MySQL 서버의 구조
MySQL 서버는 크게 MySQL 엔진과 스토리지 엔진으로 구성되어 있다.
MySQL 엔진은 요청된 SQL문을 분석하고 최적화하는 등 데이버테이스의 두뇌에 해당하는 역할을 하고, 실제 데이터를 디스크에 저장하거나 데이터를 읽어오는 작업은 스토리지 엔진이 담당한다.
MySQL 엔진
MySQL 엔진은
- 클라이언트로부터 커넥션 및 쿼리 요청을 처리하는 커넥션 핸들러,
- SQL 문법 오류를 탐지하고 SQL문을 MySQL이 인식할 수 있는 토큰 단위로 나눠 파싱하는 SQL 파서,
- 쿼리의 최적화된 실행 계획을 수립하는 옵티마이저
등으로 이루어져 있다.
스토리지 엔진
- 실제 데이터를 디스크에 저장하거나 조회하는 부분을 담당한다.
- 스토리지 엔진은 MySQL 엔진과 플러그인 형태로 연동/분리가 가능하다.
- MySQL 서버에서 MySQL 엔진은 하나지만 스토리지 엔진은 동시에 여러 개를 사용할 수 있다.
- InnoDB, IyISAM, MEMORY 등이 있다.
핸들러 API
MySQL 엔진의 쿼리 실행기에서 데이터를 쓰거나 읽어야 할 때 스토리지 엔진에 보내는 요청을 핸들러 요청이라 하고, 이 때 사용되는 API를 핸들러 API 라고 한다.
즉, MySQL 엔진과 스토리지 엔진은 핸들러 API를 통해 데이터를 주고 받는다.
쿼리 실행 구조
- 사용자의 요청으로 들어온 쿼리 문장을 쿼리 파서를 통해 MySQL이 인식할 수 있는 토큰으로 분리해 트리 형태의 구조로 만든다. (쿼리 문장의 기본 문법 오류는 이 과정에서 발견된다.)
- 전처리기에서 파서 과정에서 만들어진 파서 트리를 기반으로 쿼리 문에 구조적 문제점이 있는지 확인한다. 해당 객체의 존재 여부나 접근 권한 등을 확인하는 과정을 수행한다. (없는 테이블, 칼럼에 접근하는 등의 오류는 이 단계에서 걸러진다.)
- 옵티마이저를 통해 쿼리 문장을 저렴한 비용으로 가장 빠르게 처리할지를 결정한다.
- 실행 엔진이 옵티마이저에서 수립된 실행 계획대로 각 핸들러에게 지시한다. (ex. 임시 테이블 만들어 -> WHERE 절과 일치하는 레코드 읽어와 -> 읽은 레코드들을 임시 테이블에 저장해 -> 임시 테이블에서 데이터 읽어와...)
- 핸들러(=스토리지 엔진)은 받은 지시대로 작업을 수행한다.
InnoDB 스토리지 엔진
InnoDB 스토리지 엔진은 MySQL에서 가장 많이 사용되는 스토리지 엔진이다. MySQL의 스토리지 엔진 중에서 거의 유일하게 레코드 기반 잠금을 제공하며, 때문에 높은 동시성 처리가 가능하고 안정적이며 성능이 뛰어나다.
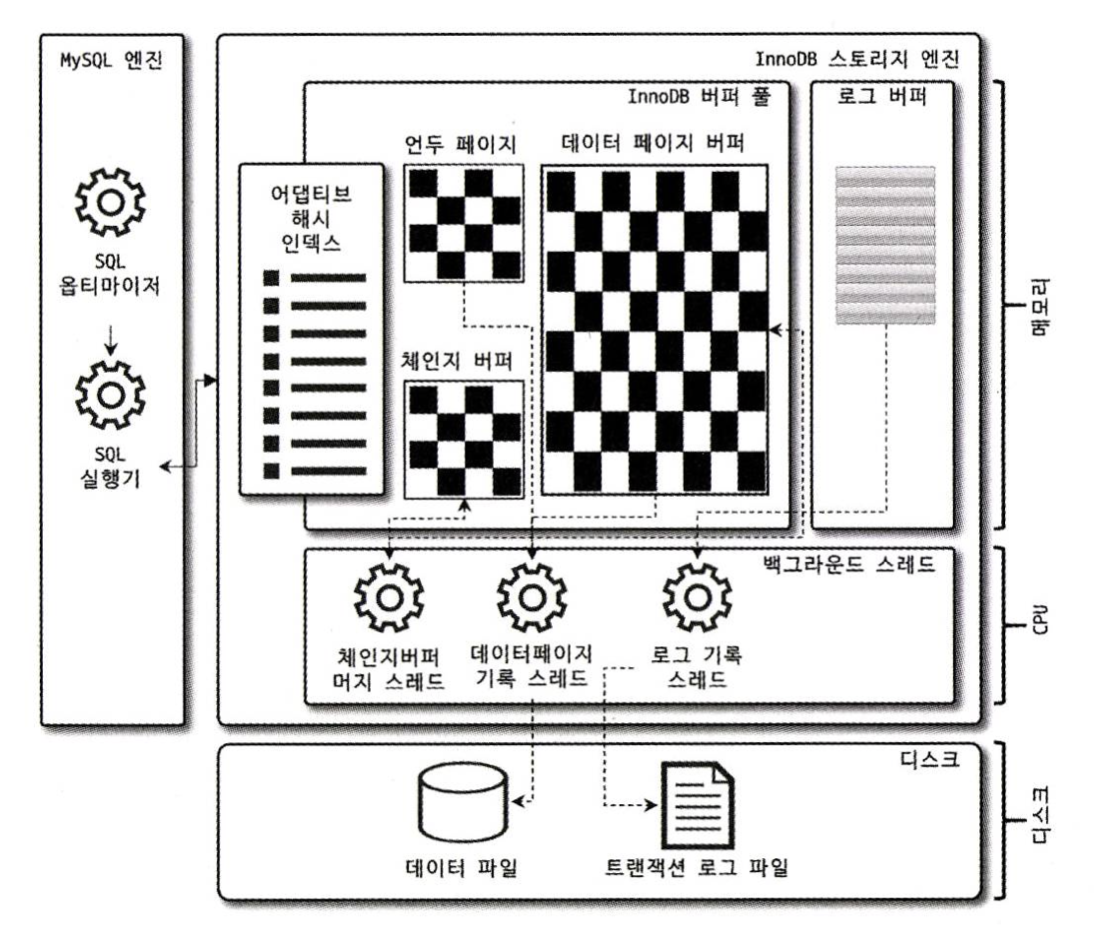
InnoDB의 특징
프라이머리 키에 의한 클러스터링
- InnoDB의 모든 테이블은 기본적으로 프라이머리 키를 기준으로 클러스터링되어 자장된다.
- 즉, 프라이머리 키 값의 순서대로 디스크에 저장된다.
- 모든 세컨더리 인덱스는 레코드 주소 대신 프라이머리 키의 값을 논리적인 주소로 사용한다.
- 프라미어리 키가 클러스터링 인덱스이기 때문에 프라이머리 키를 이용한 레인지 스캔이 상당히 빨리 처리될 수 있다.
- 때문에 쿼리 실행 계획에서 다른 보조 인덱스보다 프라이머리 키가 선택될 확률이 높다.
외래 키 지원
- InnoDB 스토리지 엔진 레벨에서만 지원하는 기능으로 MyISAM이나 MEMORY 테이블에서는 사용할 수 없다.
- 외래 키는 여러 제약사항 때문에 서비스용 데이터베이스에서는 생성하지 않는 경우도 있지만, 개발 환경의 데이터베이스에서는 좋은 가이드 역할을 할 수 있다.
MVCC(Multi Version Concurrency Control)
MVCC는 하위 레코드에 대해 여러 개의 버전이 동시에 관리된다는 의미이며, 시스템에서 설정한 트랜잭션 격리 수준에 따라 다르게 처리된다.
예를 들어, 다음과 같이 테이블에 한 건의 레코드를 변경한다면
UPDATE member
SET m_area = '경기'
WHERE m_id = 12;InnoDB 의 버퍼 풀과 데이터 파일엔 다음과 같이 기록되어 있다.
- 버퍼 풀) id = 12, ..., m_area = '경기' (업데이트 되어있음)
- 언두 로그) id = 12, m_area = '서울' (변경 전 값만 언두 로그로 복사)
- 데이터 파일) id = 12, ..., m_area = ? (체크포인트나 Write 스레드에 의해 업데이트 되어있을 수도 있고 아닐 수도 있음)
아직 커밋이나 롤백되지 않은 상태에서 다른 사용자가 해당 레코드를 조회한다면..
격리 수준이 READ_UNCOMMITTED 라면 -> 버퍼 풀이 현재 가지고 있는 변경된 데이터를 읽어서 반환한다.
그 이상의 격리 수준이라면 (READ_COMMITTED, REPEATABLE_READ, SERIALIZABLE) -> 아직 커밋되지 않았기 때문에 변경 이전의 내용을 보관하고 있는 언두 영역의 데이터를 반환한다.
잠금 없는 일관된 읽기(Non-Locking Consistent Read)
앞에서 살펴본 MVCC 기술을 이용해 잠금을 걸지 않고 읽기 작업을 수행한다.
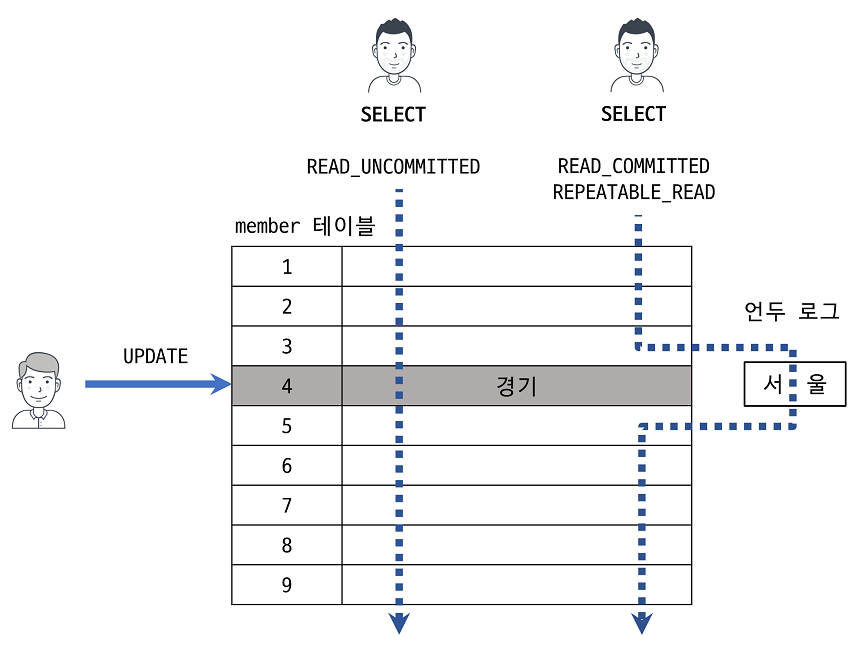
격리 수준이 SERIALIZABLE 이 아니라면 순수한 읽기(SELECT) 작업은 다른 트랜잭션의 변경 작업과 관계없이 항상 잠금을 대기하지 않고 바로 실행된다.
다음과 같이 특정 사용자가 레코드를 변경하고 아직 커밋하지 않아도, 이 변경 트랜잭션이 다른 사용자의 SELECT 작업을 방해하지 않는다. 이를 잠금 없는 일관된 읽기 라고 표현하며, InnoDB에서는 변경 전 데이터를 읽기 위해 언두 로그를 사용한다.
자동 데드락 감지
내부적으로 잠금이 교착 상태에 빠지지 않았는지 체크하기 위해 잠금 대기 목록을 그래프 형태로 관리한다.
데드락 감지 스레드를 통해 주기적으로 잠금 대기 그래프를 검사해 교착 상태에 빠진 트랜잭션들을 찾아서 그 중 하나를 강제 종료한다.
이때, 언두 로그를 더 적게 가진 트랜잭션을 먼저 종료한다. (언두 레코드가 적다 = 롤백할 때 언두를 처리할 내용이 적다 -> 트랜잭션 강제 롤백으로 인한 서버의 부하도 덜 하다)
자동화된 장애 복구
InnoDB에는 손실이나 장애로부터 데이터를 보호하기 위한 여러 메커니즘이 탑재되어 있다.
이러한 메커니즘을 활용해 MySQL 서버가 시작될 때 완료되지 못한 트랜잭션이나 디스크에 일부만 기록되 데이터 페이지 등에 대한 복구 작업이 자동으로 진행된다.
자동으로 복구될 수 없는 손상이 있다면 자동 복구를 멈추고 MySQL 서버가 종료된다.
InnoDB 버퍼 풀
InnoDB 스토리지 엔진에서 가장 핵심적인 부분으로, 디스크의 데이터 파일이나 인덱스 정보를 메모리에 캐시해 두는 공간이다.
쓰기 작업을 지연시켜 일괄 작업으로 치리할 수 있게 하는 버퍼 역할도 같이 한다.
언두 로그
트랜잭션과 격리 수준을 보장하기 위해 DML(INSERT, UPDATE, DELETE)로 변경되기 이전 버전의 데이터를 별도로 백업해둔다. 이렇게 백업된 데이터를 언두 로그(Undo Log) 라고 한다.
- 트랜잭션 보장 : 트랜잭션이 롤백되면 언두 로그에 백업해둔 이전 버전의 데이터를 이용해 복구한다.
- 격리 수준 보장 : 특정 커넥션에서 데이터를 변경하는 중에 다른 커넥션에서 데이터를 조회하면 격리 수준에 맞게 변경 중인 레코드를 읽지 않고 언두 로그에 백업해둔 데이터를 읽어서 반환하기도 한다.
언두 로그는 InnoDB 에서 매우 중요한 역할을 담당하지만 관리 비용도 많이 필요하다.
체인지 버퍼
레코드가 INSERT 되거나 UPDATE 될 때는 데이터 파일을 변경하는 작업 + 해당 테이블에 포함된 인덱스를 업데이트하는 작업이 필요하다. 그런데 인덱스를 업데이트하는 작업은 랜덤하게 디스크를 읽는 작업이 필요하므로 테이블에 인덱스가 많다면 이 작업은 상당히 많은 자원을 소모하게 된다.
InnoDB 는 변경해야 할 인덱스 페이지가 버퍼 풀에 있으면 바로 업데이트를 수행하지만 디스크로부터 읽어와서 업데이트해야 한다면 이를 즉시 실행하지 않고 임시 공간에 저장해 두고 바로 사용자에게 결과를 반환하는 형태로 성능을 향상시키는데 이때 사용하는 임시 메모리 공간을 체인지 버퍼(Change Buffer)라고 한다.
리두 로그
MySQL 서버가 비정상적으로 종료되었을 때 데이터 파일에 기록되지 못한 데이터를 잃지 않게 해주는 안전장치 역할을 한다.
어댑티브 해시 인덱스
사용자가 직접 설정한 인덱스가 아닌 InnoDB 에서 사용자가 자주 요청하는 데이터에 대해 자동으로 생성하는 인덱스이다.
B-Tree의 검색 시간을 줄이기 위해 도입된 기능이다. 자주 읽히는 데이터 페이지의 키 값을 이용해 해시 인덱스를 만들고 필요할 때마다 어댑티브 해시 인덱스를 검색해 레코드가 저장된 데이터 페이지를 즉시 찾아갈 수 있게 해 준다. (B-Tree 처럼 루트 노드부터 리프 노드까지 찾아가는 비용이 없어지고 쿼리 성능이 빨라짐)
어뎁티브 해시 인덱스는 버퍼 풀에 올려진 데이터 페이지에 대해서만 관리되고, 버퍼 풀에서 해당 데이터 페이지가 없어지면 어댑티브 해시 인덱스에서도 해당 페이지의 정보는 사라진다.
성능 향상에 크게 도움이 되지 않는 경우
- 디스크 읽기가 많은 경우
- 특정 패턴의 쿼리가 많은 경우(LIKE 패턴 검색이나 조인)
- 매우 큰 데이터를 가진 테이블의 레코드를 폭넓게 읽는 경우
성능 향상에 도움이 되는 경우
- 디스크의 데이터가 InnoDB 버퍼 풀 크기와 비슷한 경우(디스크 읽기가 많지 않은 경우)
- 동등 조건 검색(동등 비교와 IN 연산자)이 많은 경우
- 쿼리가 데이터 중에서 일부 데이터에만 집중되는 경우
Reference
Real MySQL 8.0 (1권)
