Contents
- 목표 1 - Sequence to Sequence 구조와 모델 학습 과정 이해.
- 목표 2 - Attention에 대한 이해와 seq2seq 모델 구조에 적용.
- 목표 3 - RNN 기반 한국어 뉴스 데이터세트를 이용하여 요약모델 만들고 성능 평가.
참조 논문 : Effective Approaches to Attention-based Neural Machine Translation
참조한 케라스 코드 : 링크
실습 데이터 : 한국어 문서 요약 텍스트 데이터
- 본 데이터는 DACON의 데이터를 이용한 것으로 위 링크에서 다운로드시 동의가 필요합니다.
순서
- 실습 환경 세팅
- 학습 환경 구축하기.
- 데이터 불러오기.
- 데이터 형태 확인하기.
- 데이터 전처리
- 한글만 추출.
- 데이터 통계.
- 통계를 바탕으로 고정된 시퀀스 길이 정하기.
- 고정 시퀀스 길이 이상의 데이터 제거.
- 학습/검증 데이터셋 분리.
- 단어장 생성.
- 학습 형태로 변형.
- 인코딩.
- Attention-based RNN 모델로 요약 해보기.
- Attention-based RNN 모델 정의.
- 학습 파라미터 정의 및 학습.
- 사전학습된 Word2vec 적용해서 실험해보기.
- 학습된 모델로 요약 생성해보기.
- 히트맵 시각화해보기.
0. 실습 환경 세팅
-
학습 환경 구축하기.
-
데이터 불러오기.
- 데이터 형태 확인하기.
# 선택사항 : 어텐션 시각화에 사용할 Matplotlib 한글 폰트 적용.
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf필요한 라이브러리 설치
형태소 분석기 설치
!pip install konlpyimport re
import json
import pandas as pd
import os
import time
import numpy as np
from tqdm import tqdm
# 시각화
import matplotlib.pyplot as plt
# 형태소 분석기
from konlpy.tag import Okt
# 코랩 환경에서 진행 시, 드라이브 마운트 하여 데이터 경로 지정하기.
from google.colab import drive
drive.mount('/content/drive')
TRAIN_DIR = '/content/drive/MyDrive/raw_data/train.jsonl'
TEST_DIR = '/content/drive/MyDrive/raw_data/extractive_test_v2.jsonl'형태소 분석기 정의
학습 데이터 로드
tokenizer = Okt()
with open(TRAIN_DIR, 'r') as json_file:
json_list = list(json_file)
datas = []
for json_str in json_list:
line = json.loads(json_str)
datas.append(line)
print(datas.head())
print(datas.article_original[0], end="\n")
print(datas.abstractive[0])결과 출력
['당진시 문화관광과를 대상으로 하는 행정사무감사에서 당진시립합창단 관계자가 보낸 것으로 추정되는 문자와 관련해 당진시의회가 행정사무조사특별위원회를 구성해 조사하겠다고 밝혔다.',
'당진시의회 행정사무감사 3일차였던 지난 6일 문화관광과를 대상으로 하는 행감에서 최창용 의원은 “(당진시립합창단 정기연주회를 앞두고) 문자메세지를 제보받았다”며 “(음향팀에 보낸 것으로 추정되는) 해당 문자에는 ‘합창단이 소리를 작게 낼 것이니 알고 있으라’는 내용이었다”고 말했다.',
'이어 “공연에서 소리를 작게 낸다는 것은 합창단으로서 그 임무를 하지 않겠다는 것”이며 “공연 자체를 무력화해 당진시를 망신 주려는 행위”라며 해당 문자를 보낸 단원 등 연루된 사람들을 찾아 사실관계를 확인하고 징계 등 책임을 물어야 한다고 지적했다.',
'문제의 문자메세지를 전달받은 문화관광과는 감사법무담당관에게 조사를 의뢰했다.',
'권경선 문화관광과장은 “누가, 어떻게 해서 해당 문자가 나온 것인지 정확히 조사해봐야 알 수 있다”며 “전달받은 문자 내용도 최 의원이 언급한 부분만 있어, 중간 내용만을 가지고는 전체를 유추할 수 없다”고 전했다.',
'하지만 감사법무담당관실에서 아직 조사가 이뤄지지 않고 있어 당진시가 사태의 심각성을 인지하지 못하고 있다는 지적이다.',
'그동안 행정사무감사가 진행되고 있어 사태를 지켜봤다던 감사법무담당관실에서는 “관계된 사람들을 조사해 사태를 파악해야 하는데, 아직 조사에 대한 뚜렷한 계획이 없다”고 답했다.',
'한편 행감이 끝난 지난 12일 당진시의회에서는 당진시립합창단 문제를 비롯해 구체적인 조사가 필요한 부분에 대해 행정사무조사특별위원회를 구성해 운영하겠다고 밝혔다.',
'김기재 의장은 “본회의 의결과 제적의원 1/3의 발의가 있으면 행정사무조사특별위원회를 구성할 수 있다”며 “다음 달 초 위원들과 상의해 위원회를 구성한다면 당진시립합창단 관련 사안을 비롯해 사회복지기관 위수탁 등에 대해 다룰 계획”이라고 말했다.']
'지난 6일 당진시의회 행정사무감사에서 '합창단이 소리를 작게 낼 것이니 알고 있으라'라는 문자 등으로 불거진 합창단의 의무 불이행 논란에 대해 행정사무조사특별위원회를 구성해 조사를 수행하겠다는 의견을 표명했다.'

데이터 전처리
- 한글만 추출.
- 데이터 통계.
- 통계를 바탕으로 고정된 시퀀스 길이 정하기.
- 고정 시퀀스 길이 이상의 데이터 제거.
- 학습/검증 데이터셋 분리.
- 단어장 생성.
- 학습 형태로 변형.
- 인코딩.
한글을 위한 전처리, 한글만 추출하는 정제과정을 거칩니다.
f = lambda x : ' '.join(x)
datas['article_original'] = datas['article_original'].apply(f)
class HangulExtractor:
def __init__(self):
self.pattern = re.compile('[^ ㄱ-ㅣ가-힣]+')
def __call__(self, sentence):
return self.pattern.sub('', sentence)
he = HangulExtractor()
datas['article_original'] = datas['article_original'].apply(he)
datas['abstractive'] = datas['abstractive'].apply(he)요약 태스크에 대한 간단한 소개.
# article original을 받아 abstractive를 생성해내는 것이 목표.
# 디코더는 아래와 같은 형태가 인코딩 되어 들어 갈 것.
datas['decoder_input'] = datas['abstractive'].apply(lambda x : '[BOS] '+ x)
datas['decoder_target'] = datas['abstractive'].apply(lambda x : x + ' [EOS]')
datas.head()통계를 기준으로 최대 시퀀스 길이를 설정.
text_len = [len(s.split()) for s in datas['article_original']]
summary_len = [len(s.split()) for s in datas['abstractive']]
print('텍스트의 최소 길이 : {}'.format(np.min(text_len)))
print('텍스트의 최대 길이 : {}'.format(np.max(text_len)))
print('텍스트의 평균 길이 : {}'.format(np.mean(text_len)))
print('요약의 최소 길이 : {}'.format(np.min(summary_len)))
print('요약의 최대 길이 : {}'.format(np.max(summary_len)))
print('요약의 평균 길이 : {}'.format(np.mean(summary_len)))
Out
텍스트의 최소 길이 : 85
텍스트의 최대 길이 : 501
텍스트의 평균 길이 : 211.89776417540827
요약의 최소 길이 : 2
요약의 최대 길이 : 97
요약의 평균 길이 : 25.57313739691143고정된 시퀀스길이 설정.
Vocab 생성
- Vocab 형태 확인.
- Vocab 제공.
from collections import Counter
from tqdm.auto import tqdm
import pickle as pkl
def get_vocab(split_dataset):
lines = []
for line in tqdm(split_dataset):
lines.extend(line)
counter = Counter(lines)
voca_freq = dict(counter)
vocab = {'[PAD]': 0,
'[BOS]': 1,
'[EOS]': 2,
'[UNK]': 3}
for word, freq in voca_freq.items():
if freq <= 5:
continue
vocab[word] = len(vocab)
return vocab
# vocab 생성
art_split = []
abs_split = []
for s in tqdm(datas['article_original']):
art_split.append(tokenizer.morphs(s))
for s in tqdm(datas['abstractive']):
abs_split.append(tokenizer.morphs(s))
src_vocab = get_vocab(art_split)
trg_vocab = get_vocab(abs_split)
# vocab 저장
with open('vocab/src_vocab.pkl', 'wb') as fw:
pkl.dump(src_vocab, fw)
with open('vocab/trg_vocab.pkl', 'wb') as fw:
pkl.dump(trg_vocab, fw)
# load the vocabulary
with open('/content/drive/MyDrive/vocab/src_vocab.pkl', 'rb') as fr:
src_vocab = pkl.load(fr)
with open('/content/drive/MyDrive/vocab/trg_vocab.pkl', 'rb') as fr:
trg_vocab = pkl.load(fr)데이터를 모델이 학습할 수 있도록 인코딩하기.
def word2index(split_data, src_vocab, trg_vocab):
srcs=[]
trgs=[]
start_time = time.time()
for src, trg in tqdm(zip(split_data['article_original'], split_data['abstractive']), total=len(split_data['article_original'])):
src_ind = [src_vocab[tok] if tok in src_vocab else src_vocab['[UNK]'] for tok in src]
if len(src_ind) < SRC_MAX_SEQ:
src_ind += [src_vocab['[PAD]']] * (SRC_MAX_SEQ - len(src_ind))
else:
src_ind = src_ind[:SRC_MAX_SEQ]
srcs.append(src_ind)
trg_ind = [trg_vocab['[BOS]']] + [trg_vocab[tok] if tok in trg_vocab else trg_vocab['[UNK]'] for tok in trg] + [trg_vocab['[EOS]']]
if len(trg_ind) < TRG_MAX_SEQ:
trg_ind += [trg_vocab['[PAD]']] * (TRG_MAX_SEQ - len(trg_ind))
else:
trg_ind = trg_ind[:TRG_MAX_SEQ-1] + [trg_vocab['[EOS]']]
trgs.append(trg_ind)
return srcs, trgs데이터 인덱싱하기.
train_srcs, train_trgs = word2index(train_split_data, src_vocab, trg_vocab)
val_srcs, val_trgs = word2index(val_split_data, src_vocab, trg_vocab)인코더에 들어갈 데이터 정의.
디코더에 들어갈 데이터 정의.
SRC_MAX_SEQ = 200
TRG_MAX_SEQ = 50
encoder_input_train = train_srcs[:, :SRC_MAX_SEQ]
encoder_input_val = val_srcs[:, :SRC_MAX_SEQ]
decoder_input_train = train_trgs[:, :TRG_MAX_SEQ-1]
decoder_input_val = val_trgs[:, :TRG_MAX_SEQ-1]
decoder_target_train = train_trgs[:, 1: TRG_MAX_SEQ]
decoder_target_val = val_trgs[:, 1: TRG_MAX_SEQ]
print("ENCODER")
print(" input_train : ", encoder_input_train.shape)
print(" input_val : ", encoder_input_val.shape)
print("\nDECODER")
print(" input_train : ", decoder_input_train.shape)
print(" input_val : ", decoder_input_val.shape)
print(" target_train: ", decoder_target_train.shape)
print(" target_val : ", decoder_target_val.shape)3. Attention-based RNN 모델로 요약해보기.
- 3.1 모델 정의 및 학습
- 3.2 사전학습된 Word2vec 적용해서 실험해보기.
- 3.3 학습된 모델로 요약 생성해보기.
- 3.4 어텐션 레이어 히트맵 시각화해보기.
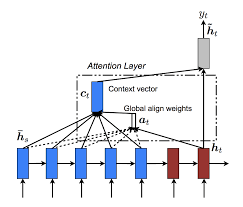
3.1 모델 정의 및 학습
import datetime
import gensim
import numpy as np
from gensim.models.keyedvectors import KeyedVectors
import tensorflow as tf
import tensorflow.keras as keras
from tensorflow.keras.layers import Input, LSTM, Embedding, Dense, Concatenate
from tensorflow.keras.models import Model
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
# 미리 만들어진 어텐션 레이어 가져오기.
import urllib
urllib.request.urlretrieve("https://raw.githubusercontent.com/thushv89/attention_keras/master/src/layers/attention.py",\
filename="attention.py")
from attention import AttentionLayer
# 하이퍼 파라미터 정의
SRC_MAX_SEQ = 200
TRG_MAX_SEQ = 50
EMB_DIM = 200
HIDDEN_SIZE = 256
BATCH_SIZE = 256
EPOCHS = 30
# 모델 정의
# 인코더
encoder_inputs = Input(shape=(SRC_MAX_SEQ, ))
enc_emb = Embedding(len(src_vocab), EMB_DIM)(encoder_inputs)
encoder_lstm1 = LSTM(HIDDEN_SIZE, return_sequences=True, return_state=True ,dropout = 0.4, recurrent_dropout = 0.4)
encoder_output1, state_h1, state_c1 = encoder_lstm1(enc_emb)
encoder_lstm2 = LSTM(HIDDEN_SIZE, return_sequences=True, return_state=True, dropout=0.4, recurrent_dropout=0.4)
encoder_output2, state_h2, state_c2 = encoder_lstm2(encoder_output1)
encoder_lstm3 = LSTM(HIDDEN_SIZE, return_state=True, return_sequences=True, dropout=0.4, recurrent_dropout=0.4)
encoder_outputs, state_h, state_c= encoder_lstm3(encoder_output2)
# 디코더
decoder_inputs = Input(shape=(None,))
dec_emb_layer = Embedding(len(trg_vocab), EMB_DIM)
dec_emb = dec_emb_layer(decoder_inputs)
decoder_lstm = LSTM(HIDDEN_SIZE, return_sequences = True, return_state = True, dropout = 0.4, recurrent_dropout=0.2)
decoder_outputs, _, _ = decoder_lstm(dec_emb, initial_state = [state_h, state_c])
# 어텐션 함수 적용.
attn_layer = AttentionLayer(name='attention_layer')
attn_out, attn_states = attn_layer([encoder_outputs, decoder_outputs])
# 어텐션의 결과와 디코더의 hidden state들을 연결.
decoder_concat_input = Concatenate(axis = -1, name='concat_layer')([decoder_outputs, attn_out])
# 디코더의 출력층.
decoder_softmax_layer = Dense(len(trg_vocab), activation='softmax')
decoder_softmax_outputs = decoder_softmax_layer(decoder_concat_input)
# 모델 호출.
model = Model([encoder_inputs, decoder_inputs], decoder_softmax_outputs)
model.summary()모델 학습
model.compile(optimizer='rmsprop', loss='sparse_categorical_crossentropy')
es_callback = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience = 2)
tb_callback = tf.keras.callbacks.TensorBoard(logdir, update_freq=1)
history = model.fit(x = [encoder_input_train, decoder_input_train],
y = decoder_target_train,
validation_data = ([encoder_input_val, decoder_input_val], decoder_target_val),
batch_size = BATCH_SIZE,
callbacks=[es_callback, tb_callback],
epochs = EPOCHS)
# 텐서보드 이외에도 직접 matplot 라이브러리를 이용해서 확인.
# Early stoping 과정을 직접 그려보기.
# Train loss와 Eval loss의 변화를 확인.
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='val')
plt.legend()
plt.show()
인퍼런스 모델 정의
encoder_model = Model(inputs=encoder_inputs, outputs=[encoder_outputs, state_h, state_c])
decoder_state_input_h = Input(shape=(HIDDEN_SIZE,))
decoder_state_input_c = Input(shape=(HIDDEN_SIZE,))
decoder_inputs = Input(shape=(None,))
dec_emb2 = dec_emb_layer(decoder_inputs)
decoder_outputs2, state_h2, state_c2 = decoder_lstm(dec_emb2, initial_state=[decoder_state_input_h, decoder_state_input_c])
decoder_hidden_state_input = Input(shape=(SRC_MAX_SEQ, HIDDEN_SIZE))
attn_out_inf, attn_states_inf = attn_layer([decoder_hidden_state_input, decoder_outputs2])
decoder_inf_concat = Concatenate(axis=-1, name='concat')([decoder_outputs2, attn_out_inf])
decoder_outputs2 = decoder_softmax_layer(decoder_inf_concat)
decoder_model = Model(
[decoder_inputs] + [decoder_hidden_state_input,decoder_state_input_h, decoder_state_input_c],
[decoder_outputs2] + [state_h2, state_c2] + [attn_states_inf]) 3.3 학습된 모델로 요약 생성
import tensorflow as tf
import tensorflow.keras as keras
# 인덱스를 다시 단어로 되돌릴 때 사용.
src_i2w = {idx : w for w, idx in src_vocab.items()}
trg_i2w = {idx : w for w, idx in trg_vocab.items()}
encoder_model = keras.models.load_model('/content/drive/MyDrive/LG_CNS_week4/rnn_att_rand/enc_model')
decoder_model = keras.models.load_model('/content/drive/MyDrive/LG_CNS_week4/rnn_att_rand/dec_model')
# 생성 함수
# 긴 문장을 받아 요약문장을 생성합니다.
def decode_sequence(input_seq):
e_out, e_h, e_c = encoder_model.predict(input_seq)
target_seq = np.zeros((1,1))
target_seq[0, 0] = trg_vocab['[BOS]']
stop_condition = False
decoded_sentence = ''
attention_weight = [] ###
while not stop_condition: # stop_condition이 True가 될 때까지 루프 반복
output_tokens, h, c, attn_states = decoder_model.predict([target_seq] + [e_out, e_h, e_c]) ###
sampled_token_index = np.argmax(output_tokens[0, -1, :])
sampled_token = trg_i2w[sampled_token_index]
attention_weight.append((sampled_token_index, attn_states)) ###
if(sampled_token!='[EOS]'):
decoded_sentence += ' '+sampled_token
# [EOS] 에 도달하거나 최대 길이를 넘으면 중단.
if (sampled_token == '[EOS]' or len(decoded_sentence.split()) >= (TRG_MAX_SEQ-1)):
stop_condition = True
target_seq = np.zeros((1,1))
target_seq[0, 0] = sampled_token_index
# 상태를 업데이트.
e_h, e_c = h, c
return decoded_sentence, attention_weight
# 인덱스를 텍스트로 바꾸는데 활용합니다.
def seq2text(input_seq):
""" 텍스트 시퀀스로 변환 """
temp=''
for i in input_seq:
if(i!=0):
temp = temp + src_i2w[i]+' '
return temp
def seq2summary(input_seq):
""" 텍스트 시퀀스로 변환 """
temp=''
for i in input_seq:
if((i!=0 and i!=trg_vocab['[BOS]']) and i!=trg_vocab['[EOS]']):
temp = temp + trg_i2w[i] + ' '
return temp3.3.1 정성 평가
for i in range(16, 20):
print("원문 : ",seq2text(encoder_input_val[i]))
print("실제 요약문 :",seq2summary(decoder_input_val[i]))
desen, _ = decode_sequence(encoder_input_val[i].reshape(1, SRC_MAX_SEQ))
print("예측 요약문 :",desen)
print("\n")결과 출력
원문 : 전남도 는 일 수산 자원 보호 및 불법 어업 단속 등 을 위해 총 억원 의 사업 비 를 들여 노후 어업 지 도선 척 을 대체 [UNK] 계획 이라고 밝혔다 어업 지 도선 은 권역 별로 개 가 운영 되고 있다 목포 남항 에 전 남호 와 전 남호 여수 [UNK] 에 전 남호 와 호가 정박 하면서 동서 [UNK] 해역 을 나눠 담당 하고 있다 이 가운데 여 수 고흥 등 동부 권 해역 을 담당 하는 척 의 [UNK] 이 년 과 년 이다 노후 에 따른 잦은 고장 및 철판 부식 섬유 강화 플라스틱 [UNK] 현상 등 이 발생 해 안전 사고 우려 가 높다 또한 척 모두 이하 의 소형 선 으로 기상 악화 시 신속한 현장 대응 에 애로 가 많아 어업 지 도선 대체 건조 가 절실 히 요구 되고 있다 이 에 따라 전남도 는 어업 지 도선 척 의 대체 건조 를 위해 지난 월 기본 및 실시 설계 용역 계약 을 체결 하고 일 설계 용역 착수 보고 회 를 개최 했다 이 날 착수 보고 회 에서는 설계 용역 수행 계획 발표 와 선형 [UNK] 추진기 등 설계 방향 을 설정 하고 과업 지시 서 내용 등 주요 사항
실제 요약문 : 전남도 는 지난 월 기본 및 실시 설계 용역 계약 을 체결 하고 일 설계 용역 착수 보고 회 에서 노후 어업 지 [UNK] 척 을 대체 [UNK] 단속 업무 의 효율 성 을 [UNK] 계획 을 밝혔다
예측 요약문 : 전남도 는 일 부터 일 까지 [UNK][UNK] [UNK][UNK] [UNK] 등 을 대상 으로 논 한 [UNK][UNK] [UNK][UNK] [UNK][UNK] [UNK][UNK] 등 을 비롯 한 개 노선 을 [UNK]
원문 : 서산시 는 지역 에서 생산 된 선인장 이 미국 네덜란드 유럽 아시아 등 으로 연 여 수출 된다고 밝혔다 사진 서산시 제공 서산 서산시 는 지역 에서 생산 된 선인장 이 미국 네덜란드 유럽 아시아 등 으로 연 여 수출 된다고 밝혔다 서산시 에 따르면 [UNK][UNK] 리 김종 돈 씨 가 년 전 부터 전국 선인장 선진 재배 농가 들 을 벤치마킹 하는 등 준비 과정 을 거쳐 생산 한 것 이다 김씨 는 의 하우스 에 양액재배 시설 과 전 기온 풍 난방 다 겹 보온 커튼 알루미늄 스크린 등 을 갖춰 연간 여의 선인장 을 생산 하고 있다 이번 수출물량 은 선인장 약 만주 만 원 상 당 다 경기도 고양시 에 위치 한 수출 대행 업체 로 집결 돼 선적 과 포장 과정 을 거친 후 일 부산 항 에서 선적 약 한 달 뒤 네덜란드 에 도착 예정 이다 양액재배 방식 으로 재배 하기 때문 에 기존 에 토 경 방식 으로 재배 한 선인장 보다 품질 이 우수해 수출 바이어 로부터 좋은 반응 을 얻고 있다고 시 는 설명 했다 올해 연말 까지 여 억 여 원 의 물량 이 수출 될 전망 된다 수출 금액 은 한 주 당 는 원 는 원
실제 요약문 : 충남 서산시 는 [UNK][UNK] 리 [UNK] 돈 씨 등 이 [UNK] 방식 으로 생산 한 우수한 품질 의 지역 [UNK] 이 [UNK] 유럽 아시아 등 으로 여 수출 되어 수출 바이어 로부터 좋은 반응 을 얻고 있다고 밝혔다
예측 요약문 : 서산시 는 일 시청 에서 열린 제 회 전국 개 기업 의 날 을 앞두고 년 간 수출 을 통해 지역 경제 활성화 를 위해 노력 할 것 으로 기대 된다
- 빈도수가 낮은 단어를 UNK로 바로 처리하게 되면, 원문도 훼손될 수 있는 위험이 있다, 하지만 정량 평가에서는 좋은 성능으로 표현된다.
- 정성 평가에서 체리피킹을 통해 일부 자연스러운 문장을 얻을 수 있다. 생성 방식 그리고 현재는 그리디로만 생성하는 방식이기 때문에 반복 생성 빈도가 있다.
3.3.2 정량 평가
- 모델이 생성한 시스템 요약과 사람이 직접 생성한 요약과 n-gram 방식으로 얼마나 겹치는지를 평가.
- ROUGE-N (N-gram) scoring

!pip install rouge
from rouge import Rouge
rouge = Rouge()
hyps=[]
refs=[]
for i in tqdm(range(0, 20)):
hyps.append(seq2summary(decoder_input_val[i]))
dec_sen, _ = decode_sequence(encoder_input_val[i].reshape(1, SRC_MAX_SEQ))
refs.append(dec_sen)
rs_r=[]
rs_p=[]
rs_f=[]
for i in range(20):
scores = rouge.get_scores(hyps[i], refs[i])
rs_r.append(scores[0]['rouge-1']['r'])
rs_p.append(scores[0]['rouge-1']['p'])
rs_f.append(scores[0]['rouge-1']['f'])
print("MEAN ROUGE(Recall) : ", np.mean(rs_r))
print("MEAN ROUGE(Precision) : ", np.mean(rs_p))
print("MEAN ROUGE(F-1) : ", np.mean(rs_f))3.4 어텐션 레이어맵 시각화 해보기.
def word2index_for_raw(src, src_vocab, trg_vocab):
srcs=[]
src_ind = [src_vocab[tok] for tok in src.split()]
if len(src_ind) < SRC_MAX_SEQ:
src_ind += [src_vocab['[PAD]']] * (SRC_MAX_SEQ - len(src_ind))
else:
src_ind = src_ind[:SRC_MAX_SEQ]
srcs.append(src_ind)
return srcs
def plot_attention_weights(encoder_inputs, attention_weights, src_vocab, trg_vocab, filename=None):
"""
Plots attention weights
:param encoder_inputs: Sequence of word ids (list/numpy.ndarray)
:param attention_weights: Sequence of (<word_id_at_decode_step_t>:<attention_weights_at_decode_step_t>)
:param src_vocab: dict
:param trg_vocab: dict
:return:
"""
if len(attention_weights) == 0:
print('Your attention weights was empty. No attention map saved to the disk. ' +
'\nPlease check if the decoder produced a proper translation')
return
mats = []
dec_inputs = []
for dec_ind, attn in attention_weights:
mats.append(attn.reshape(-1))
dec_inputs.append(dec_ind)
attention_mat = np.transpose(np.array(mats))
fig, ax = plt.subplots(figsize=(64, 64))
ax.imshow(attention_mat)
ax.set_xticks(np.arange(attention_mat.shape[1]))
ax.set_yticks(np.arange(attention_mat.shape[0]))
ax.set_xticklabels([trg_vocab[inp] if inp != 0 else "<Res>" for inp in dec_inputs])
ax.set_yticklabels([src_vocab[inp] if inp != 0 else "<Res>" for inp in encoder_inputs.ravel()])
ax.tick_params(labelsize=16)
ax.tick_params(axis='x', labelrotation=90)
def article_inference(article, src_vocab, trg_vocab):
src = word2index_for_raw(article, src_vocab, trg_vocab)
src = np.array(src)
inference, attn_weight = decode_sequence(src)
plot_attention_weights(src, attn_weight, src_i2w, trg_i2w)
test = seq2text(encoder_input_val[-2])
# 시각화
article_inference(test, src_vocab, trg_vocab)
"""
당진 지역 휘발유 평균 가격 은 원 경유 평균 가격 은 원 으로 조사 됐 다년 월 일 기준 지난 월 과 비교 했을 때 각각 원 원 씩 상승 했다 한국 석유 공사 가 운영 하는 오피넷 에 따르면 충남 휘발유 평균 가는 원 경유 평균 가는 원인 것 으로 나타났다 이 가운데 당진 의 휘발유 가격 은 충남 평균 보다 낮고 경유 는 높은 것 으로 조사 됐다 전국 적 으로 봤을 때 지난 월 유류 가가 가장 최저 치를 기록 했으나 이후 상승세 를 보이 며 계속 해서 가격 이 오르고 있다 지난 일 기준 휘발유 가격 이 가장 저렴한 곳 은 토탈 주 당진 주유소 신평 였으며 가격 은 원 이다 이어 행운 주유소 신평 와 면 천 농협 주유 [UNK] 천 가 각각 원 희망 찬 주유소 합덕 철강 주유소 합덕 주행 나면 천 하나 주유소 면 천 와 희망 주유소 합덕 는 원 이었다 반면 휘발유 가격 이 가장 높았던 곳 은 네트웍 스주 송악 주유소 송악 원 이었다 이는 가장 낮은 곳 과 비교 했을 때 원 차이 가 난다 이어 고 대 주유소 고 대가 원 코 [UNK][UNK] 주유소 송악 가 원 행담도 상하 주유소 가 원 으로 높게 나타났다 한편...
"""

- 다음 텍스트에 대해서 모델이 어떤 부분을 중요하게 가중치를 두어 계산하고 있는지 확인할 수 있다.
