제로베이스 데이터 취업 스쿨 4주차 스터디노트 3호
이슈
원래 표는 다음과 같았다.
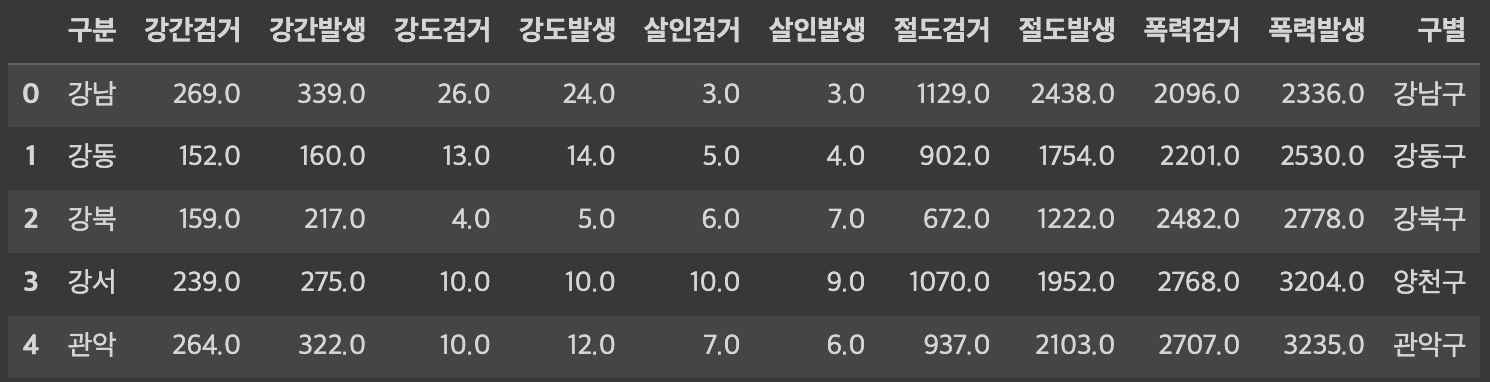
여기서 [구별] 열을 index로 했다.
crime = pd.read_csv(DIR + 'crime-sublocal.csv') \
.set_index("구별")
crime.head()그러나 [구별] 열은 중복 데이터를 담고 있었다.
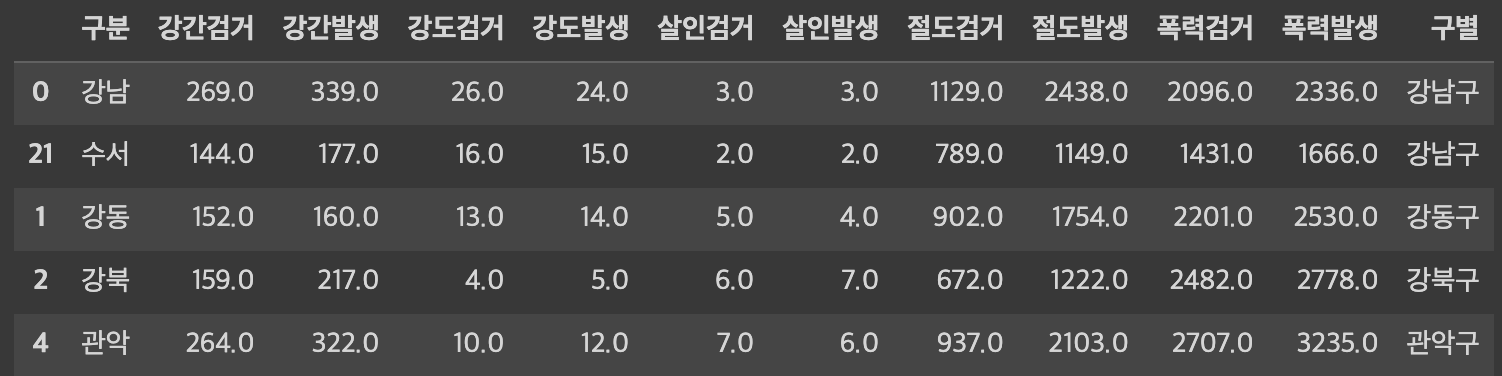
그리고 set_index는 중복값에 대해 자비없이 삭제해버린다...
(위 표를 보면 강남구가 두 곳이므로, 합을 내든 평균을 내든 처리를 해주어야 한다)
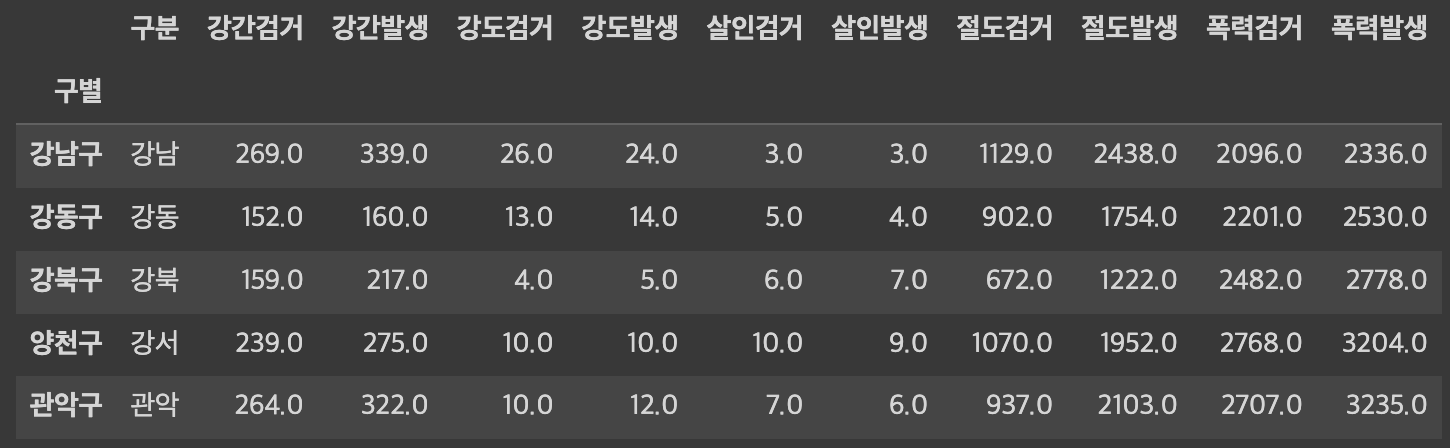
따라서 index 변경을 정확하게 하려면
.pivot_table 메소드를 활용해서 중복값을 처리해주어야 한다.
(참고로, .pivot 메소드도 존재하지만 이는 aggfunc parameter이 존재하지 않는다. 하지만 이 메소드의 경우 column이 required parameter이다)
crime = pd.read_csv(DIR + 'crime-sublocal.csv') \
.drop(columns="구분") \ # 글자는 np.sum으로 합칠 수 없으므로 미리 제거
.pivot_table(index="구별", aggfunc=np.sum)
crime.head()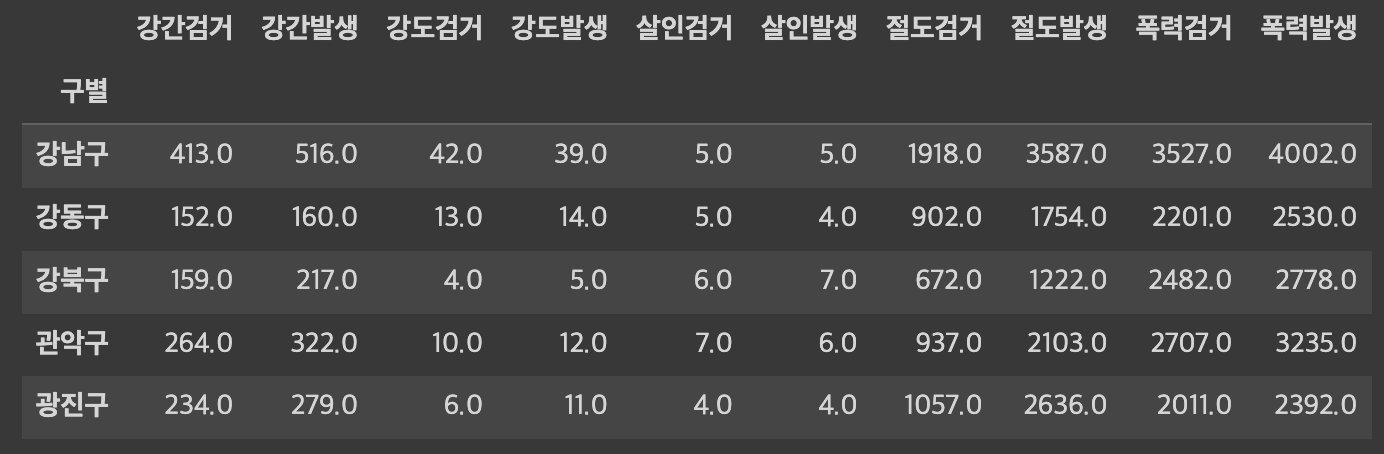
만약 set_index 메소드를 꼭 쓰고싶다면 다음의 과정이 필요하다.
(하지만 쓸 이유가 없다. 왜? 문제 시 에러를 발생하는 것 뿐,
결과 테이블을 제공해주지 못한다...)
crime = pd.read_csv(DIR + 'crime-sublocal.csv') \
.set_index("구별", verify_integrity=True)
crime.head()이렇게 사용 시 친절하게 에러를 발생시켜준다.
(이렇게 반가울수가... 흑흑)

참고문서 >>> 링크
결론
.set_index를 활용한다면, verify_integrity flag나 .unique() 메소드를 사용하여 중복값 존재 여부를 꼭 확인해주자.

Impact