제로베이스 데이터 취업 스쿨 3주차 스터디노트 3호
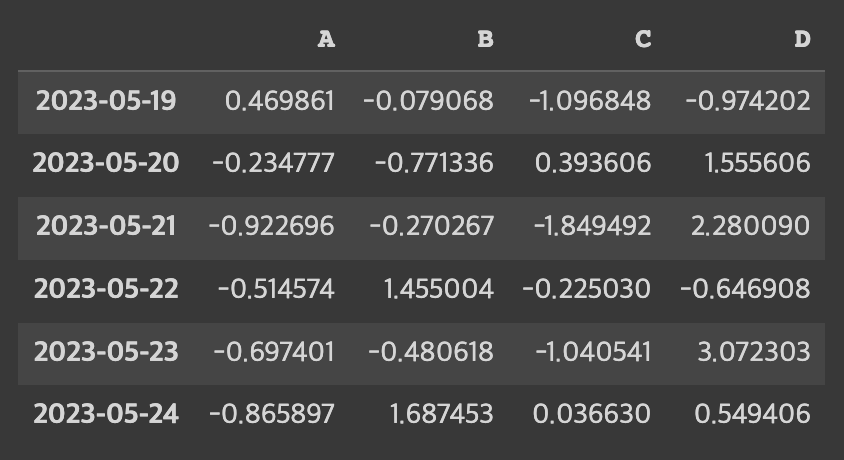
data_frame["A"] # A열
data_frame["A":"C"] # Nope
data_frame[["A":"C"]] # Nope
data_frame[["A", "C"]] # A열, C열
data_frame[1:3] # 1, 2행 (끝 미포함)
data_frame[1] # Nope
data_frame["20230522":"20230524"] # 4, 5, 6행 (끝 포함)
data_frame["20230522"] # Nope일관성이 없는 느낌이다.
흠... 외워야하나?
slice를 쓰면 행 기준인 듯 하고, str이나 list면 열 기준.
가능하면 loc이나 iloc 메소드를 쓰는게 나아보인다.
data_frame.loc[:, ["A", "C"]] # A열, C열
data_frame.loc["20230522"] # 4번째 행
data_frame.iloc[:, [0, 2]] # A열, C열
dafa_frame.iloc[3] # 4번째 행연습문제!
아래 test_frame을 슬라이싱하는 내용들에선 정상 실행되는 것도,
에러가 생기는 것도 있다.
실행되지 않을거라 생각되는 부분을 주석처리하고 돌려보자.
코드가 잘 실행된다면, 당신을 pandas slicing master에 임명하겠다.
import numpy as np
import pandas as pd
rand_data = np.random.randn(6, 4)
date_series = pd.date_range("20230519", periods=6)
test_frame = pd.DataFrame(rand_data, date_series, ["A", "B", "C", "D"])
# test_frame.info()
# test_frame.describe()
test_frame.D
test_frame[["D", "B"]]
test_frame["D":"B"]
test_frame[["D":"B"]]
test_frame[3, ["D", "B"]]
test_frame["20230522", ["D", "B"]]
test_frame[3:4, ["D", "B"]]
test_frame[2:4]
test_frame["20230522":"20230524"]
test_frame["D"]
test_frame[3]
test_frame[3:5]
test_frame.loc["20230522":"20230524", "A":"C"]
test_frame.loc["20230522":"20230524", "C"]
test_frame.loc[["20230522", "20230524"], ["A","C", "D"]]
test_frame.loc["20230522":"20230524", ["A","D"]]
test_frame.loc[["20230522", "20230524"], "A":"C"]
test_frame.loc["20230522"]
test_frame.loc["A"]
test_frame["A"] > 0
test_frame[2:4] > 0
test_frame[2:4, "A"]
test_frame[[2, 3, 5]]
test_frame[2, 3, 5]
test_frame[test_frame["A"] > 0]
test_frame[test_frame > 0]
test_frame.iloc[4]
# disclaimer: 내가 당신을 PSM에 임명한다고 해서 누군가 알아주는 것은 아니다.
# disclaimer 2: 맞는 걸 주석처리하면 정상 실행된다...
# 따라서 다 주석처리해버리면 맞는 문제가 되어버린다(?)
Impact