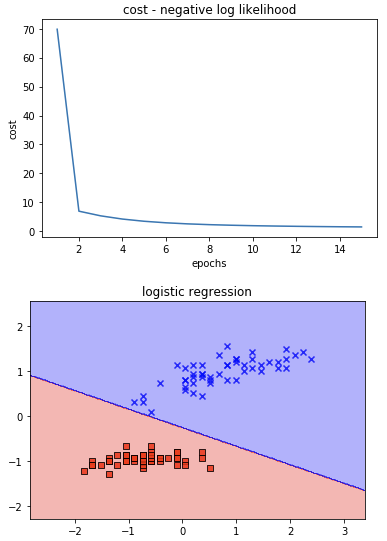
로지스틱 회귀 logistic regression
선형 회귀 방식을 이용한 이진 분류 모델
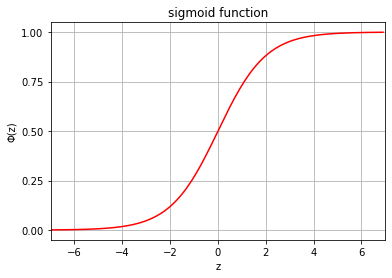
로지스틱 시그모이드 함수 logistic sigmoid function
-
오즈 비 odds ratio: 특정 이벤트가 발생할 확률이 그렇지 않을 확률의 몇배인가? (여기서 특정 이벤트: y=1)
- odds_ratio=1−p(y=1∣x)p(y=1∣x)
- 오즈 비의 출력값의 범위: [0,+∞)
-
로짓 함수: 오즈 비의 입력값 p의 범위가 [0, 1]일 때, (−∞,+∞) 범위의 출력을 얻기 위해 오즈 비에 로그를 덧씌운다.
- logit(p)=ln1−pp
- 선형 회귀 방식을 이용하여 독립변수의 선형결합으로 logit값을 예측한다.
logit(P(y=1∣x))=w0x0+⋯+wmxm=∑i=0mwixi=w⊤x=z
- 로지스틱 시그모이드 함수: 데이터 샘플의 레이블을 예측하기 위해선 x를 입력으로 받아 P(y=1∣x), 레이블이 1일 확률을 계산해야하므로 로짓 함수를 x를 입력받아 p를 출력하도록 역함수를 취한다. 짧게 시그모이드 함수.
- pi=logit−1(w⊤x)=1+e−w⊤x1=1+e−z1
- 특정 샘플의 실수 로짓값을 입력받아 y=1일 확률값을 출력한다.
- z→∞: 오즈비가 매우 크다. y=1일 확률이 1에 가까워진다. = 시그모이드 함수 값이 1에 가까워진다.
- z→−∞: 오즈비가 매우 작다. y=1일 확률이 0에 가까워진다. = 시그모이드 함수 값이 0에 가까워진다.
로지스틱 회귀 모델
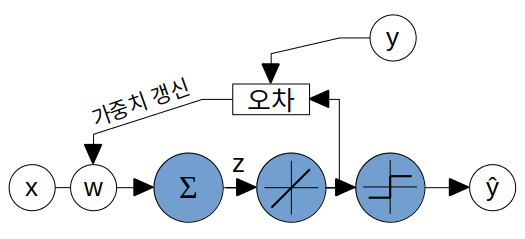
ADALINE과 비교
- ADALINE
- 로지스틱 회귀 모델: 아달린의 선형 함수를 시그모이드 함수로 대체
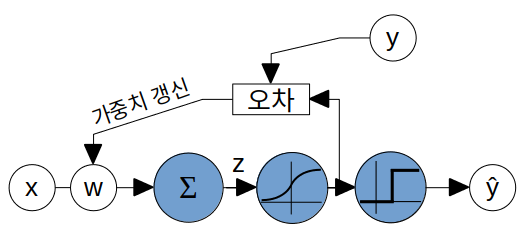
시그모이드 함수의 해석
x에 대한 시그모이드 함수의 출력은 x의 레이블 y가 1일 확률 ϕ(z)=P(y=1∣x;w)
어떤 샘플에 대해서 ϕ(z)=0.7이라면 이 샘플이 클래스1에 속할 확률이 70%라고 해석한다.
클래스 0에 속할 확률 P(y=0∣x;w)=1−ϕ(z)
임계함수
시그모이드 함수의 출력을 이진 출력으로 변환.
어떤 클래스에 속할 확률(시그모이드 함수 출력값)이 50% 이상이면 그 클래스를 반환.
y^={1,0,ϕ(z)≥0.5otherwise
y^={1,0,z≥0.otherwise
가능도 likelihood L
L(w)=P(y∣x;w)=∏i=1nP(y(i)∣x(i);w)=∏i=1n(ϕ(z(i)))y(i)(1−ϕ(z(i)))1−y(i)
시그모이드 함수로 계산한 개별 샘플들이 각자의 레이블에 속할 확률의 곱
모든 샘플들이 각자의 레이블에 속할 확률이 100%라면 L=1로 최댓값
- y(i)=1인 샘플 x(i)에 대해서
- (ϕ(z(i)))y(i): x(i)의 클래스가 1일 확률에 대한 항으로 1에 가까워져야한다.
- (1−ϕ(z(i)))1−y(i): x(i)의 클래스가 0일 확률. 다만 y(i)=1인 경우 확률값을 1−y(i)=0제곱하여 1이 되므로 무시된다.
- y(i)=0인 경우에는 반대로 (ϕ(z(i)))y(i), 샘플이 클래스 1에 속할 확률이 무시되고 (1−ϕ(z(i)))1−y(i), 샘플이 클래스 0에 속할 확률이 가능도 계산에 포함된다.
가능도를 최대화하는 방향으로 가중치를 업데이트한다. (가능도의 최대화 = '모델이 계산한 개별 샘플들이 각자의 클래스에 속할 확률'의 최대화)
가능도에 로그를 씌울 경우
- 가능도가 매우 작아 발생하는 언더플로우 방지: 0≤ϕ(z)≤1 이므로 계속 곱할 경우 매우 작아진다.
- 계수의 곱을 합으로 바꾼다.
l(w)=logL(w)=∑i=1n[y(i)log(ϕ(z(i)))+(1−y(i))log(1−ϕ(z(i)))]
- y(i)=1일 때, log(ϕ(z(i)))만 더해진다.
- y(i)=0일 때, log(1−ϕ(z(i)))만 더해진다.
로그 가능도에 −1을 곱해 최소화해야하는 비용함수로 사용할 수 있다.
J(w)=−∑i=1n[y(i)log(ϕ(z(i)))+(1−y(i))log(1−ϕ(z(i)))]
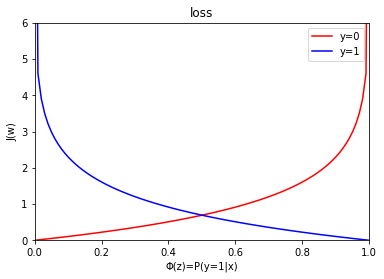
이 경우 개별 샘플에 대해서 다음과 같이 loss가 계산되고 에러가 클수록 더 큰 비용을 부과하게된다.
J(ϕ(z),y;w)={−log(ϕ(z)),−log(1−ϕ(z)),y=1y=0
가중치 갱신 - 경사 하강법
Δwj=−η∂ϕ(z)∂J∂z∂ϕ(z)∂wj∂z
∂z∂ϕ(z)=∂z∂1+e−z1=(1+e−z1)2e−z=1+e−z11+e−ze−z=ϕ(z)(1−ϕ(z))
Δwj=η∑i=1n[y(i)ϕ(z(i))1−(1−y(i))1−ϕ(z(i))1]ϕ(z(i))(1−ϕ(z(i)))xj(i)=η∑i=1n(y(i)−ϕ(z(i)))xj(i)
wj=wj+Δwj=wj+η∑i=1n(y(i)−ϕ(z(i)))xj(i)
w=w+Δw=w−η∇J(w)=w+η∑i=1n(y(i)−ϕ(z(i)))x(i)
코드
https://github.com/canlion/ml_study/blob/main/3_1_logistic_regression.ipynb