Larage Language Model의 가치와 기여를 전달하고 실험에 필요한 방법론을 정리할 예정입니다.
Series1 - PaLM, Google Research, 2022
Summary
- 540 billion의 파라미터를 가진 autoregressive Transformer로 h
igh-quality의 780 billion token들을 학습함. - 무엇보다 본 논문의 제목처럼 “Pathways” 라는 ML 시스템을 이용하여 효율적인 학습을 한 거대한 뉴럴네트워크이며, Tensor Processing Units (TPU) v4 Prods를 사용해서 학습하였고 수천개의 accelerator chips로 학습되었음.
- 수많은 자연어 태스크에서 few-shot 에 state-of-the-art 성능을 보여주었고, 수학적인 reasoning task들에서도 state-of-the-art 성능을 보였다.
Takeaways
- Efficient scaling
- 거대한 언어모델 학습을 시도하면서 기존 GPU 클러스터나 TPU 시스템을 어떻게 다루어서 학습할 것인지도 중요한 문제가 되었다.
- 저자들은 논문에서 기존에는 GPU 클러스터를 이용해서 파이프라인 병렬화 하는 방법을 사용하여 학습하는데, 본 논문에서는 TPU v4 2개만으로 pipeline-free한 방법에 대해서 소개한다.

- Continued improvements from scaling
- 다수의 자연어 태스크 (29개의 benchmarks)들에서 PaLM을 테스트하여 zero-shot, one-shot, few-shot 성능을 확인하였다. 이전 SOTA 모델들 (e.g., GLaM, GPT-3 175B, Megatron-Turing NLG 530B, Gopher, LaMDA, Chinchilla) 과 비교하여 좋은 성능을 보인다.
- 아래는 테이블 일부이며, 이를 통해서 아직 거대 언어모델이 포화 성능이 아님을 밝힌다.
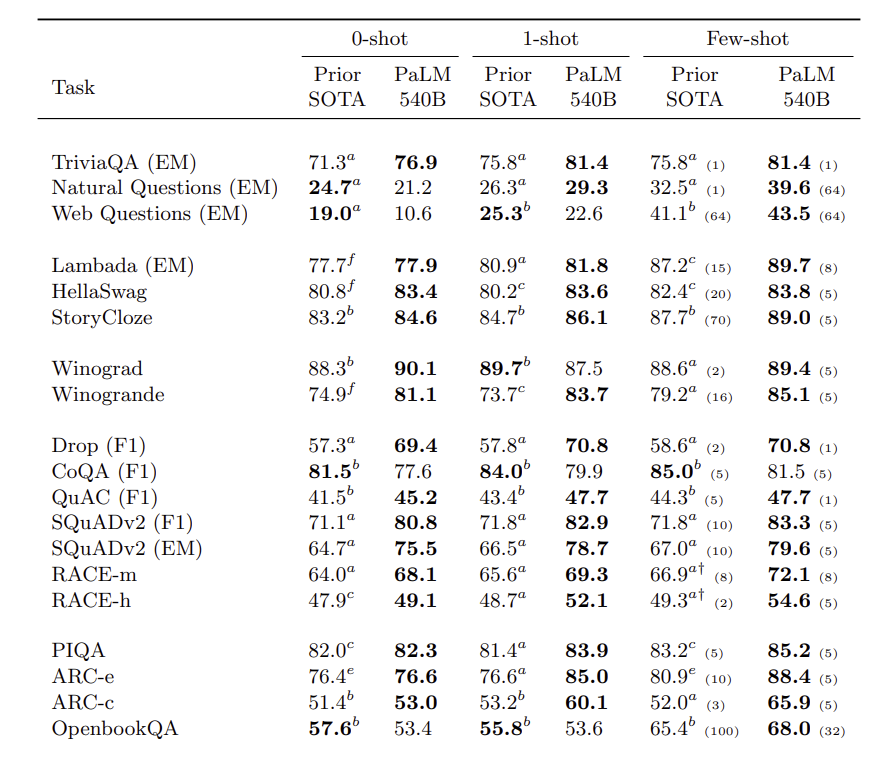
- Breakthrough capabilities
- NLU, NLG 태스크들 어렵다고 판단되는 태스크들에 대해서도 성능 향상을 이룩하였다. 즉, 여러 단계의 스텝을 필요로하는 수학적 계산이나 상식 추론 태스크들과 같은 추론 태스크들에도 좋은 성능을 보인다.
- 특히 chain-of-thought prompting (Wei et al., 2022b) 기법을 이용하여 모델을 스케일링하였을 때, 기존에 전이학습으로 학습하는 것보다 few-shot에서 더 우세한 결과를 보인다.

- Discontinuous improvements
- 모델 학습시, 스케일에 대해 이해하기 위해서 파라미터 개수를 다르게하여 실험하였다.
- 8B, 62B, and 540B. 를 실험하였고, 8B→62B 그리고 62B→540B 스케일을 확장시켜 직접 비교하였다.
- 경험적 법칙으로는 거대 LM의 경우, 불연속적인 성능향상을 보였다는 점이다. 이는, 모델이 특정 스케일에 도달해야 일정 수준의 성능을 낼 수 있다는 것을 의미한다.

- 모델 학습시, 스케일에 대해 이해하기 위해서 파라미터 개수를 다르게하여 실험하였다.
Multilingual understanding
- 이전에는 거대 언어 모델들에 대한 다국어 성능 측정을 일부만 수행하였지만, PaLM은 기계 번역, 요약, 질의 응답에 대해서 수행하였다.
- 특히, 540B PaLM의 경우 non-English data로된 요약 태스크에서도 few-shot 성능은 기존 SOTA와의 차이를 줄이는 역할을 하였다. 덕분에 이후 연구에서는 다국어 데이터로 다국어 성능까지 확인하는 것이 추후 작업으로 남아있다.
Bias and toxicity
- Distributional bias and toxicity에 대한 테스트를 하였다.
- Winogender (Brown et al., 2020) 을 이용하여 multi-choice 하였을 때, 540B의 경우 더 성능이 좋았다.
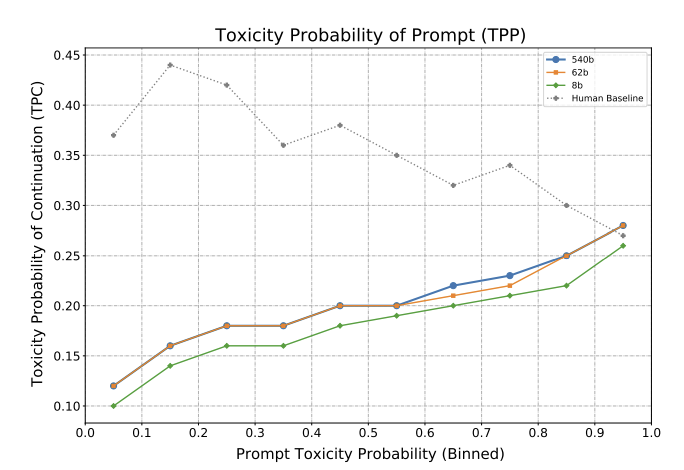
- co-occurence 분석을 통해서 실제로 모델의 크기보다는 학습 데이터세트가 Toxicity에 더 영향을 줄 수 있는 것을 확인한다.
- 다만, 모델의 크기가 커질 수록 prompt에 영향을 받아 편향에 대해서 단정지을 수 있는 위험이 더 높음을 분석한다. 아래 그래프를 보면 사람은 prmpt style에 그다지 큰 영향을 받지 않는 것을 확인할 수 있는 반면에 모델은 크기가 커질수록 점점 더 영향을 받는다.

Seize the day!