𝑄 randomly
# improves to get a better estimate of 𝑄(𝑠, 𝑎)
Repeat {
Take actions and get (𝑠, 𝑎, 𝑅(𝑠), 𝑠')
Store 10,000 most recent (𝑠, 𝑎, 𝑅(𝑠), 𝑠') tuples
Train the neural network:
Create a training set of 10,000 examples using
(𝑥, 𝑦) = ((𝑠, 𝑎), 𝑅(𝑠) + 𝛾 max(𝑄(𝑠',a))
Train 𝑄𝑛𝑒𝑤 such that 𝑄𝑛𝑒𝑤(𝑠, 𝑎) ≈ 𝑦
Set 𝑄 = 𝑄𝑛𝑒𝑤
}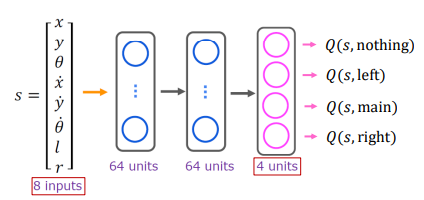
처음에 s만 있음 (a가 없음)
장점
- much more efficient (action을 취할 때도 효율적)
- at the same time (belman equation을 만들어 y를 취할 때도 효율적)
Chapter 15 : Algorithm Refinement: 𝜖-Greedy Policy
# initial random guess of 𝑄(𝑠, 𝑎)
Initialize a neural network 𝑄 randomly
# improves to get a better estimate of 𝑄(𝑠, 𝑎)
Repeat {
Take actions and get (𝑠, 𝑎, 𝑅(𝑠), 𝑠')
Store 10,000 most recent (𝑠, 𝑎, 𝑅(𝑠), 𝑠') tuples
Train the neural network:
Create a training set of 10,000 examples using
(𝑥, 𝑦) = ((𝑠, 𝑎), 𝑅(𝑠) + 𝛾 max(𝑄(𝑠',a))
Train 𝑄𝑛𝑒𝑤 such that 𝑄𝑛𝑒𝑤(𝑠, 𝑎) ≈ 𝑦
Set 𝑄 = 𝑄𝑛𝑒𝑤
}Take action에서 어떻게 학습하면서 그러한 행동을 선택하나요?
(우리는 모든 상황에서 취할 최선의 행동을 정확히 알지 못합니다)
- actiond을 취할 때 무조건 random하게 하지 않음
- 너무나도 random할 경우, 영양가 없는 행동 많이 함, 학습 시간이 오래 걸림
옵션 1
- 𝑄(𝑠, 𝑎)를 최대화하는 행동 𝑎 선택
• 현재에는 𝑄(𝑠, 𝑎)가 좋은 추정이 아니더라도 최선을 다하겠습니다.
• 이 방법이 괜찮게 작동할 수도 있지만 최상의 선택은 아닙니다.
• Q(s,a)만 max되는 action을 선택할 경우 운 나쁠 경우 Q(s,a)값이 나쁜 a들을 한 번도 선택하지 않을 확률
옵션 2 (일반적인 선택)
- 확률 0.95로, 𝑄(𝑠, 𝑎)를 최대화하는 𝑎 선택 “탐욕스러운 이용”
- 확률 0.05로, 무작위로 𝑎 선택 “탐사”
• (예: 초기 𝑄(𝑠, main)이 낮으면, 우리는 main 행동을 선택하지 않을 것입니다.)
• 95%는 Q(s,a)가 선택되도록 하되, 나머지 5%는 랜덤하게!
만약 점점 진행될 수록, 입실론값을 천천히 줄여봄 (random값을 점차 줄임)
처음에는 𝜖를 높게 설정하고 점차적으로 감소시킵니다 (예: 1.0 → 0.001)
• 처음에는 무작위로 많은 행동을 취합니다.
• 시간이 지남에 따라 무작위로 행동을 취할 확률은 낮아지고, 𝑄(𝑠, 𝑎)의 향상된 추정치를 사용하여(Q(s,a)를 믿고 가끔 랜덤하게 움직임) 좋은 행동을 선택할 가능성이 더 커집니다.
강화 학습 알고리즘은 초매개변수 선택 측면에서 지도 학습에 비해 까다로움
- 예시
- 지도 학습
• 학습률 𝛼를 조금 작게 설정하면 알고리즘이 학습하는 데 더 오랜 시간이 걸릴 수 있지만 크게 나쁘지 않을 수도 있습니다. - 강화 학습
• 𝜖를 약간 부적절하게 설정하면 학습에 10배 또는 100배 더 오랜 시간이 걸릴 수 있습니다.
- 지도 학습
- 강화 학습 알고리즘은 지도 학습 알고리즘보다 성숙도가 낮기 때문에 초매개변수를 조정하는 데 훨씬 더 까다로울 수 있습니다.
- 강화학습에서 입실론값은 답이 없음 (얼마나 줄여야 할 지, 늘려야 할 지 알 수 없음)
Chapter 16 : Algorithm Refinement: Soft Updates
이것이 더 강화학습을 더 어렵게 만듦
# initial random guess of 𝑄(𝑠, 𝑎)
Initialize a neural network 𝑄 randomly
# improves to get a better estimate of 𝑄(𝑠, 𝑎)
Repeat {
Take actions and get (𝑠, 𝑎, 𝑅(𝑠), 𝑠')
Store 10,000 most recent (𝑠, 𝑎, 𝑅(𝑠), 𝑠') tuples
Train the neural network:
Create a training set of 10,000 examples using
(𝑥, 𝑦) = ((𝑠, 𝑎), 𝑅(𝑠) + 𝛾 max(𝑄(𝑠',a))
Train 𝑄𝑛𝑒𝑤 such that 𝑄𝑛𝑒𝑤(𝑠, 𝑎) ≈ 𝑦
Set 𝑄 = 𝑄𝑛𝑒𝑤
}// Set 𝑄 = 𝑄𝑛𝑒𝑤
이는 𝑄에 매우 급격한 변화를 일으킬 수 있습니다.
만약 새로운 𝑄가 우연히 이전 𝑄보다 나쁘다면, 당신은 잠재적으로 더 나쁜 노이즈가 있는 신경망 𝑄𝑛𝑒로 덮어쓸 수 있습니다.
- 값이 연속적으로 서서히 바뀌는 게 아니라
- 새로 만들어진 q는 앞의 layer를 완전히 overwrite한 느낌
- 이러한 점이 결국 불안정하게 만듦
따라서 부드럽게 update하는게 soft updates
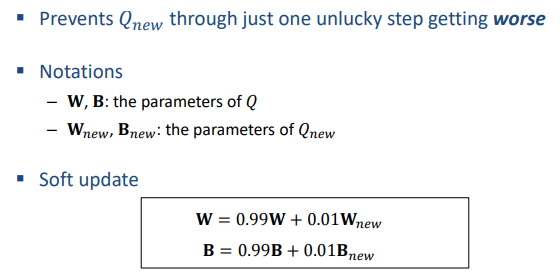
이는 𝑄(또는 𝑄(𝑠, 𝑎))에 더 점진적인 변화를 일으킵니다.
- 강화 학습 알고리즘을 더 신뢰할 수 있게 수렴시킵니다.
- 강화 학습 알고리즘이 진동하거나 발산할 가능성을 줄입니다.(oscillate or diverge)
😎 Limitations of Reinforcement Learning
강화 학습에는 약간의 과대포장이 있습니다.
- 강화 학습의 유용성 측면에서 현재 상황을 실용적으로 공유합니다.
▪ 시뮬레이션에서 작업하는 것이 실제 로봇에서 작업하는 것보다 훨씬 쉽습니다! - 시뮬레이션에서 작업하는 것이 가능해도, 실제 세계에서 작업하는 것은 놀랄 만큼 어려울 수 있습니다. (게임이나 바둑 같은 인터넷 세계에서는 잘 돌아감)
▪ 지도 및 비지도 학습에 비해 적은 응용 분야가 있습니다. - 실제적인 응용 프로그램을 개발 중이라면, 강화 학습을 사용할 확률보다는 지도 학습이나 비지도 학습을 사용할 확률이 훨씬 높을 것입니다. (강화학습은 아직 '수학적으로 증명'하지는 못함)
그럼에도!!
현재 강화 학습 분야에서는 매우 흥미로운 연구들이 진행되고 있습니다.
▪ 강화 학습의 미래 응용 가능성은 매우 큽니다.
▪ 강화 학습은 여전히 기계 학습의 주요 요추 중 하나로 남아 있습니다.
▪ 여러분이 자신의 기계 학습 알고리즘을 개발하는 과정에서 이를 프레임워크로 사용한다면, 기계 학습 시스템을 구축하는 데 더욱 효과적일 수 있습니다.
지금까지 정리!
Supervised Learning: Regression and Classification
– Linear regression
– Logistic regression
– Gradient descent
Advanced Learning Algorithms
– Neural networks
– Advice for applying ML
Recommenders, Reinforcement Learning
– Collaborative filtering
– Content-based filtering
– Reinforcement learning
