Imbalance class 를 가진 데이터 성능 개선을 위한 방법론
Reference : sklearn-imbalanced
-
불균형을 해소하여 적은 샘플의 클래스를 가진 데이터가 충분히 학습되게 하면서도, 학습 수가 비교적 충분한 데이터의 성능이 떨어지지 않도록 학습하는 것이 필요하다.
-
아래 소개할 방법론들의 경우, 클래스 간 차이가 이상 탐지 수준이 아닌 경우를 가정한다 (예를 들어, class 비율이 6:2.5:1.5). 이상 탐지의 경우 "이상"을 탐지하기 위해 개수가 적은 샘플을 구분하는 문제에 속하고, 이를 다룰 여러 방법론들이 있기 때문에 여기서는 다루지 않았다.
Over Sampling
부족한 라벨의 데이터 수를 늘려 이를 보완하고자 하는 접근법.
- Random Sampling
- 적은 수의 클래스를 지닌 샘플을 다른 클래스의 샘플 비율만큼 그 수를 늘리도록 함.
- 가장 Naive한 방법. 과적합이 될 우려가 있다.
- imbalance
from imblearn.over_sampling import RandomOverSampler
random_seed=42
# 과소클래스에서 랜덤 샘플링하여 X_sampled를 새로 만든다.
ros = RandomOverSampler(random_state=random_seed)
X_resampled, y_resampled = ros.fit_resample(X, y)SMOTE
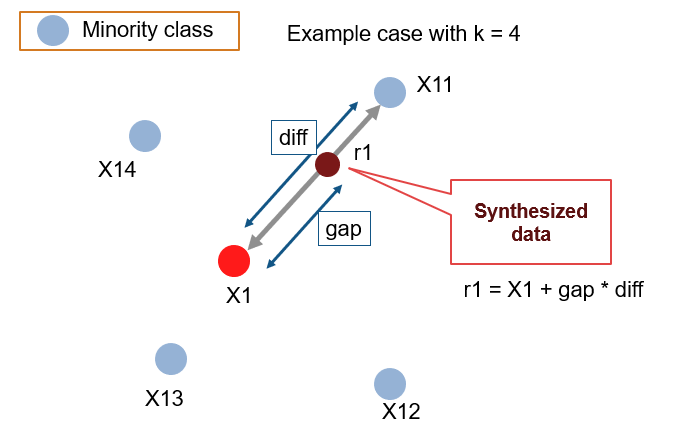
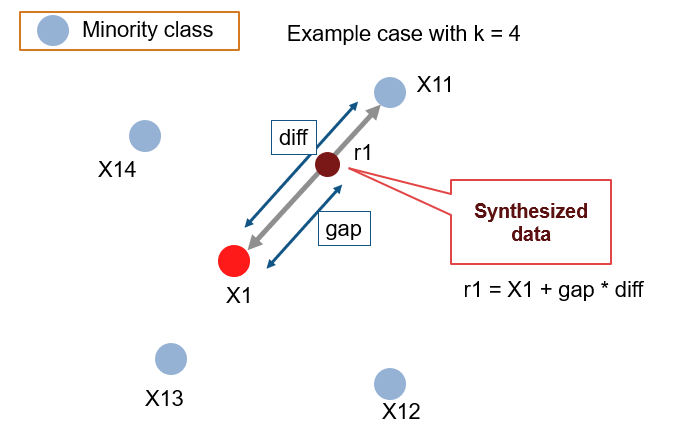
그림 출처 : https://github.com/minoue-xx/Oversampling-Imbalanced-Data
- 무작위로 랜덤선택된 소수 클래스의 데이터 X1를 기준으로, 소수 샘플 X11 ~X 14 를 K개만큼 (여기선 4) 유클리드 거리기반으로 선택한다.
- 이 중, 가장 가까운 샘플하나를 선택(위에선 X11) 하여, 선택된 데이터와 선분을 잇는다. 두 거리에 임의의 가중치를 곱하고 (gap) 원래 샘플의 특성 벡터를 더한다. 이를 통해, 새로운 특성 벡터가 탄생한다. 이렇게, 특성 공간에서 거리가 가깝다는 것은 비슷한 특성을 가지고 있을 수 있으므로 부족한 샘플을 augmentation 하는 효과를 누릴 수있다.
- 이때, X11을 선택하는 기준은 여러가지가 될 수 있고, 이 과정에서 여러 옵션을 선택할 수 있다.
Source code
# imblearn 라이브러리에서는 SMOTE를 지원한다.
from imblearn.over_sampling import SMOTE
def smote(inputs, labels):
""" inputs : B x D , labels : B, """
dimension = inputs.shape[1]
smote = SMOTE(random_state=42)
item_res, labels_res = smote.fit_resample(item, labels)
return item_res, labels_res나의 경우는 K개의 피처를 가진 데이터를 smote로 증강 후, PCA를 통해 2차원으로 축소하고 시각화하였을 때 아래와 같이 나왔다. 다소 선분과 같이 인위적인 모습을 확인할 수 있다.
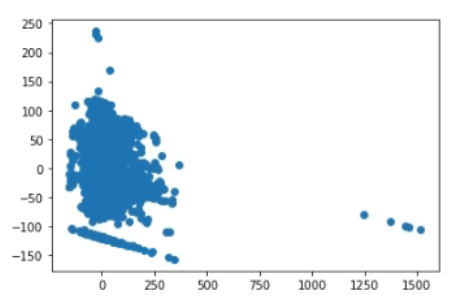
실제로, 그냥 분류학습을 하는 것 보다 분류 성능이 향상되는 것을 관찰할 수 있다. smote의 경우 아래와 같은 옵션들을 취할 수 있는데, 샘플링하는 과정에서 minority한 클래스 레이블을 가진 샘플들을 대상으로 할 것인지, majority한 클래스 레이블을 가진 샘플들을 대상으로 할 것인지에 따라 다르게 선택할 수 있다. 보통, 불균형한 (레이블이 적은 ) 데이터 샘플을 늘리려고 하기 때문에 그 샘플들을 주변 샘플들로 두는 경우가 많고, 이런 이유로 not majority는 비교적 선택되지 않는 편이다. 디폴트는 'auto'로 세팅되어 있다.
'minority': resample only the minority class;
'not minority': resample all classes but the minority class;
'not majority': resample all classes but the majority class;
'all': resample all classes;
'auto': equivalent to 'not majority'.ADASYN
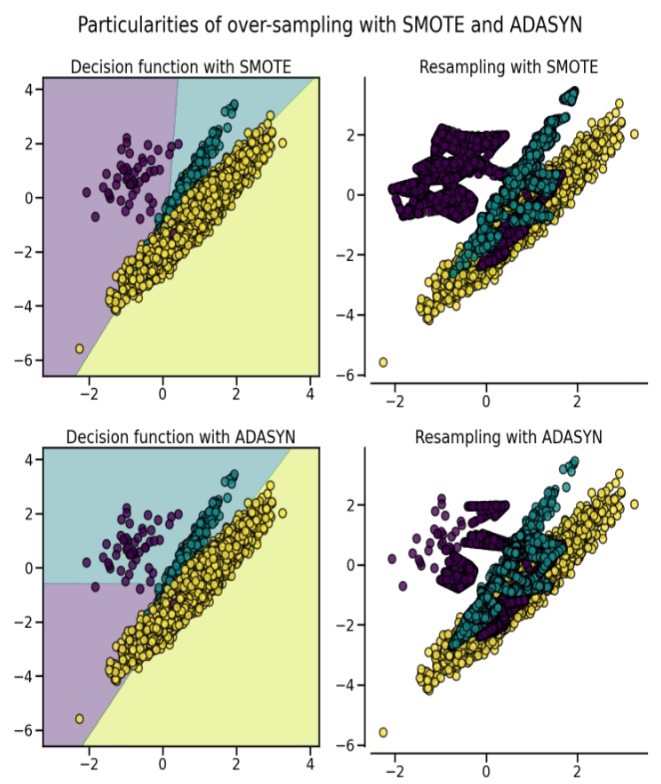
SMOTE랑 큰 형태는 유사하지만 합성 데이터를 만들 때, 다음 아래의 룰을 따른다. 1) 먼저 클래스간 불균형 비율 ((0,1])를 구하고 생성해야하는 minority 클래스의 생성 수()를 구한다. 2) minority 클래스에 속하는 를 기준으로 유클리디언 거리 기반 가장 가까운 개의 이웃들을 찾는다. 3) 각 마다 majority 샘플이 얼마나 존재하는지 을 구한다. 전체 개수들로 나눠 밀도 함수를 만든다. 4) 밀도함수와 를 이용하여 동일하게 minority 샘플들과의 합성 샘플들을 생성한다.
이렇게 만들게 되면, SMOTE의 경우는 합성 데이터를 만들 때마다 일정한 개수를 만들게 되지만 , ADASYN의 경우는 i번 째의 밀도함수 값을 구해서 G를 곱하여 그 개수만큼 만들기 때문에 각 샘플마다 얼마나 주변에 majority한 샘플이 있는가에 따라 만들어지는 개수가 달라지게 된다. [2]
아래 그림을 보면 majority가 포함되어 있는 경계면 일수록 minority 샘플들의 합성 빈도를 늘리는 것을 확인할 수 있다.
Augmentation Methods
-
최근에는 language model들을 이용해서 augmentation하는 방법들이 제안되고 있다. Contrastive learning 방법론의 대두로 positive한 샘플들을 어떻게 만들 것인지, 그리고 그 효과에 대해서도 연구되고 있음으로 보인다.
-
이 방법에 대해선 추후 공부한 부분을 적용하며 더 다루어 보도록 하려고 한다.
-
직접 내 데이터에 적용해보기 전에 아래 가상의 데이터를 생성해보고 smote 피처가 어떻게 임베딩 되는지 확인해볼 수 있다.
from skelarn.datasets import make_classification
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# 임의의 분류 데이터 생성.
X, y = make_classification(n_classes=3, class_sep=3,
weights=[0.65, 0.16, 0.19], n_informative=3, n_redundant=1, flip_y=0,
n_features=1024, n_clusters_per_class=1, n_samples=128, random_state=42)
pca = PCA(n_components=2, n_oversamples=20)
pca_feature = pca.fit_transform(n_features)
plt.scatter(pca_feature[:,0],pca_feature[:,1])참고자료
[1] https://imbalanced-learn.org/stable/over_sampling.html#naive-random-over-sampling
[2] Haibo He, Yang Bai, E. A. Garcia and Shutao Li, "ADASYN: Adaptive synthetic sampling approach for imbalanced learning," 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), 2008, pp. 1322-1328, doi: 10.1109/IJCNN.2008.4633969.
