Redis의 캐싱전략
먼저 캐싱 전략이 무엇인지부터 알아보도록 하겠다. 캐싱전략은 Redis나 Caching을 제공하는 서비스, 소프트웨어를 사용할 때, 어떠한 전략을 기반으로 서비스 로직을 구성할지에 대해서 일종의 설계의 영역이라고 생각하면 된다. 대표적으로 세 가지 정도의 캐싱 전략을 세우고있다. Look Aside(Lazy Loading)와 같은 읽기 전략과 Write Around. Write Thoght같은 쓰기 전략등이 있다.
캐싱전략
**주의**이 글에서 소개하는 Redis의 캐싱전략은 강의를 듣고 정리한 글임을 미리 밝힌다. 캐싱 전략의 모든 부분을 다루는 것이 아니므로 이 글을 읽고 궁금한 점이 있다면 다른 블로그 및 공식 기술문서를 참고하는 것을 권장한다.
1. Look Aside ( feat. Lazy Loading )
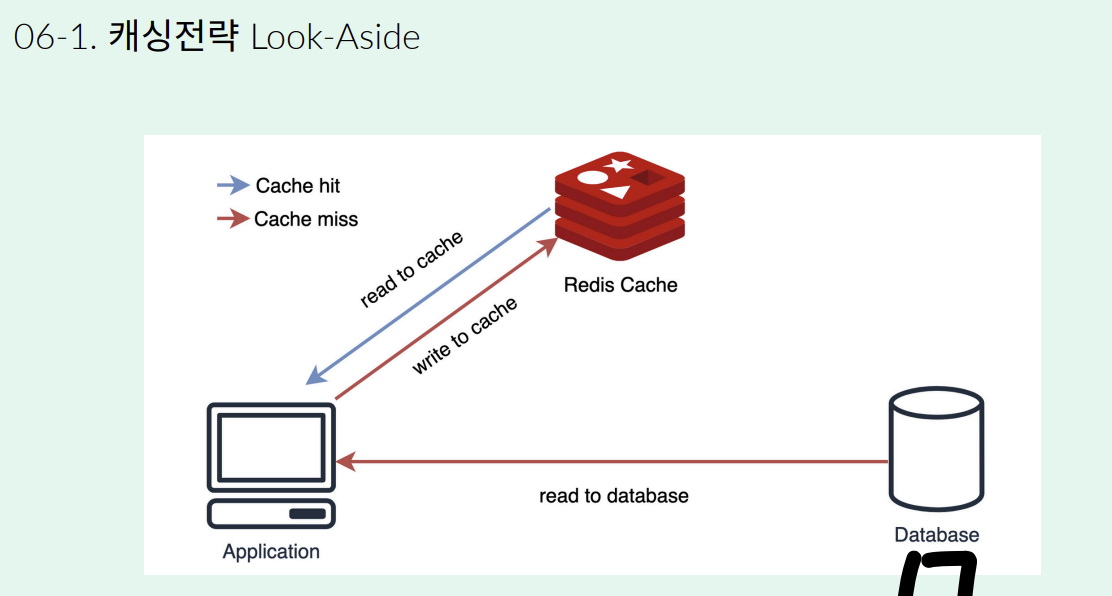
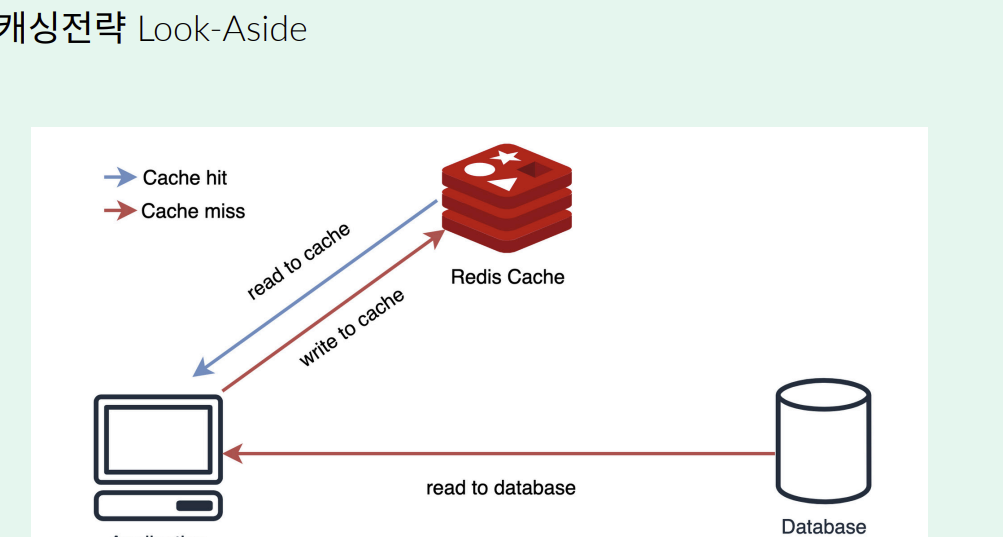
데이터를 먼저 Redis에서 읽고 없다면 DB에서 가져오는 읽기 전략이고, 가장 많이 사용된다. ( 위 그림에서는 읽기 + 쓰기 전략이 같이 사용된 상태이다. )
데이터를 가져오는 것에 중점이 되어있기 때문에, 데이터베이스와 실제 레디스 캐시가 저장되어 있는 데이터에 대해서 데이터의 영속성이 좀 깨질수 있다. 그러니까 실제 DB에 있는 값과 Redis를 통해서 호출되는 값이 다를 수 있다는 의미이다.
위 그림에서는 Look Aside라는 읽기 전략뿐 아니라, Write to Cache라는 쓰기 전략도 함께 사용되고 있다. 위 그림이 Redis 사용 시 대표적으로 사용되는 방법이라고 한다.
먼저 요청이 들어온다고 가정하자. 요청이 들어오게 되면 먼저 애플리케이션은 Reids와 통신을 하게 된다. Redis에서 받은 요청에 대한 Cache Key가 있다면 굳이 DB를 갖다 올 필요가 없게된다. 바로 응답을 받게 되는 것이다.
하지만 만약 Redis에 내가 원하는 Cache Key가 없다면, 데이터 베이스를 확인하게 된다. 결국 DB와 통신하여 원하는 값을 가져오게 되는 것이다. 이 떄 이 응답 값을 바로 넘겨주는 것이 아니라 Redis를 향하게 한다. 이 때 Key를 생성해서 캐시로써 저장을 해두고, 그 다음에 정상적인 응답을 반환한다.
이 상황에서 데이터의 영속성이 깨질 수가 있다. 특정 키에 대한 캐시 값이 없는 경우에는 DB와 통신하여 값을 가져가다 사용하면 된다. 하지만 캐싱된 값이 존재한다면 ? 그냥 가져다 사용하면 되지 않느냐? 할 수도 있다. 하지만 이러한 경우에는 DB가 두 개 이므로 두 데이터베이스간 동기화가 이루어지지 않았을 가능성을 염두에 두어야 한다. 레디스에서 특정 키에 대한 값이 있다면 RDB와 교차검증을 하지는 않는다. 그러면 굳이 DB에서 가져오지 로직이 복잡해지고 비효율적이도록 서비스 단을 구성하지 않을테니 말이다.
예를 들어 A라는 키에 대한 Redis의 값은 5고 DB에 있는 값은 7이라고 가정해보겠다.
클라이언트에게 응답할 값이 만약 캐싱된 값 "5"를 반환한다면, 이는 두 DB간의 동기화가 이루어지지 않아 데이터 정합성에 어긋나게 된다.
실제 DB에 있는 정상적인 "7"이라는 값을 반환하지 못한 것이다.
그렇다면 이러한 문제를 어떻게 해결할까 ?
정답은, 캐싱 데이터를 어떤 경우에 사용할지 설계를 잘 해야한다는 것이다. 동기화가 조금 느려도 되는 랭킹 및 히스토리 데이터같은 경우에는 사용해도 되지만, 재고 여부, 금전 관련 및 기타 동기화가 이루어지지 않았을 때 큰 문제가 발생할만한 부분에는 사용하지 않아야 한다.
이 전략에 대해서는 우연히 많은 클라이언트가 동시에 같은 리소스에 접근을 시도할 때 발생할 수 있는 문제가 있는데. 이를 Thundering herd problem라 한다.
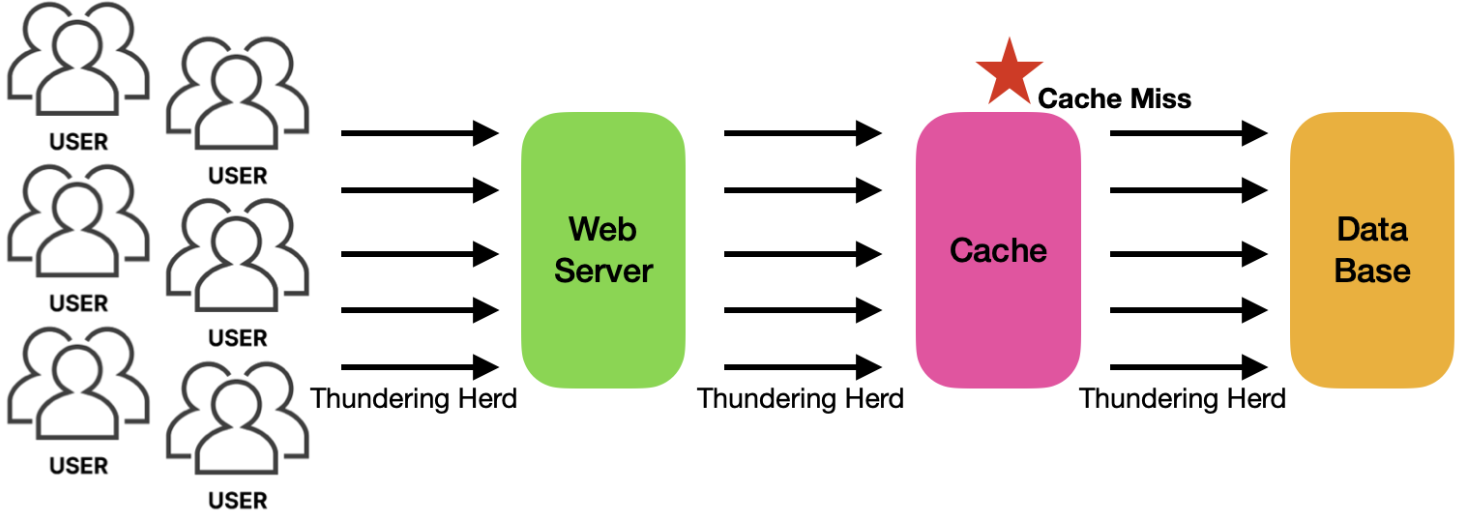
위 그림처럼 Thundering herd problem 문제는 우연히 캐싱 값이 설정된 TTL이 지나 소멸되었을 때 DB에 트래픽이 과도하게 몰려 DB가 높은 부하를 받은 상황을 일컫는다. 이러한 경우에는 분산 락, 캐시 리로딩 등 적절한 전략을 통해 해결이 가능하다. 이 부분에 대한 예시는 정리가 잘 된 블로그가 있어 대체하도록 하겠다. 또한 네이버 라인 기술 블로그도 참고하면 좋을듯 하다. 정말 자세하게 정리해놓았다.
나머지 전략에 대해서는 이 링크를 참고해주면 좋겠다.
