제로베이스 데이터 취업 스쿨 3주차 스터디노트 6호
이슈 정리
처음에 봤을땐 이게 뭐지? 하면서 동공지진 했는데,
다시 실행해보니 Colab 특성 상 생길 수 있는 이슈 같다.
일반 Code editor나 IDE에서는 이슈가 아니라는 말씀.
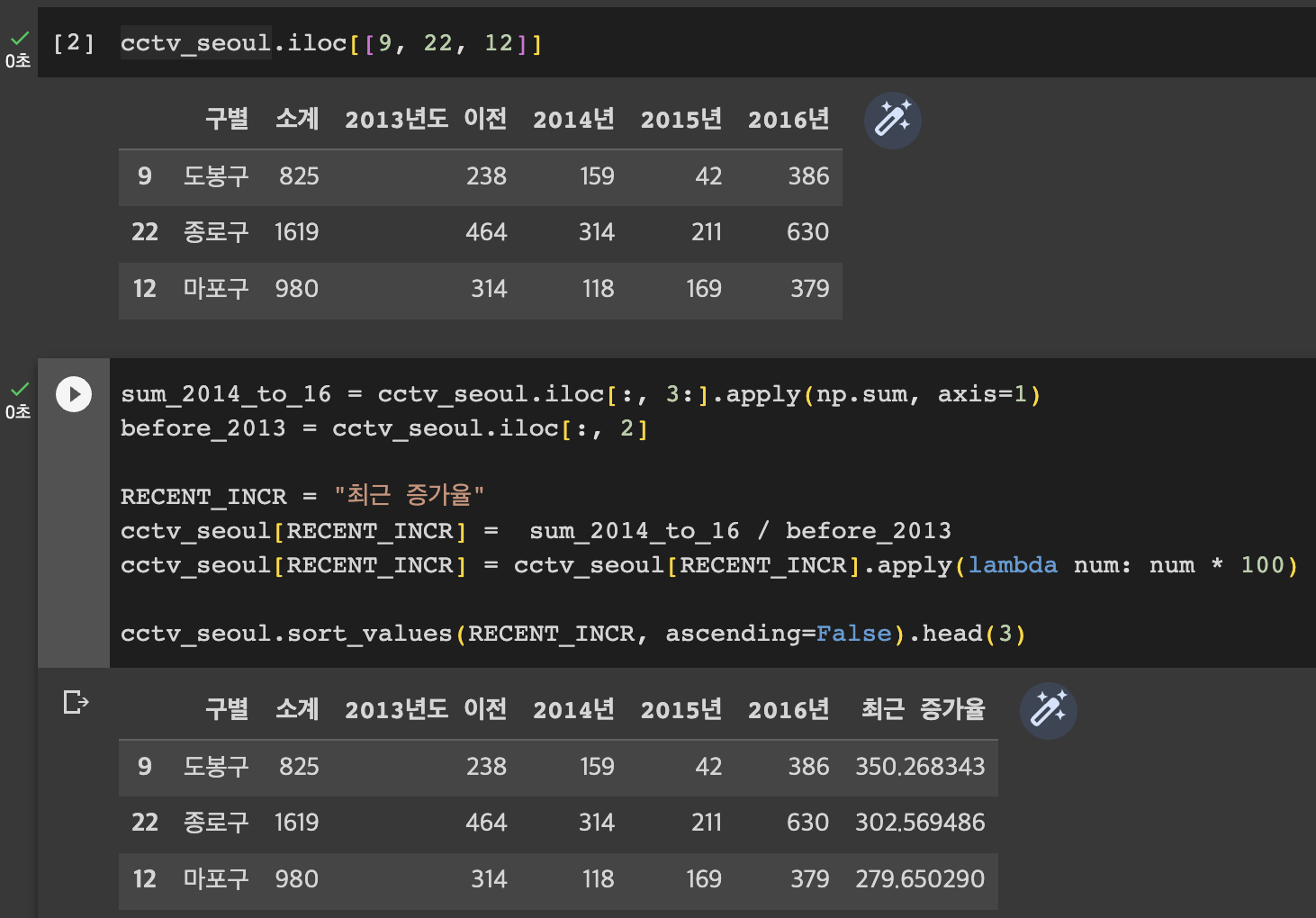
(2014년 + 2015년 + 2016년) / 2013년 이전 * 100
최근 CCTV 증가율을 계산하기 위한 연산이다.
그러나 수업을 들으며 보니까,
수업과 내 코드의 최근 증가율의 값이 달랐다.
이유가 무엇이었을까?
이유는,
최근 CCTV의 값에 최근 증가율이 합산되었기 때문이다.
cctv_seoul.iloc[:, 3:]에서,
3번째 열 이후의 값을 모두 더했기 때문이다.
즉, 연산이 아래와 같이 되었던 것이다.
최근 증가율 = (최근 증가율 + 2014년 + 2015년 + 2016년) / 2013년 이전 * 100
처음 발견했을 땐 python이 코드 순서대로 실행되지 않는건가?
하는 의문을 품었었다.
오늘 포스팅을 하기 위해 실행해보니,
최초 실행 때에는 정상값이 나오는 것을 확인했다.
(저번 실행 때에는 sorting을 안한 상태로 코드 블럭을 실행했다가,
sorting을 하기 위해 재실행을 해서 처음부터
위와 같은 문제를 발견하게 되었던 듯 하다)
앞서 말했던 문제가 될 수 있는 Colab의 특성이다.
다만, Colab이 문제가 있는 것은 아니다.
메모리가 초기화되지 않기 때문에
우리는 Colab을 interactive하게 사용할 수 있다.
그리고 그로 인한 경계사항?으로 볼 수 있겠다.
따라서,cctv_seoul.iloc[:, 3:] 보다는
cctv_seoul.iloc[:, 3:6]으로 명시해주는 것이 좋겠다.
추가로, label에 대해서 :을 사용하여 slicing하는 경우에는
뒤의 값을 포함하고,
숫자에 대해서 :을 사용하여 slicing하는 경우에는
뒤의 값을 포함하지 않는다는 사실!
염두에 두고 pandas를 사용해야 할 듯 하다.
그리고... 하나 더
만약, 내가 강의를 듣는게 아니라 직접 조사를 하고 있었던 거라면?
만약, 수치가 3~4개 정도가 아니라 몇십개 이상이었다면?
그래서 직접 계산해볼 생각도 하지 못했더라면?
나는 이 이슈를 발견하지 못했을 것이다.
프로그래밍 경험이 있다면,
에러가 나는 코드보다 무서운 것이
에러가 나지 않는데, 정상으로 실행되는 코드일 것이다.
내가 이 이슈를 접하면서 가장 두려웠던 점은,
데이터는 에러를 뱉지 않는다는 것이다.
작은 실수 하나가 데이터를 오염시키고
합리적인 듯 합리적이지 않은, 잘못하면 위험한 선택으로 이르게 할 수 있다.
받아들이고 싶지 않은 섬뜩한 사실이다...
스스로의 산출물에 대하여 종종 의심하고,
나름의 검증 프로세스가 필요할 듯 하다.
