
Chap.13 물체 감지와 추적
6. 광학 흐름 기반 추적 기법
- Optical flow(광학 흐름):
- 이미지의 feature point(특징점)을 이용해 물체를 추적하는 기법
- 컴퓨터 비전 분야에서 인기 있는 기법 중 하나
- 실시간 영상의 연속적 프레임 중 현재 프레임에서 일련의 feature point를 발견하면 이에 대한 displacement vector(변위 벡터)를 계산하여 feature point를 추적함
- 이때 움직이는 변위 벡터 = motion vector
- Lucas-Kanade 기법: 광학 흐름 기법을 구현하는 방법 중 하나
- 수행 방법:
1) 현재 프레임에서 feature point를 추출하여 그 중심에 3*3 patch(픽셀 집합)를 만듦
- 이때 각각의 패치에 있는 점들은 모두 비슷한 방향으로 움직인다고 가정
- 윈도우의 크기는 상황에 맞게 조절
2) 각각의 패치에 대해 이전 프레임과 일치하는 부분 찾음
- 오차 값 기준으로 가장 유사한 것 선택
- 탐색 영역은 3*3보다 커야 함; 다양한 3*3 패치 중 현재 패치에 가장 가까운 것을 선택해야 하기 때문
3) 가장 유사한 패치를 찾았다면, 현재 패치의 중심점으로부터 이전 패치에서 찾은 유사한 패치의 중심점에 이르는 경로 구함 <= 모션 벡터
4) 다른 패치에 대해서도 이러한 방식으로 모션 백터 계산
import cv2
import numpy as np
# 물체 추적 함수 정의
def start_tracking():
# 비디오 캡쳐 오브젝트 초기화
cap = cv2.VideoCapture(0)
# 프레임에 대한 크기 조정 인자 정의
scaling_factor = 0.5
# 추적할 프레임 수
num_frames_to_track = 5
# 건너뛸 프레임 수
num_frames_jump = 2
# 변수 초기화
tracking_paths = []
frame_index = 0
# 추적 매개변수(윈도우 크기, 최대 수준, 종료 조건) 정의
tracking_params = dict(winSize = (11, 11), maxLevel = 2,
criteria = (cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT,
10, 0.03))
# 사용자가 ESC 키 누를 때까지 반복
while True:
# 카메라에서 현재 프레임 캡쳐
_, frame = cap.read()
# 프레임 크기 조정
frame = cv2.resize(frame, None, fx=scaling_factor,
fy=scaling_factor, interpolation=cv2.INTER_AREA)
# RGB 프레임을 흑백으로 변환
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 복사본 생성
output_img = frame.copy()
# 추적 경로의 길이가 0보다 큰지 확인
if len(tracking_paths) > 0:
# 이미지 가져오기
prev_img, current_img = prev_gray, frame_gray
# 특징점 구성
feature_points_0 = np.float32([tp[-1] for tp in \
tracking_paths]).reshape(-1, 1, 2)
# 광학 흐름 계산 (이전 프레임과 현재 프레임 사이의)
feature_points_1, _, _ = cv2.calcOpticalFlowPyrLK(
prev_img, current_img, feature_points_0,
None, **tracking_params)
# 역(reverse) 광학 흐름 계산
feature_points_0_rev, _, _ = cv2.calcOpticalFlowPyrLK(
current_img, prev_img, feature_points_1,
None, **tracking_params)
# 순 광학 흐름과 역 광학 흐름 사이의 차이 계산
diff_feature_points = abs(feature_points_0 - \
feature_points_0_rev).reshape(-1, 2).max(-1)
# 대표 특징점 추출
good_points = diff_feature_points < 1
# 새로운 추적 경로에 대한 변수 초기화
new_tracking_paths = []
# 추출한 대표 특징점에 대해 루프를 돌며 그 주위에 원을 그림
for tp, (x, y), good_points_flag in zip(tracking_paths,
feature_points_1.reshape(-1, 2), good_points):
# 플래그가 차밍 아니면 건너뜀
if not good_points_flag:
continue
# x, y 좌표를 추가하고 추적할 프레임의 수 초과하지 않는지 확인
# (x, y 지점까지의 거리가 임계점을 넘지 않는지 확인)
# 넘으면 삭제
tp.append((x, y))
if len(tp) > num_frames_to_track:
del tp[0]
new_tracking_paths.append(tp)
# 특징점 주위에 원 그리기
cv2.circle(output_img, (x, y), 3, (0, 255, 0), -1)
# 추적 경로 업데이트
tracking_paths = new_tracking_paths
# 선 그리기
cv2.polylines(output_img, [np.int32(tp) for tp in \
tracking_paths], False, (0, 150, 0))
# 지정된 프레임 수만큼 건너뛰고 나서 if 조건문으로 들어감
if not frame_index % num_frames_jump:
# 마스크 생성한 후 원 그림
mask = np.zeros_like(frame_gray)
mask[:] = 255
for x, y in [np.int32(tp[-1]) for tp in tracking_paths]:
cv2.circle(mask, (x, y), 6, 0, -1)
# 추적할 대표 특징점 계산
# 함수에 여러 가지 매개변수(마스크, 최대 모서리, 품질 수준, 최소 거리, 블록 크기)
# 를 지정해서 호출하는 방식으로 처리
feature_points = cv2.goodFeaturesToTrack(frame_gray,
mask = mask, maxCorners = 500, qualityLevel = 0.3,
minDistance = 7, blockSize = 7)
# 특징점이 있다면 추적 경로에 추가
if feature_points is not None:
for x, y in np.float32(feature_points).reshape(-1, 2):
tracking_paths.append([(x, y)])
# 변수 업데이트
frame_index += 1
prev_gray = frame_gray
# 결과 출력
cv2.imshow('Optical Flow', output_img)
# 사용자가 ESC 키 눌렀으면 빠져나감
c = cv2.waitKey(1)
if c == 27:
break
if __name__ == '__main__':
# 추적기 시작
start_tracking()
# 모든 창(window) 닫기
cv2.destroyAllWindows()7. 얼굴 검출 및 추적
- face detection(얼굴 검출):
- 입력된 이미지에서 얼굴이 있는 지점을 찾아내는 것
- 그 사람이 누구인지를 알아내는 기법인 얼굴 인식과는 다른 개념
- 일반적인 생체 인식 시스템은 얼굴 검출 기법과 얼굴 인식 기법을 모두 활용
7-1. 하 캐스케이드를 이용한 물체 감지
-
Haar cascades(하 케스케이드):
-
Haar feature(하 특징)에 대한 여러 개의 분류기를 순차적으로 거치는 방식으로 물체를 감지하는 기법
-
Viola-Jones(비올라-존스) 기법
- 단순한 분류기들을 여러 단계로 이어서 처리 -> 계산 복잡도 낮으면서 정확도 높아짐 (실시간 처리 위해 계산 복잡도 낮은 것이 요구됨)
- e.g., 테니스 공 추적(감지) 시스템
- 공의 생김새 학습 시스템 필요
- 공이 담긴 방대한 이미지로 학습, 공이 없는 이미지로도 학습 -> 차이점 학습 가능
-
비올라-존스 기법으로 얼굴 검출하는 머신 러닝 시스템 구축하려면:
- 특징 추출기 만들기
- 특징 추출기로 뽑아낸 특징으로 어떤 것이 얼굴인지 판단하는 방법 학습 <- 하 특징 활용
- 하 특징: 여러 이미지 사이의 패치를 단순히 더하고 뺀 것; 계산하기 쉬움
- 확장성을 높이기 위해 다양한 크기의 이미지에 대해 이 작업 수행
- 특징 추출 후 여러 개의 단순 분류기가 차례대로 연결된 분류기에 전달
- 여러 종류의 정사각형 모양의 부분 영역으로 이미지 검사 후 얼굴이 아닌 부분 버림
- 이때 적분 이미지 기법 활용 -> 작업 속도 향상
-
7-2. 적분 이미지를 이용한 특징 추출
- 하 특징 계산 위해 이미지 안의 여러 부분 영역에 대해 덧셈 뺄셈 수행
- 이러한 합과 차는 다양한 크기에 대해 계산되어야
- 계산 복잡도가 높아서 실시간 처리 위해서는 integral image(적분 이미지) 활용해야 함
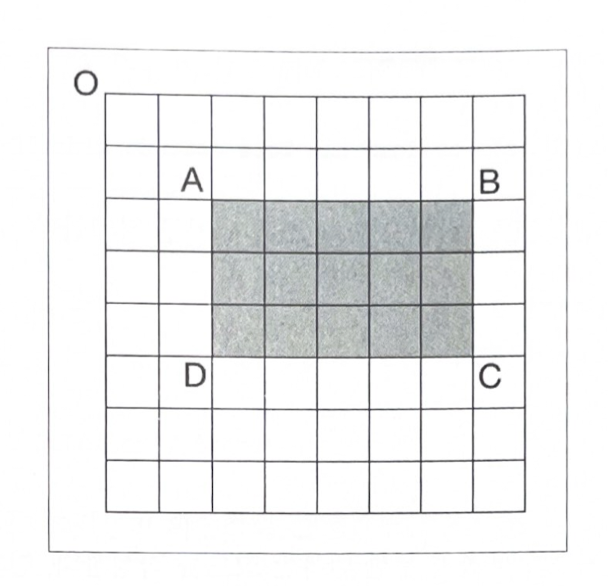
- 직사각형 ABCD의 면적은 픽셀을 일일이 세어보지 않아도 구할 수 있음
- 좌측 상단 모서리 점 O와 대각선 반대 방향 모서리 점 P로 형성된 직사각형의 면적을 OP로 표현하면 직사각형 ABCD의 면적은:
- 직사각형 ABCD의 면적 = OC - (OB + OD - OA)
- 면적 계산 위해 루프 돌거나 직사각형 영역 다시 계산할 필요 없음; 우변의 값들은 이미 이전 단계에서 계산한 것이기 때문
import cv2
import numpy as np
# Haar cascade 파일 불러옴
face_cascade = cv2.CascadeClassifier(
'haar_cascade_files/haarcascade_frontalface_default.xml')
# 파일 체크
if face_cascade.empty():
raise IOError('Unable to load the face cascade classifier xml file')
# 비디오 캡처 오브젝트 초기화
cap = cv2.VideoCapture(0)
# 크기 조정 인자 정의
scaling_factor = 0.5
# 사용자가 ESC 키 누를 때까지 반복
while True:
# 카메라에서 현재 프레임 캡쳐
_, frame = cap.read()
# 프레임 크기 조정
frame = cv2.resize(frame, None,
fx=scaling_factor, fy=scaling_factor,
interpolation=cv2.INTER_AREA)
# grayscale로 변환
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 흑백 이미지에 대해 얼굴 검출기 실행
face_rects = face_cascade.detectMultiScale(gray, 1.3, 5)
# 얼굴 주위에 직사각형 그리기
for (x,y,w,h) in face_rects:
cv2.rectangle(frame, (x,y), (x+w,y+h), (0,255,0), 3)
# 결과 화면 출력
cv2.imshow('Face Detector', frame)
# ESC 눌렸는지 확인하고 빠져나옴
c = cv2.waitKey(1)
if c == 27:
break
# 비디오 캡처 오브젝트 해제
cap.release()
# 창 모두 닫기
cv2.destroyAllWindows()8. 눈 검출 및 추적
- 얼굴 검출과 유사
- 얼굴에 대한 캐스케이드 파일 대신 눈에 대한 캐스케이드 파일 사용하면 됨
Chap.14 인공 신경망
1. 인공 신경망의 개념
- 인공지능의 기본 전제 중 하나: 사람의 지능이 필요한 작업을 기계가 처리하게 하자
- Artificial Neural Network(인공 신경망):
- 인간 두뇌의 학습 과정을 흉내 낸 모델
- 데이터에 존재하는 패턴을 찾아 의미 있는 정보 학습하도록 설계
- 분류, 회귀 분석, segmentation(분할) 등 다양한 작업에 활용 가능
- 시각, 문자, 시계열 등 다양한 형태의 현실 데이터를 숫자 형태로 변환해야 신경망에 입력 가능
1-1. 신경망 구축 방법
-
사람의 학습 과정: 계층적 구성 -> 주어진 물체에 관련된 여러 특성을 순식간에 구분하여 물체를 식별함
-
사람 뇌 신경망:
- 여러 stage(단계)로 구성
- 데이터를 세분해 분석, 처리하는 정도가 각 단계마다(, 작업의 종류와 대상마다) 다름
- 단순한 대상만 학습, 복잡한 대상을 학습 등
- e.g., 상자 시각적 인식 과정:
stage 1) 모서리, 꼭지점 등 단순한 대상만 파악
stage 2) 전반적 모양 파악
stage 3) 상자의 종류 구분
-
인공 신경망:
- neuron을 여러 layer(계층)로 쌓는 방식으로 구성
- 각 계층은 독립적인 뉴런의 집합으로 구성됨
- 한 계층에 속한 뉴런은 인접 계층의 뉴런과 연결됨
1-2. 신경망 학습 방법
-
N차원의 입력 데이터를 처리하기 위해 입력 계층은 N개의 뉴런으로 구성됨
-
M개의 독립적인 클래스로 구분한 학습 데이터를 처리하기 위해 출력 계층은 M개의 뉴런으로 구성됨
-
입출력 계층 사이에 존재하는 계층을 hidden layer(은닉 계층, 내부 계층, 중간 계층)라고 함
-
간단한 신경망은 2계층으로, deep neural network(심층 신경망)은 여러 계층으로 구성됨
-
데이터 분류 작업을 신경망으로 구현하는 경우:
- 적절한 학습 데이터를 수집하여 레이블을 붙임
- 각각의 뉴런은 함수처럼 작동, 여러 개의 뉴런으로 구성된 신경망은 오차가 일정 수준 이하가 될 때까지 데이터를 학습함
- 오차 = |인공 신경망으로 계산된 예측 값 - 실측 값(레이블)|
- 오차가 크면 신경망을 조정해 정답에 근접할 때까지 다시 학습함
-
아래 예제 구현 시 NeuroLab 라이브러리 사용
2. 퍼셉트론 기반 분류기 구현 방법
-
Perceptron:
- 인공 신경망의 기본 구성 요소
- 입력을 받아 연산 수행 후 결과 출력하는 하나의 뉴런으로 구성
- 의사 결정은 간단한 선형 함수로 내림
- N차원 입력 데이터 포인트를 처리하는 경우:
- 하나의 퍼셉트론은 N개의 숫자에 대한 weighted sum(가중치 합)을 구한 후 여기에 상수를 더해서 결과 출력함
- 이 상수를 뉴런의 bias(편중 값)이라고 함
- 이렇게 단순한 퍼셉트론만으로 복잡한 심층 신경망 만들 수 있음
-
뉴로랩 라이브러리로 퍼셉트론 기반 분류기 만들기 시작
import numpy as np
import matplotlib.pyplot as plt
import neurolab as nl
# 입력 데이터 가져오기
text = np.loadtxt('data_perceptron.txt')
# 데이터 포인트와 레이블로 나누기
data = text[:, :2]
labels = text[:, 2].reshape((text.shape[0], 1))
# 입력 데이터 그래프 그리기
plt.figure()
plt.scatter(data[:,0], data[:,1])
plt.xlabel('Dimension 1')
plt.ylabel('Dimension 2')
plt.title('Input data')
# 각 차원에 대한 최댓값, 최솟값 지정하기
dim1_min, dim1_max, dim2_min, dim2_max = 0, 1, 0, 1
# 출력 계층에 있는 뉴런의 수
# 데이터를 두 개의 클래스로 분리했기에 하나의 비트만으로 결과 표현 가능
# 따라서 출력 계층은 하나의 뉴런으로 구성됨
num_output = labels.shape[1]
# 2개의 입력 뉴런으로 구성된 퍼셉트론 정의
# 입력 데이터가 2차원이기 때문
# 각 차원마다 하나의 뉴런 할당
dim1 = [dim1_min, dim1_max]
dim2 = [dim2_min, dim2_max]
perceptron = nl.net.newp([dim1, dim2], num_output)
# 학습 데이터로 퍼셉트론 학습 시키기
error_progress = perceptron.train(data, labels, epochs=100, show=20, lr=0.03)
# 학습 과정을 그래프로 표시
# 오차 값 기준
plt.figure()
plt.plot(error_progress)
plt.xlabel('Number of epochs')
plt.ylabel('Training error')
plt.title('Training error progress')
plt.grid()
plt.show()
# 첫 번째 화면은 입력 데이터 포인트를 보여줌
# 두 번째 화면은 오차 값을 이용한 학습 진행 상태 보여줌
# 4번째 학습 주기(epoch)가 끝나는 시점에 오차가 0으로 떨어짐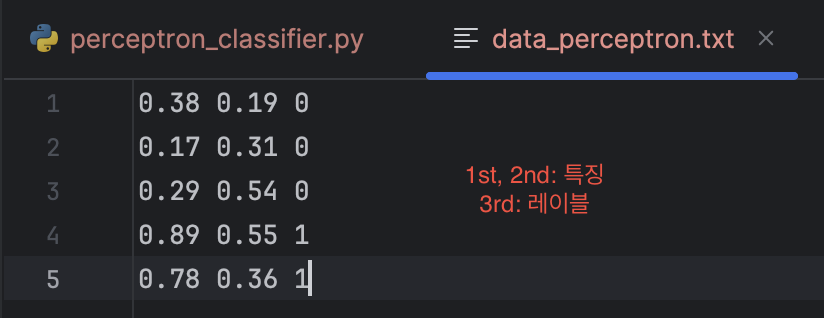

EunSeo Ko