Redis
1.Redis 도입 배경 및 개요

현재 진행중인 프로젝트에서 왜 Redis를 사용하게된 도입 배경 및 간략한 개요에 대해 설명합니다.
2.Redis 자료구조 : String Collection

Redis의 String 자료구조는 단순한 Key-Value 저장 방식으로, 하나의 Key에 하나의 Value를 매핑한다. 이때 Value는 문자열뿐만 아니라 숫자, 바이너리 데이터(예: 이미지) 등 다양한 형식을 지원한다.1\. SETKey-Value를 저장하는 기본
3.Redis 자료구조 : List Collection
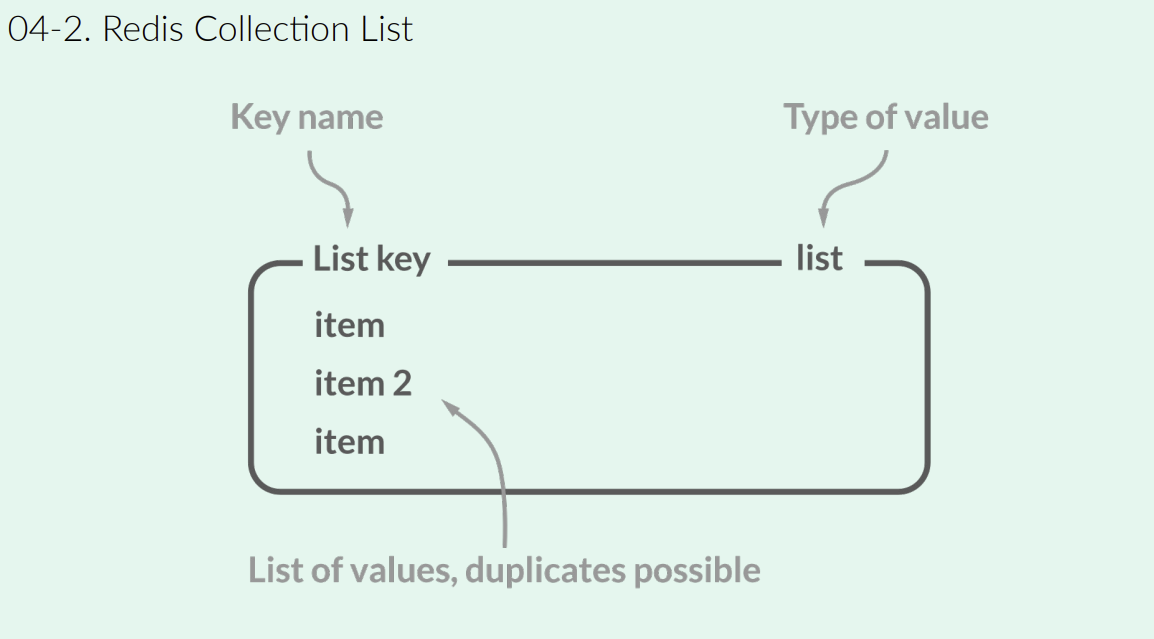
출처 : https://healthcoding.tistory.com/48 Redis의 List는 Linked-List 형태로 구현된 자료구조이다. 이는 양방향으로 데이터를 빠르게 추가/제거할 수 있는 특성을 가지고 있어, 특정 사용 사례에서 매우 효율적인 성능
4.Redis 자료구조 : Set Collection
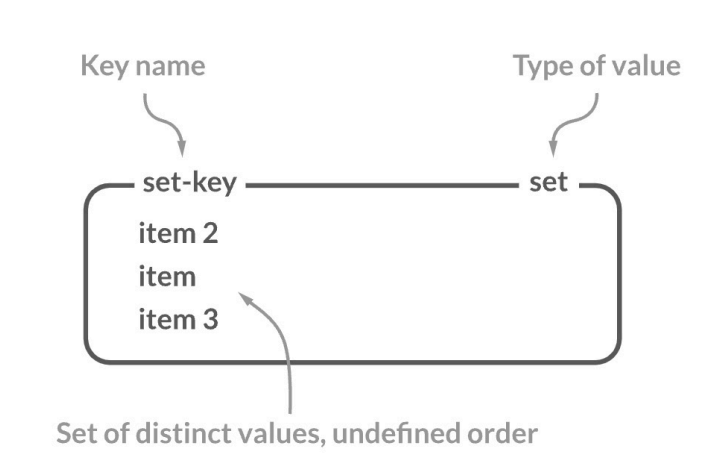
Redis의 Set 자료구조는 중복 없이, 정렬되지 않은 문자열의 모음이다. 하나의 Key에 대해 여러 개의 Value를 저장할 수 있으며, 중복 데이터는 허용되지 않는다. 또한, Redis에는 Sorted Set도 제공하며, 이는 Set에 정렬 기능이 추가된 형태다.
5.Redis 자료구조 : Hash Collection
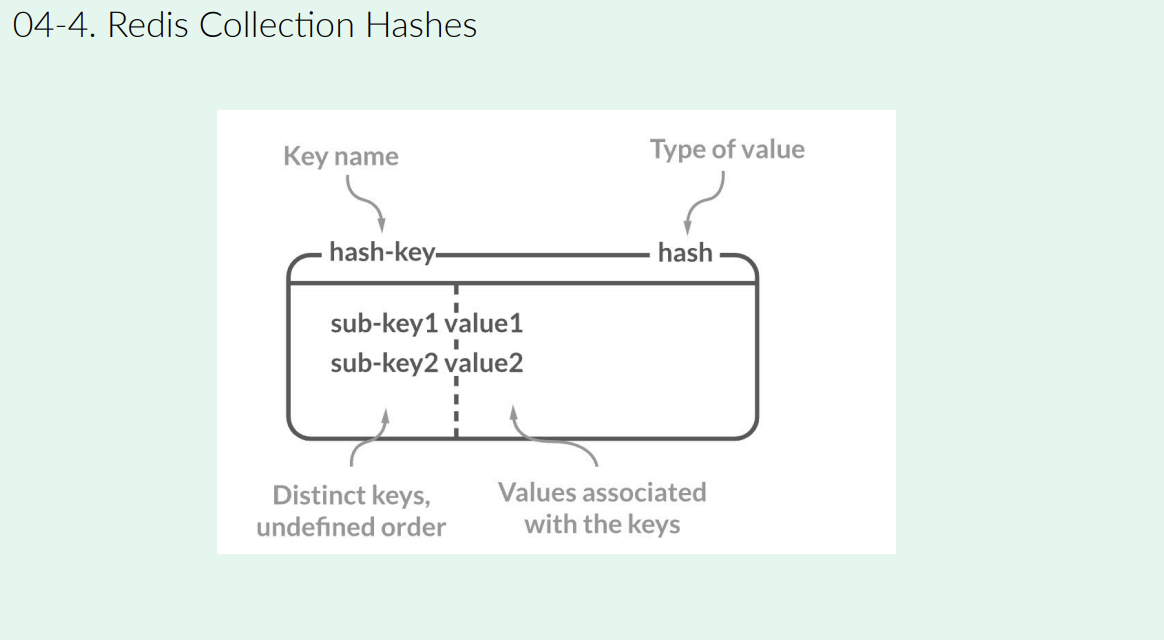
Redis의 Hash는 하나의 키 아래 여러 필드와 값을 구성할 수 있는 데이터 구조이다. 이는 RDB의 테이블에서 여러 컬럼과 비슷한 역할을 하지만, 컬럼 갯수에 제한이 있는 RDB와 달리, Redis Hash는 최대 40억 개의 필드와 값을 저장할 수 있다고 한다.
6.Redis 자료구조 : BitMap Collection

BitMap은 특정 키 값에 대해 비트 구조의 배열을 만들어 0과 1로 데이터를 구분하는 방식이다. 주로 쿠폰 발급과 같은 기능에서 사용된다. 예를 들어, 100만 명의 사용자에게 쿠폰을 발급할때, String 방식으로 각 사용자의 쿠폰 발급 여부를 관리하려면 100만
7.MemCached Vs Redis

Memcached는 고성능의 분산 메모리 캐시 시스템으로, 주로 데이터베이스 부하를 줄이고 애플리케이션의 성능을 향상시키기 위해 사용된다. 데이터를 메모리에 저장하여 빠른 읽기/쓰기 속도를 제공한다.Redis는 오픈 소스, 고성능의 인메모리 데이터 구조 저장소로, 다양
8.Redis의 캐싱전략(1)
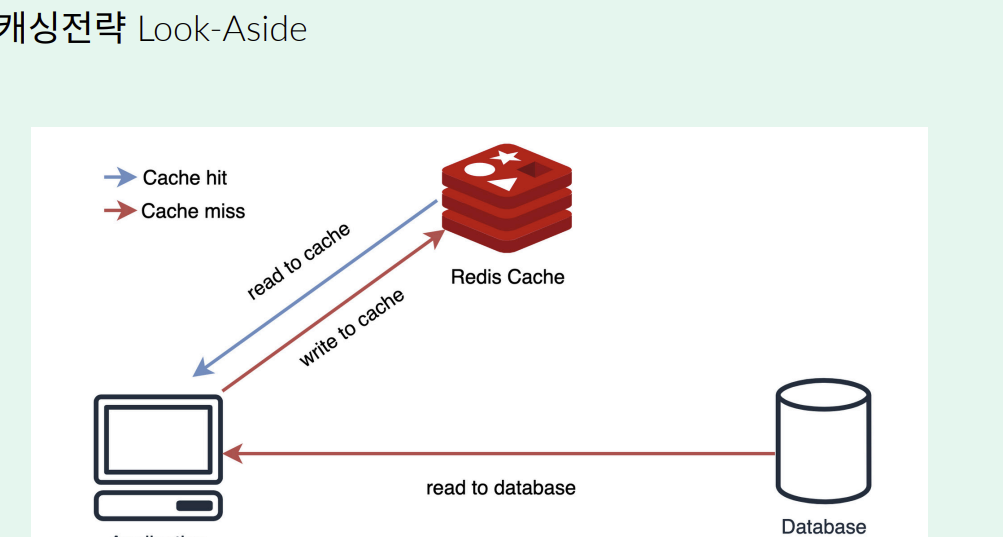
먼저 캐싱 전략이 무엇인지부터 알아보도록 하겠다. 캐싱전략은 Redis나 Caching을 제공하는 서비스, 소프트웨어를 사용할 때, 어떠한 전략을 기반으로 서비스 로직을 구성할지에 대해서 일종의 설계의 영역이라고 생각하면 된다. 대표적으로 세 가지 정도의 캐싱 전략을
9.Redis의 캐싱전략(2)

Write Back은 조회보다는 DB의 지속적인 업데이트를 위해 사용하는 전략이다. Redis에 데이터를 인메모리 방식으로 저장한 뒤, 크론 작업이나 잡 큐를 통해 일정 주기로 데이터를 DB에 반영하는 방식이다.어디에 활용이 되는가 ?예를 들어, 좋아요 요청을 구현할
10.Redis의 데이터 영속성

Redis의 데이터 영속성 Redis에서 데이터 영속성이란? Redis는 인메모리 기반 데이터베이스로, 서버가 다운되면 모든 데이터가 휘발된다. 이러한 단점을 보완하기 위해 데이터를 디스크에 저장하여 영속성을 보장하는 방법을 제공하며, 대표적으로 AOF(Append
11.Redis 아키텍처
Redis의 아키텍처 1. Simple Database Redis 메인 서버를 하나만 구동하는 형식의 아키텍처이다. 배포가 매우 간단하며, 사용자가 큰 어려움 없이 구축할 수 있다는 장점이 있다. 그러나 단 하나의 인스턴스만 사용하는 구조이기 때문에 해당 인스턴스에
12.Redis Pub/Sub

Redis의 Pub/Sub 구조는 메시지 발행/구독(Publish/Subscribe)을 기반으로 하는 메시징 패턴이다. 이 구조는 Kafka나 RabbitMQ와 같은 Pub/Sub 기반 메시징 시스템에서 주로 사용하는 Event-driven 방식의 한 예시로, 비동기
13.Redis Lua Script

이번 포스팅의 주제는 Redis의 Lua Script이다. 우선 Lua Script가 무엇인지부터 알아보도록 하겠다.Redis에서 Script를 사용할 수 있는 방법이다. 익숙해지는데 시간이 걸릴 수는 있으나 사용했을 시 이점이 굉장히 많으므로 알아두면 좋지않을까 싶다
14.Redis의 Cluster 구성 시 Hash Slot
문득 강의를 듣다가 Redis의 Cluster 구조에서는 각 노드에 어떻게 데이터가 분배되는지가 궁금해졌다. 사실은 클러스터 구조에서 mod16384 연산을 통해 얻은 해싱 값이 특정 해시 슬롯에 저장이 된다고 착각하는 바람에 시간을 너무 많이 썻고 결국은 내 오해였다