제로베이스 데이터 취업 스쿨 4주차 스터디노트 6호
서론
EDA는 탐색적 데이터 분석이다.
사실 지난 범죄 시각화 때 그래프만 그리고 분석은 안했다.
무지성 개발자로 일하던 안 좋은 습관이다.
정상적으로 구현되면 구현 결과물에 대해서는 생각하지 않는 것이다.
그런 의미에서 이번에는 seaborn 시각화 결과물에 대해 분석을 해보려고 한다.
음... 범죄 데이터는 데이터 자체가 너무 무섭다.
살인, 폭력 등... 좀 좋은? 내용은 없었을까ㅠ
분석
- 가설: 인구 당 CCTV 수가 높을수록 범죄율이 낮아지고 검거율이 높아질 것이다.
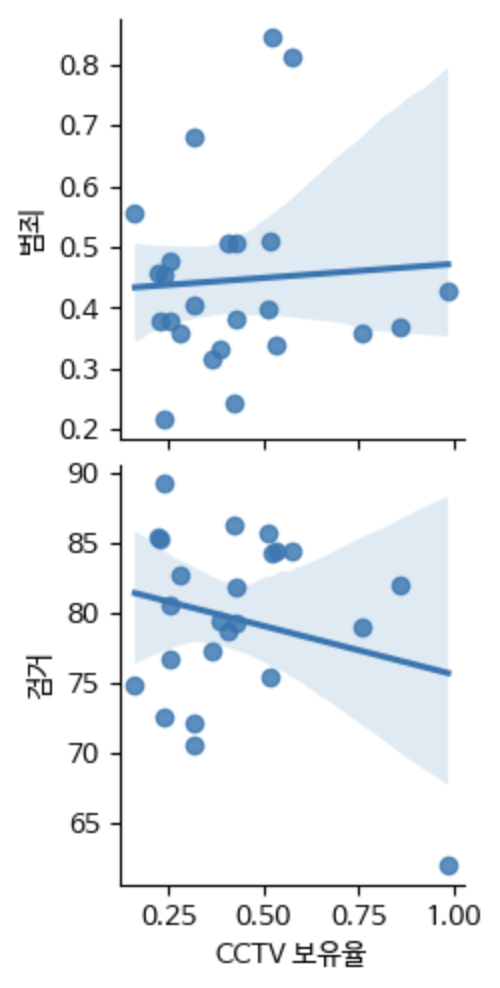
sns.pairplot(crime, x_vars=["CCTV 보유율"], y_vars=["범죄", "검거"], kind="reg")음... 결과물을 보면 오히려 CCTV 보유율과 범죄율은 양의 기울기고,
CCTV 보유율과 검거율은 음의 기울기였다.
이 데이터로 새로운 가설을 세울 수 있다.
범죄율이 높고, 검거율이 낮으면 이에 대응하기 위해 CCTV를 설치하지만,
CCTV의 효과가 그리 높지 않다고 생각할 수 있다.
1-1. robust=True
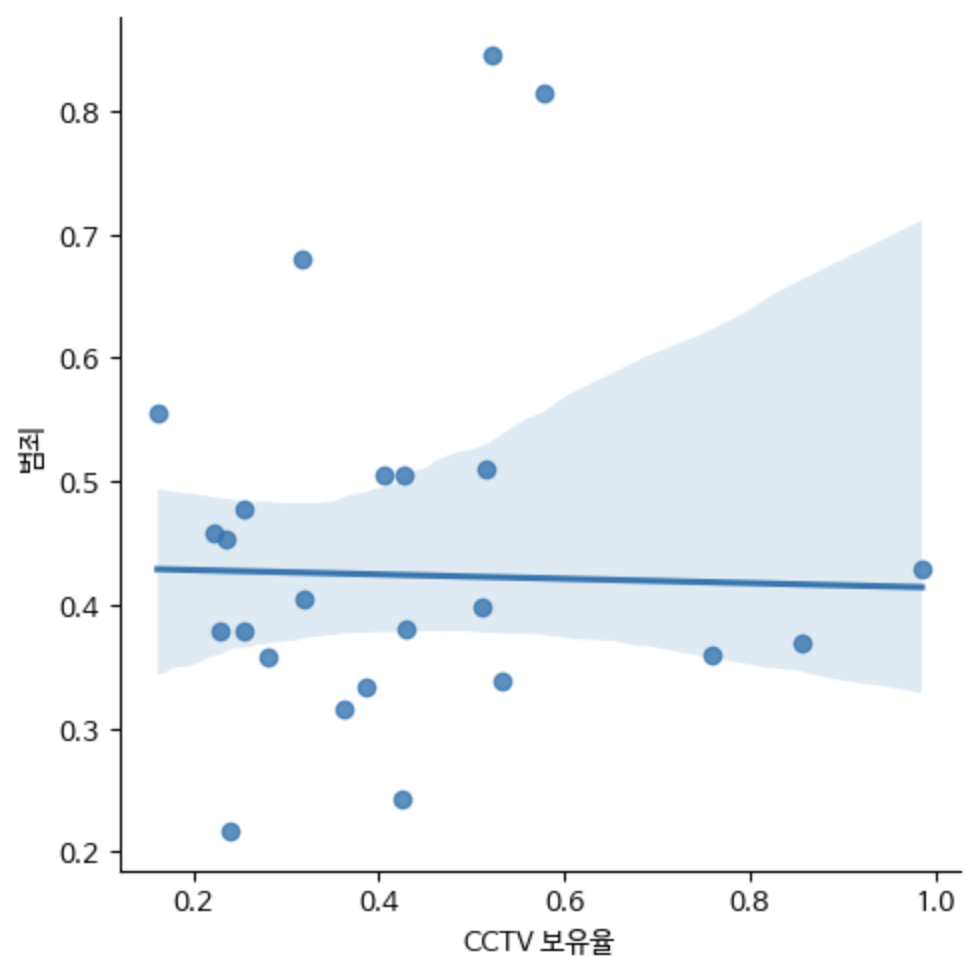
sns.lmplot(crime, x="CCTV 보유율", y="범죄", robust=True)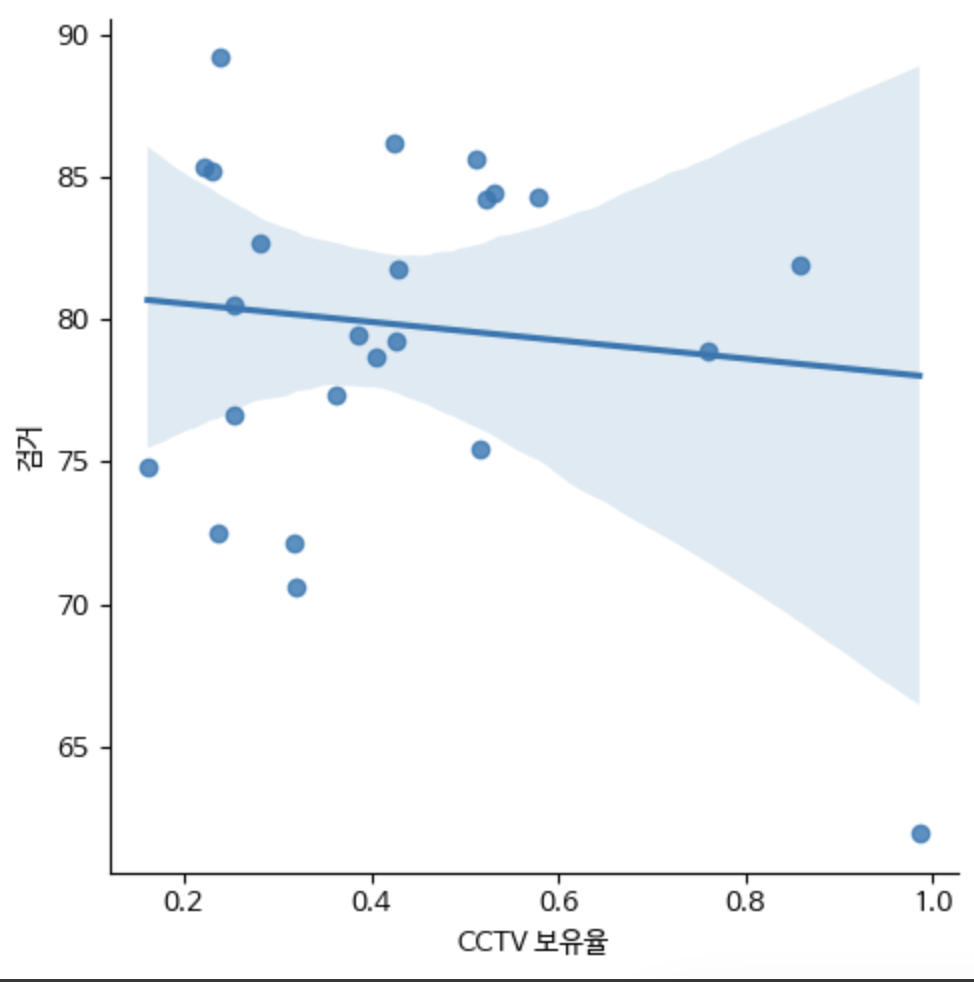
sns.lmplot(crime, x="CCTV 보유율", y="검거", robust=True)CCTV 보유율과 범죄율 관계의 경우, outlier의 영향력이 크다는 사실을 알 수 있다.
왜냐하면 outlier의 영향력을 줄이는 robust parameter을 True로 주자,
기존에 양의 기울기였던 회귀직선이 음의 기울기로 바뀌었기 때문이다.
- 가설: 강도, 폭력과 살인은 상관관계가 있을 것이다.
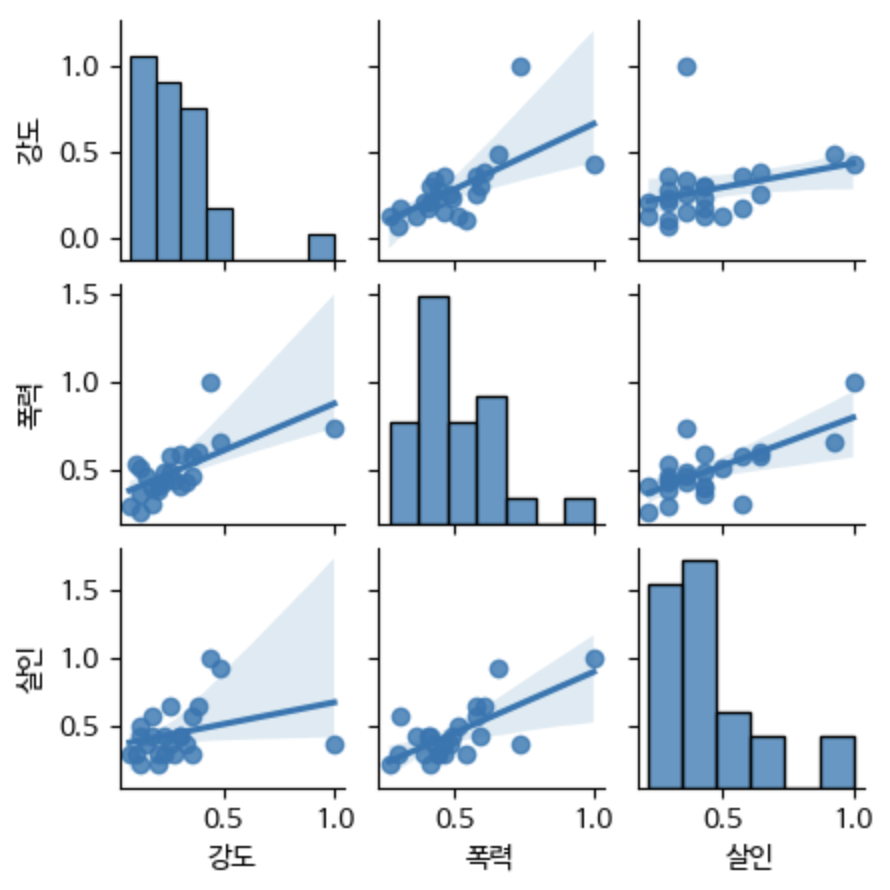
targets = crime[["강도", "폭력", "살인"]]
sns.pairplot(targets, kind="reg", height=1.5)강도, 폭력, 살인은 모두 상관관계가 있긴 하다.
다만, 폭력이 다른 범죄와 상관관계가 있고,
나머지는 있긴 하나 비교적 약한 상관관계가 있다.
- 범죄율, 검거율 Heatmap
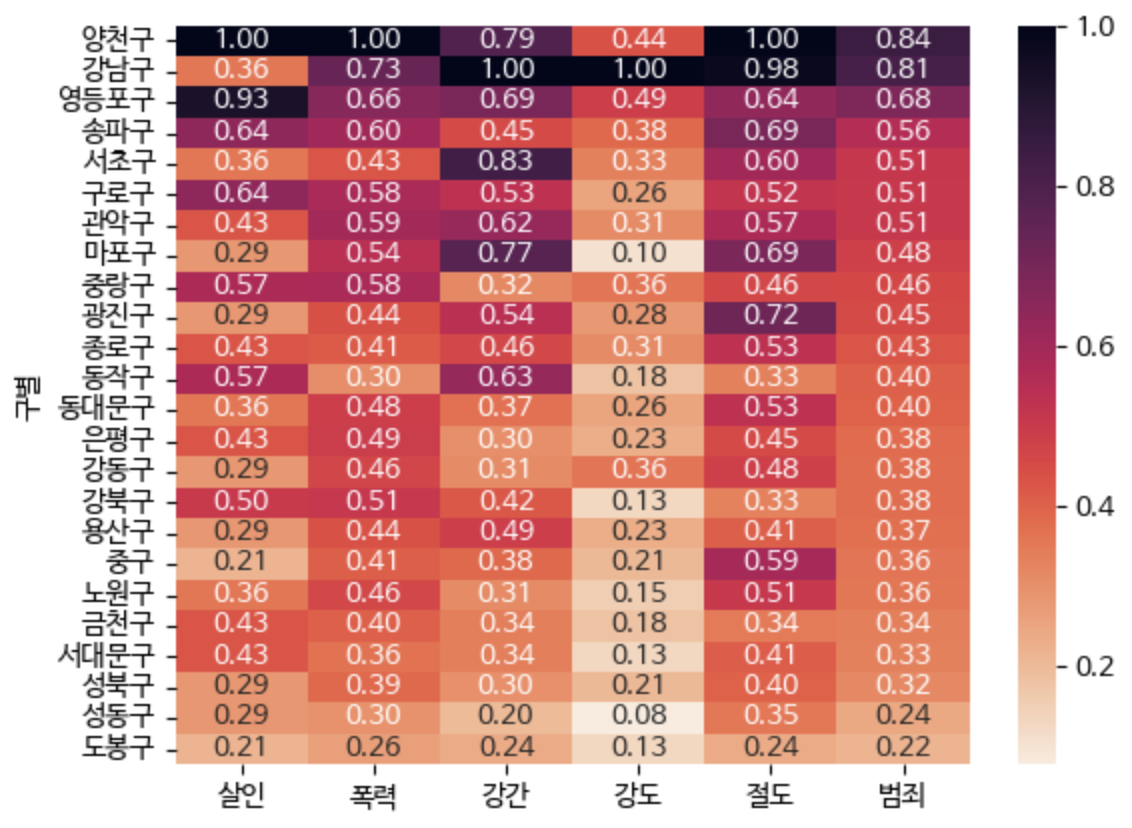
targets = ["살인", "폭력", "강간", "강도", "절도", "범죄"]
sorted_data = crime[targets].sort_values("범죄", ascending=False)
sns.heatmap(sorted_data, cmap=sns.cm.rocket_r, annot=True, fmt=".2f")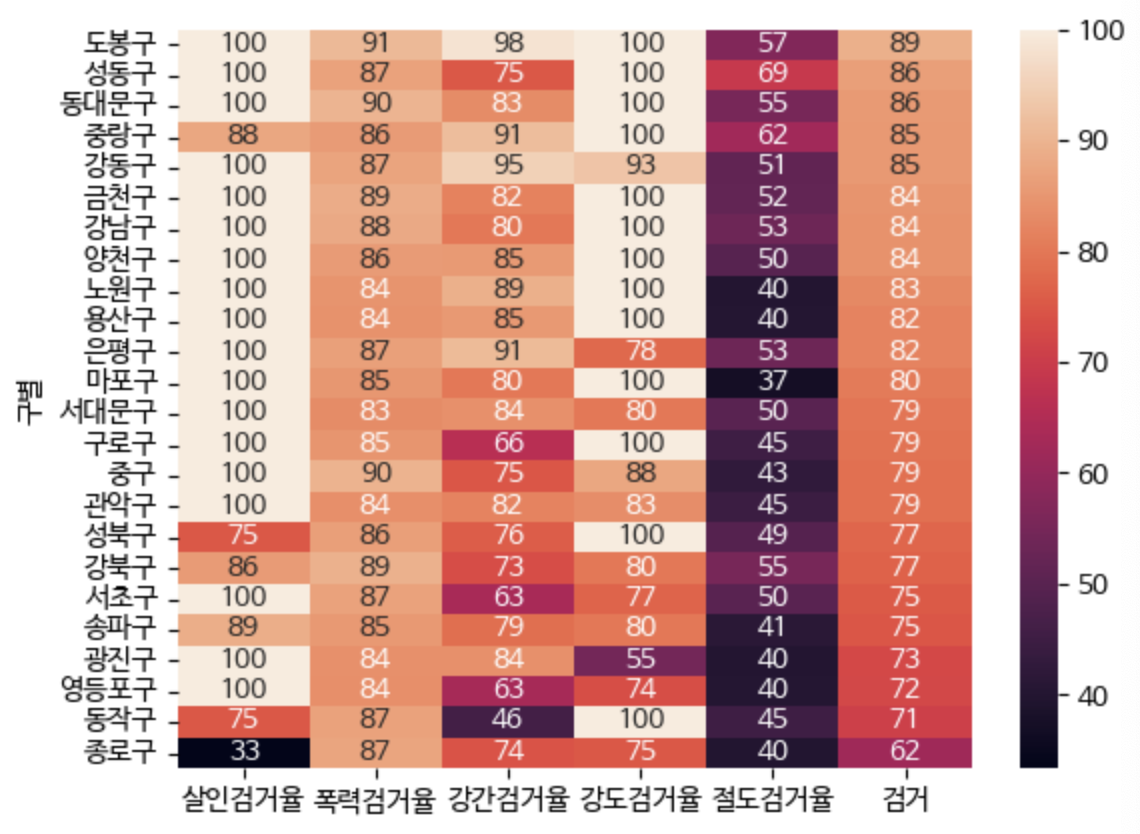
targets = ["살인검거율", "폭력검거율", "강간검거율", "강도검거율", "절도검거율", "검거"]
sorted_data = crime[targets].sort_values("검거", ascending=False)
sns.heatmap(sorted_data, annot=True, fmt=".0f")
Impact