제로베이스 데이터 취업 스쿨 4주차 스터디노트 1호
피벗이 뭔데?
특정 열의 값을 기준으로 삼아 표를 정렬하는 것이다.
명확한 정의가 없어서... 아니 못찾겠어서 나름대로 정의해봤다.
무의식적인 판단
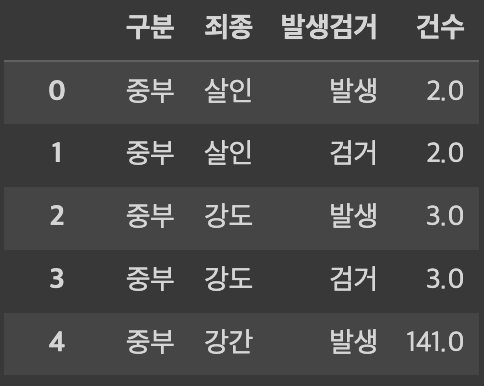
여기서 죄종 항목을 보았을 때,
나는 무의식적으로 분류라고 생각한다.
왜냐면 여러번 반복되고,
값 자체가 연속이 아닌 이산적인 특성을 가지고 있기 때문이다.
그러나 죄종은 분류가 아닌 값이다.
다만, 앞서 언급한 특성을 가지고 있기 때문에 기준값이 되기 적합하다.
느낌, 그리고 해석
피벗을 돌리면서 느꼈던 점은,
어떤 열이든 index로 잡으면 그럴듯한 표가 나오는데,
어떤 열을 column으로 잡으면 가끔 표가 터져버리는 느낌을 받는 것이다.
당연히 그럴 수밖에 없는 것이,
우리는 표를 짤 때,
음... 3000개의 물건에 대한 표를 짠다고 하자.
그러면 당연하게도 개별 물건은 index에 위치하고,
해당 물건들이 가진 특성에 대해서는 column에 놓고 작성한다.
사실 일반적으로 이렇게 되는 이유를 생각해보면
글을 읽는 것도 같지 않나 싶다.
상세한 내용을 보고 싶을 때 우리는 가로로 읽고,
대략적으로 훑고 싶을 때 세로로 본다.
하지만 이건 어디까지나 내 추측이고,
원인은 모르겠지만 현상적으로는 그렇다.
우리는 세로로 긴 표를 보는 것이 익숙하고,
마우스도 세로로 굴리기 좋은 휠이 있다.
결론은 column을 잡을 땐 분류적인 속성의 값을 사용하는 것이 보통 낫다는 것.
그 외 잡기술
argument를 list가 아닌 str로 주면 column의 MultiIndex를 유의미하게 줄일 수 있는 듯 하다.
arranged_1 = raw \
.dropna() \
.pivot_table(
index="구분",
columns=["죄종", "발생검거"],
values=["건수"],
aggfunc=[np.sum])
print(arranged_1.columns)MultiIndex([('sum', '건수', '강간', '검거'),
('sum', '건수', '강간', '발생'),
('sum', '건수', '강도', '검거'),
('sum', '건수', '강도', '발생'),
('sum', '건수', '살인', '검거'),
('sum', '건수', '살인', '발생'),
('sum', '건수', '절도', '검거'),
('sum', '건수', '절도', '발생'),
('sum', '건수', '폭력', '검거'),
('sum', '건수', '폭력', '발생')],
names=[None, None, '죄종', '발생검거'])arranged_2 = raw \
.dropna() \
.pivot_table(
index="구분",
columns=["죄종", "발생검거"],
values="건수",
aggfunc=np.sum)
print(arranged_2.columns)MultiIndex([('강간', '검거'),
('강간', '발생'),
('강도', '검거'),
('강도', '발생'),
('살인', '검거'),
('살인', '발생'),
('절도', '검거'),
('절도', '발생'),
('폭력', '검거'),
('폭력', '발생')],
names=['죄종', '발생검거'])