문제
곡괭이와 광물이 주어질 때 최소한의 피로도를 사용하여 캘 때 피로도 값을 구해라.
(단, 광물은 주어진 순서대로 캐야한다.)
곡괭이 종류 (3종) : 다이아, 철, 돌
광물 종류 (3종) : 다이아, 철, 돌
ex)
# [다이아곡괭이 개수, 철곡괭이 개수, 돌곡괭이 개수]
picks = [1, 3, 2]
# 광물 리스트
minerals = [
"diamond",
"diamond",
"diamond",
"iron",
"iron",
"diamond",
"iron",
"stone"
]곡괭이별 광물을 캤을 때 피로도 소모는 다음과 같다.
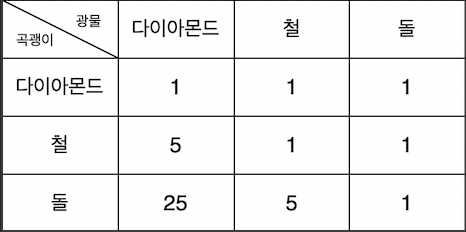
풀이
"좋은 광물일 수록 좋은 곡괭이로 캐주면 되지 않을까?" 라는 생각을 했고 정렬을 하려 했더니 광물을 주어진 순서대로 캐야한다는 것이다.
그래서 일단 방향을 틀고 완전탐색을 해보았지만 역시나 시간초과였다.
다시 돌아와 그리디를 적용할 수 있도록 5개씩 정렬해보자.
내가 캘 수 있는 광물 수 안에서 앞에서 부터 5개씩 그룹화 하여 정렬을 하는 것은 곡괭이별로 5개씩 캘 수 있기 때문에 주어진 순서대로 캘 수 있다.
먼저 5개씩 그룹화 하는 코드를 짜보자.
# i) 곡괭이보다 광석이 많을 때
# ii) 광석보다 곡괭이가 많을 때
ableDigAmount = min(sum(picks) * 5, len(minerals))
diaCnt, ironCnt, stoneCnt = 0, 0, 0
for i in range(ableDigAmount):
if minerals[i] == 'diamond':
diaCnt += 1
elif minerals[i] == 'iron':
ironCnt += 1
elif minerals[i] == 'stone':
stoneCnt += 1
# 5개씩 튜플로 만들어 리스트에 추가
# 5단위로 끊기지 않으면 마지막 그룹은 i = ableDigAmout - 1일 때 에 튜플로 추가
if (i + 1) % 5 == 0 or i == ableDigAmount - 1:
mineralSort.append((diaCnt, ironCnt, stoneCnt))
diaCnt, ironCnt, stoneCnt = 0, 0, 0이제 5개씩 묶인 각 그룹을 좋은 광물을 많이 포함한 그룹일수록 앞으로 오도록 정렬시키면 된다.
정렬을 시키고 나서는 좋은 곡괭이부터 각 그룹에 할당해주면 된다.
# 좋은 광물이 많을 수록 앞에 위치하도록 정렬
mineralSort.sort(key = lambda x : (x[0], x[1], x[2]), reverse = True)
# 좋은 곡괭이를 먼저 사용
i = 0
for diaCnt, ironCnt, stoneCnt in mineralSort:
# 해당 등급 곡괭이가 없으면 다음등급 곡괭이
while picks[i] == 0:
i += 1
# 피로도 계산
if i == 0:
answer += (diaCnt + ironCnt + stoneCnt)
elif i == 1:
answer += (diaCnt * 5 + ironCnt + stoneCnt)
elif i == 2:
answer += (diaCnt * 25 + ironCnt * 5 + stoneCnt)
# 곡괭이를 사용했으니 파괴
picks[i] -= 1처음에는 while부분을 for문으로 작성해서 계속 테스트 3번이 틀렸었다.
# i등급의 곡괭이가 있을 때까지 찾아야 함
while picks[i] == 0:
i += 1 # i등급의 곡괭이가 연속해서 없을 때 오류발생
if picks[i] == 0:
i += 1그렇다면 이렇게 좋은 곡괭이로 좋은 광물을 캐는 방법으로 풀 수 있는 이유는 무엇일까?
힌트는 곡괭이별 5개씩 / 피로도 차이도 5배씩 이다.
철곡괭이로 (0, 1, 0) 과 (0, 0, 5)를 캤을 때 각 그룹별 피로도 소모는 같다.
각 원소별로 우선순위를 두어 정렬을 하여 푸는 그리디 방법을 쓸 수 있는 것이다.
전체코드
def solution(picks, minerals):
answer = 0
mineralSort = []
# i) 곡괭이보다 광석이 많을 때
# ii) 광석보다 곡괭이가 많을 때
ableDigAmount = min(sum(picks) * 5, len(minerals))
diaCnt, ironCnt, stoneCnt = 0, 0, 0
for i in range(ableDigAmount):
if minerals[i] == 'diamond':
diaCnt += 1
elif minerals[i] == 'iron':
ironCnt += 1
elif minerals[i] == 'stone':
stoneCnt += 1
# 5개씩 튜플로 만들어 리스트에 추가
# 5단위로 끊기지 않으면 마지막 그룹은 i = ableDigAmout - 1일 때 에 튜플로 추가
if (i + 1) % 5 == 0 or i == ableDigAmount - 1:
mineralSort.append((diaCnt, ironCnt, stoneCnt))
diaCnt, ironCnt, stoneCnt = 0, 0, 0
# 좋은 광물이 많을 수록 앞에 위치하도록 정렬
mineralSort.sort(key = lambda x : (x[0], x[1], x[2]), reverse = True)
# 좋은 곡괭이를 먼저 사용
i = 0
for diaCnt, ironCnt, stoneCnt in mineralSort:
# 해당 등급 곡괭이가 없으면 다음등급 곡괭이
while picks[i] == 0:
i += 1
# 피로도 계산
if i == 0:
answer += (diaCnt + ironCnt + stoneCnt)
elif i == 1:
answer += (diaCnt * 5 + ironCnt + stoneCnt)
elif i == 2:
answer += (diaCnt * 25 + ironCnt * 5 + stoneCnt)
# 곡괭이를 사용했으니 파괴
picks[i] -= 1
return answer
ubin