Naming
멀티 프로세스로 작업하면 각 프로세스를 구분할 수 있어야 한다. 이때 PID를 통해 구분할 수 있지만 이는 운영체제를 통해 랜덤으로 부여되기 때문에 사용하기가 어렵다.
이에 프로세스의 name 파라미터를 줘서 프로그래머가 각각의 프로세스를 구분할 수 있는 값을 매길 수 있다.
메인 프로세스 & 서브 프로세스
라이브러리
from multiprocessing import Process, current_process
import os
import random
import time메인 프로세스
if __name__ == "__main__":
# 부모 프로세스 아이디
parent_process_id = os.getpid()
# 출력
print(f"Parent process ID {parent_process_id}")
# 프로세스 리스트 선언
processes = list()
# 프로세스 생성 및 실행
for i in range(1, 10): # 1 ~ 100 적절히 조절
# 생성
t = Process(name=str(i), target=square, args=(i,))
# 배열에 담기
processes.append(t)
# 시작
t.start()
# Join
for process in processes:
process.join()
# 종료
print("Main-Processing Done!")서브 프로세스
# 실행 방법
def square(n):
# 랜덤 sleep
time.sleep(random.randint(1, 3))
process_id = os.getpid()
process_name = current_process().name
# 제곱
result = n * n
# 정보 출력
print(f"Process ID: {process_id}, Process Name: {process_name}")
print(f"Result of {n} square : {result}")실행 결과
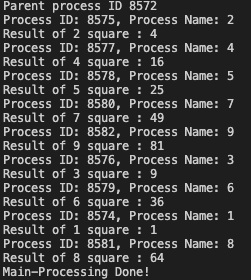
결과를 보면 Process Name에 각 숫자값이 매핑된 것을 확인할 수 있다. 이때 프로세스 생성 갯수를 10개에서 100개로 늘린 후 CPU 사용량을 확인해보면 다음과 같다.
# 프로세스 생성 개수 수정
for i in range(1, 100): # 1 ~ 100 적절히 조절
# 생성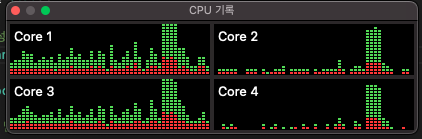
내 맥북의 CPU Core는 총 4개다. 이때 100개의 프로세스가 각각의 코어에 배치되서 실행되는데 코드가 실행된 순간의 CPU 사용량이 급격하게 증가한 것을 볼 수 있다.
이것은 분산 시스템에서 중요한 부분인데 갑자기 많은 양의 프로세스나 스레드가 실행되면 컴퓨터 자원을 잡아먹어서 다른 작업에 필요한, 예를 들어 영상처리나 웹 서버에서 문제가 발생한다.
따라서 모니터링은 다음과 같이 지표(그래프)가 갑자기 변하는 부분을 잘 캐치해서 원인을 파악해야 한다.
ProcessPoolExecutor
프로세스도 스레드와 같이 PoolExecutor가 존재한다. 이를 통해서 쉽게 멀티 프로세스를 구현할 수 있다. 이번 실습에서는 멀티 프로세스를 통해 여러 웹사이트에 접속해서 사이트 페이지의 데이터 길이를 구해본다.
메인 프로세스 & 서브 프로세스
라이브러리 & 상수
from concurrent.futures import ProcessPoolExecutor, as_completed
import urllib.request
import ssl
# 조회 URLS
URLS = ['http://www.daum.net/',
'http://www.cnn.com/',
'http://naver.com/',
'http://www.bbc.co.uk/',
'http://google.com/']메인 프로세스
def main():
# 프로세스풀 Context 영역
with ProcessPoolExecutor(max_workers=5) as executor:
# Future 로드(실행X)
future_to_url = {executor.submit(load_url, url, 60): url for url in URLS}
# 중간 확인(Dict)
# print(future_to_url)
# 실행
for future in as_completed(future_to_url): # timeout=1(테스트 추천)
# Key값이 Future 객체
url = future_to_url[future]
try:
# 결과
data = future.result()
except Exception as exc:
# 예외 처리
print('%r generated an exception: %s' % (url, exc))
else:
# 결과 확인
print('%r page is %d bytes' % (url, len(data)))
# 메인 시작
if __name__ == '__main__':
main()서브 프로세스
# 실행 함수
def load_url(url, timeout):
# Https 접근을 위한 ssl 설정
context = ssl._create_unverified_context()
with urllib.request.urlopen(url, timeout=timeout, context= context) as conn:
return conn.read()실행 결과


백엔드 개발자