[논문 리뷰] Unsupervised Corpus Aware Language Model Pre-training for Dense Passage Retrieval
PaperReview
목록 보기
3/4
Luyu Gao and Jamie Callan
Language Technologies Institute
Carnegie Mellon University
논문 링크 : https://arxiv.org/pdf/2108.05540.pdf
Limiations of Dense retrievers
- fragility to training data noise
- requiring large batches to robustly learn the embedding space
→ coCondenser 제안 : unsupervised corpus-level contrastive loss
Contribution
- Experiments on MS-MARCO, Natural Question, and Trivia QA datasets.
- 무거운 작업들(augmentation, synthesis, filtering, large batch training) 없이도
Concurrent & related work
-
DPR-PAQ (Oguz et al. , 2021)
- Domain 매치를 위한 pre-training을 다시 하는 방식으로 dense retrieveal 쪽 문제 해결.
- Natural Question and Trivia QA 를 사전학습한 모델로 synthetic QA 페어 데이터세트를 생성하여 학습을 한다.
-
Condenser (Gao and Callan, 2021)
- pre-training tasks를 설계함.
- dense retrieval에 효과적인 pre-training task 아이디어를 탐색함.
- pre-training tasks를 설계함.
Brief of Condenser

- Condenser를 그림으로 표현한 것
- HEAD는 따로 정의하여서 통과함.
- CLS는마지막 hidden state에서 사용, 나머지 sequence들은 초기 hidden state를 HEAD 입력값으로 사용.
# https://github.com/luyug/Condenser/blob/main/modeling.py
import os
import warnings
import torch
from torch import nn, Tensor
import torch.distributed as dist
import torch.nn.functional as F
from transformers import BertModel, BertConfig, AutoModel, AutoModelForMaskedLM, AutoConfig, PretrainedConfig, \
RobertaModel
from transformers.models.bert.modeling_bert import BertPooler, BertOnlyMLMHead, BertPreTrainingHeads, BertLayer
from transformers.modeling_outputs import SequenceClassifierOutput, BaseModelOutputWithPooling, MaskedLMOutput
from transformers.models.roberta.modeling_roberta import RobertaLayer
from arguments import DataTrainingArguments, ModelArguments, CoCondenserPreTrainingArguments
from transformers import TrainingArguments
import logging
logger = logging.getLogger(__name__)
- 위 아키텍처의 경우 아래 forward에서 구현을 확인해볼 수 있음.
class CondenserForPretraining(nn.Module):
def __init__(
self,
bert: BertModel,
model_args: ModelArguments,
data_args: DataTrainingArguments,
train_args: TrainingArguments):
super(CondenserForPretraining, self).__init__()
self.lm = bert
# Transformer block 구성.
self.c_head = nn.ModuleList(
[BertLayer(bert.config) for _ in range(model_args.n_head_layers)]
)
self.c_head.apply(self.lm._init_weights)
self.cross_entropy = nn.CrossEntropyLoss()
self.model_args = model_args
self.train_args = train_args
self.data_args = data_args
**def forward(self, model_input, labels):
attention_mask = self.lm.get_extended_attention_mask(
model_input['attention_mask'],
model_input['attention_mask'].shape,
model_input['attention_mask'].device
)
lm_out: MaskedLMOutput = self.lm(
**model_input,
labels=labels,
output_hidden_states=True,
return_dict=True
)
# 마지막 hiddenstate B,S,H
cls_hiddens = lm_out.hidden_states[-1][:, :1]
# 필요한 layer에서만 hidden state를 가져옴.
skip_hiddens = lm_out.hidden_states[self.model_args.skip_from]
# late + early
hiddens = torch.cat([cls_hiddens, skip_hiddens[:, 1:]], dim=1)
# Technique으로 보임.
for layer in self.c_head:
layer_out = layer(
hiddens,
attention_mask,
)
hiddens = layer_out[0]
loss = self.mlm_loss(hiddens, labels)
if self.model_args.late_mlm:
loss += lm_out.loss
return loss**
def mlm_loss(self, hiddens, labels):
# masked language modeling loss : 정답 레이블- 손상된 idx
pred_scores = self.lm.cls(hiddens)
masked_lm_loss = self.cross_entropy(
pred_scores.view(-1, self.lm.config.vocab_size),
labels.view(-1)
)
return masked_lm_loss
# Here
@classmethod
def from_pretrained(
cls, model_args: ModelArguments, data_args: DataTrainingArguments, train_args: TrainingArguments,
*args, **kwargs
):
hf_model = AutoModelForMaskedLM.from_pretrained(*args, **kwargs)
model = cls(hf_model, model_args, data_args, train_args)
path = args[0]
if os.path.exists(os.path.join(path, 'model.pt')):
logger.info('loading extra weights from local files')
model_dict = torch.load(os.path.join(path, 'model.pt'), map_location="cpu")
load_result = model.load_state_dict(model_dict, strict=False)
return model
@classmethod
def from_config(
cls,
config: PretrainedConfig,
model_args: ModelArguments,
data_args: DataTrainingArguments,
train_args: TrainingArguments,
):
hf_model = AutoModelForMaskedLM.from_config(config)
model = cls(hf_model, model_args, data_args, train_args)
return model
def save_pretrained(self, output_dir: str):
self.lm.save_pretrained(output_dir)
model_dict = self.state_dict()
hf_weight_keys = [k for k in model_dict.keys() if k.startswith('lm')]
warnings.warn(f'omiting {len(hf_weight_keys)} transformer weights')
for k in hf_weight_keys:
model_dict.pop(k)
torch.save(model_dict, os.path.join(output_dir, 'model.pt')if model_args.model_type not in CONDENSER_TYPE_MAP:
raise NotImplementedError(f'Condenser for {model_args.model_type} LM is not implemented')
_condenser_cls = CONDENSER_TYPE_MAP[model_args.model_type]
if model_args.model_name_or_path:
model = _condenser_cls.from_pretrained(
model_args, data_args, training_args,
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
)
else:
logger.warning('Training from scratch.')
model = _condenser_cls.from_config(
config, model_args, data_args, training_args))
torch.save([self.data_args, self.model_args, self.train_args], os.path.join아래 목적함수의# Main code
#...
from arguments import DataTrainingArguments, ModelArguments, \
CondenserPreTrainingArguments as TrainingArguments
from modeling import CondenserForPretraining, RobertaCondenserForPretraining
#...
CONDENSER_TYPE_MAP = {
'bert': CondenserForPretraining,
'roberta': RobertaCondenserForPretraining,
}
if __name__ == "__main__":
_condenser_cls = CONDENSER_TYPE_MAP[model_args.model_type]
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
_condenser_cls = CONDENSER_TYPE_MAP[model_args.model_type]
if model_args.model_name_or_path:
model = _condenser_cls.from_pretrained(
model_args, data_args, training_args,
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
)
else:
logger.warning('Training from scratch.')
model = _condenser_cls.from_config(
config, model_args, data_args, training_args)coCodenser
- 저자들은 앞선 Condenser의 경우, corpora를 다시 학습함으로써 보다 universal한 모델을 만들기 위해 노력하지만, 여전히 embedding space의 issue를 해결하는 것은 아니라고 한다.
- MLM loss + Contrastive loss 함께 학습 제안.
- 이렇게 되면, n개의 random한 document를 가져와서 각 pair of spans을 추출한다. 아
- 아래 목적함수는 Noise contrastive estimation을 기억하는 사람들에게는 익숙한 형태이다.
- 분산가설에 의해, 같은 Document에서 나온 spans 페어는 비슷해야하고, 다른 문서에서 가져온 spans들의 경우는 다르다고 가정한다.
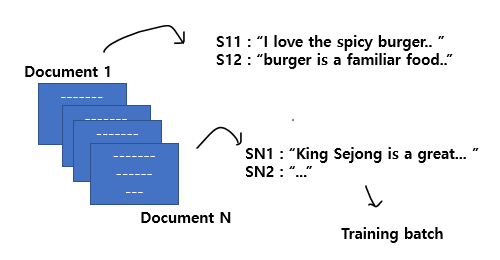
- 이런 가정 아래, 배치마다 랜덤으로 페어를 구성하여 N 문서에서 나온 (1 or 2) 의 모든 내적의 exp 합의 현재 페어의 내적 exp 에다가 음의로그를 붙여 값을 구한다 (음의 로그 확률).

class CoCondenserForPretraining(CondenserForPretraining):
def __init__(
self,
bert: BertModel,
model_args: ModelArguments,
data_args: DataTrainingArguments,
train_args: CoCondenserPreTrainingArguments
):
super(CoCondenserForPretraining, self).__init__(bert, model_args, data_args, train_args)
effective_bsz = train_args.per_device_train_batch_size * self._world_size() * 2
target = torch.arange(effective_bsz, dtype=torch.long).view(-1, 2).flip([1]).flatten().contiguous()
self.register_buffer(
'co_target', target
)
def _gather_tensor(self, t: Tensor):
all_tensors = [torch.empty_like(t) for _ in range(dist.get_world_size())]
dist.all_gather(all_tensors, t)
all_tensors[self.train_args.local_rank] = t
return all_tensors
def gather_tensors(self, *tt: Tensor):
tt = [torch.cat(self._gather_tensor(t)) for t in tt]
return tt
def forward(self, model_input, labels, grad_cache: \
Tensor = None, chunk_offset: int = None):
attention_mask = self.lm.get_extended_attention_mask(
model_input['attention_mask'],
model_input['attention_mask'].shape,
model_input['attention_mask'].device
)
lm_out: MaskedLMOutput = self.lm(
**model_input,
labels=labels,
output_hidden_states=True,
return_dict=True
)
cls_hiddens = lm_out.hidden_states[-1][:, :1]
if self.train_args.local_rank > -1 and grad_cache is None:
co_cls_hiddens = self.gather_tensors(cls_hiddens.squeeze().contiguous())[0]
else:
co_cls_hiddens = cls_hiddens.squeeze()
skip_hiddens = lm_out.hidden_states[self.model_args.skip_from]
hiddens = torch.cat([cls_hiddens, skip_hiddens[:, 1:]], dim=1)
for layer in self.c_head:
layer_out = layer(
hiddens,
attention_mask,
)
hiddens = layer_out[0]
loss = self.mlm_loss(hiddens, labels)
###################
### Contrastive loss
##################################
if self.model_args.late_mlm:
loss += lm_out.loss
if grad_cache is None:
co_loss = self.compute_contrastive_loss(co_cls_hiddens)
return loss + co_loss
else:
loss = loss * (float(hiddens.size(0)) / self.train_args.per_device_train_batch_size)
cached_grads = grad_cache[chunk_offset: chunk_offset + co_cls_hiddens.size(0)]
surrogate = torch.dot(cached_grads.flatten(), co_cls_hiddens.flatten())
return loss, surrogate
@staticmethod
def _world_size():
if dist.is_initialized():
return dist.get_world_size()
else:
return 1
def compute_contrastive_loss(self, co_cls_hiddens):
**similarities = torch.matmul(co_cls_hiddens, co_cls_hiddens.transpose(0, 1))
similarities.fill_diagonal_(float('-inf')) #ij != kl
co_loss = F.cross_entropy(similarities, self.co_target) * self._world_size()**
return co_loss최종적으로 아래 목적함수로 학습함.

- 배치별 loss는 다음과 같이 average sum으로 표현됨.
이외에 저자들은 효율적으로 pre-training을 위해서 gradient caching 방법 또한 제안한다 (여기선 다루지 않는다.)
Experiments
Process
1) Pre-training → 2) Dense Passage Retrieval
1)에서 사용한 dataset
Wikipedia or MS-MARCO web collection
2)에서 사용한 dataset
MS-MARCO , Natural Question, Trivia QA
Results

- MS-MARCO Dev, Natural Question Test, Trivia QA Testset을 기준으로, 전통적인 알고리즘인 BM25과 비교해서 성능이 좋고, Cocurrent 및 related work인 Condenser & DPR-PAQ와 비교해서도 성능 우위를 보인다.

- 적은 배치 사이즈로 학습했음에도, MS-MARCO 검증세트에서 필적 or 더 나은 성능을 보임을 주장. Document 학습을 위해서 Large size 배치만 사용했을 때의 문제를 해결해볼 수 있는 접근을 제시함.
Conclusion
- coCondenser 후 fine-tuning 시, dense retrieval 성능의 큰 향상을 보여줌.
- Wikipedia or MS-MARCO 데이터로 coCondenser 학습 시, dense retrieval QA들에 좋은 성능을 보여주어, 기존 더 여러번 학습해야하거나 semi-supervsied pre-training 했던 모델들과 필적하는 성능을 보여줌.
- 특히, 복잡한 pre-training 설계 방법 없이도 실험할 수 있고, 제한된 배치로도 좋은 성능을 보여주었기에 실용적임.
의견 : coCondenser의 아이디어는 특별하지 않지만, 비교적 간단하기에 document 단위의 passage embedding 실험에 도움이 될 것으로 보인다.

Seize the day!