들어가며
참고 자료
Github : 2021 SWBank Repo
Notion : 2021 SWBank 요구사항 분석 및 설계
4학년 1학기 프로젝트 청년 주택 알리미가 끝나고 이번에는 대외 활동, 공모전에 나가기 위해 알아보고 있었다.
졸업하시고 구미에서 IT 벤처 기업에 근무하고 있는 선배한테 어떤 공모전을 했나 여쭤보고 내 고민을 말씀드리니 "올해 경북에서 SW Bank라고 기업이랑 학생들이 팀 맺고 프로젝트를 진행하는 공모전이 있는데 같이 나가볼래?" 라고 권해주셨다.
너무 좋은 기회였기 때문에 나는 동아리 후배들 2명을 더 섭외해서 선배, 나, 후배 2명인 총 4인팀을 꾸려 공모전에 나가기로 했다.
ch.0 주제 선정 및 역할 배정
역할 배정
공모전 참가 신청하기 전에 역할 배정을 해야했다. 우선 선배는 멘토 역할로 프로젝트 진행할 때 생기는 기술적인 문제를 해결할 수 있도록 옆에서 도와주시는 포지션이다.
후배들은 2학년으로 제대로 된 프로젝트 경험이 없기 때문에 많이 고민했고 App 부분을 두 명이서 맡는 걸로 했다.
마지막으로 나는 PM 겸 서버 개발자로 공모전에 참가하기로 했다. 생애 첫 PM이였기 때문에 매우 긴장됐지만 설레기도 했다.

주제 선정
다음으로는 어떤 어플리케이션을 만드냐, 주제 선정을 해야했다. 마침 선배 회사에서 진행하고 있던 프로젝트 중 하나를 제안 받았고 그걸로 공모전에 나가기로 했다.
주제 명은 "의료기기 표준코드 UDI(Unique Device Identification)
바코드 데이터 식별 처리를 위한 모바일 어플리케이션" 이다.
현재 정부에서 의료기기 표준코드 를 단계적으로 의무화 시키고 있는 상황이다. 현재 2019년 7월 1일부터 4등급 의료기기를 시작으로 순차적으로 의무화 실시하였으며 2020년 7월 1일부터는 3등급, 2022년 7월 1일까지 모든 등급의 의료기기 들이 이 UDI 바코드를 부착해야 한다.
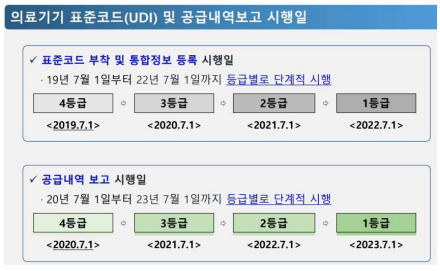
그러나 UDI 바코드를 인식하기 위한 리더기는 그 값이 매우 비싸며 유선 장치이기 때문에 장소에 의존적이다.
따라서 우리 팀은 UDI 바코드 인식 어플리케이션을 개발하여 저렴하고 장소에 구애받지 않는 UDI 바코드 인식 솔루션을 제공하고자 했다.
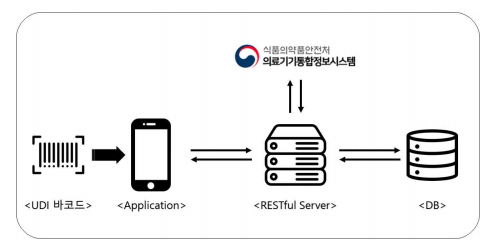
어플리케이션 목표 구조도
따라서 우리는 어플리케이션과 서버를 구축하여 다음과 같은 구조를 가진 어플리케이션을 목표로 했다.
ch.1 요구사항 분석 및 프로젝트 설계
개발론 선정
이번 프로젝트에서는 애자일 개발 방식을 사용하기로 했다. 후배 2명이 프로젝트 경험이 없고 앱이나 서버 개발 경험도 없기 때문에 적절한 스터디로 병행되어야 하고 명확한 요구사항이 정의되어 있지 않기 때문에 프로젝트를 유연하게 진행할 수 있는 애자일이 적절한 듯 했다.
애자일 개발 방법론은 계획을 통해서 주도해 나갔던 과거의 방법론과는 다르게 앞을 예측하며 개발을 하지 않고, 일정한 주기를 가지고 끊임없이 프로토 타입을 만들어내며 그때 그때 필요한 요구를 더하고 수정하여 하나의 커다란 소프트웨어를 개발해 나가는 adaptive style이다.
액터 식별 및 기능 추출
우선 우리가 사용할 프로그램의 액터를 식별해야했다. 여기서 액터는 프로그램 실 사용자를 나타내며 여기서 정의한 액터에 맞게 기능과 UI를 정의하기로 했다.
우리는 액터를 크게 3개의 타입으로 아래와 같으며 각각 m_type으로 구분할 수 있습니다.
| 이름 | 설명 | m_type |
|---|---|---|
| 입출고 담당자 | 입출고 담당자는 의료품의 입출고를 담당하는 사람으로 프로그램의 핵심 사용자이다. | 0 |
| 시스템 관리자 | 시스템 관리자는 의료품 입출고 및 재고 관리 전체 책임자 및 프로그램 마스터 관리자이다. | 1 |
다음으론 기능을 식별했다. 우리 서비스의 핵심 기능은 UDI 바코드 인식이기 때문에 기능 구현에 우선순위를 둬서 이와 직접적인 연관이 있는 기능은 상, 의료품 관리 부분은 중, 그 외 편의 관련 내용은 하로 정의했다.
| 기능 번호 | 우선 순위 | 기능 상세 |
|---|---|---|
| FL-01 | 상 | 스마트폰으로 촬영한 UDI 바코드를 인식한다. |
| FL-02 | 상 | 인식한 바코드 데이터를 바탕으로 정보를 조회할 수 있다. |
| FL-03 | 상 | 해당 의약품의 개수를 관리할 수 있다. |
| FL-04 | 중 | 해당 의약품의 이동 경로와 날짜를 알 수 있다. |
| FL-05 | 중 | 해당 의약품을 다시 사용할 수 없도록 폐기 처리한다. |
| FL-06 | 하 | 한번에 여러 장 사진을 찍어 두고 한번에 확인한다. |
| FL-07 | 하 | 바코드 과정을 거치며 작업을 처리한 사람의 정보를 표시한다. |
UI 설계
위에서 식별한 기능에 맞게 UI를 구현했다. 사용 툴은 Adobe XD를 사용했다.
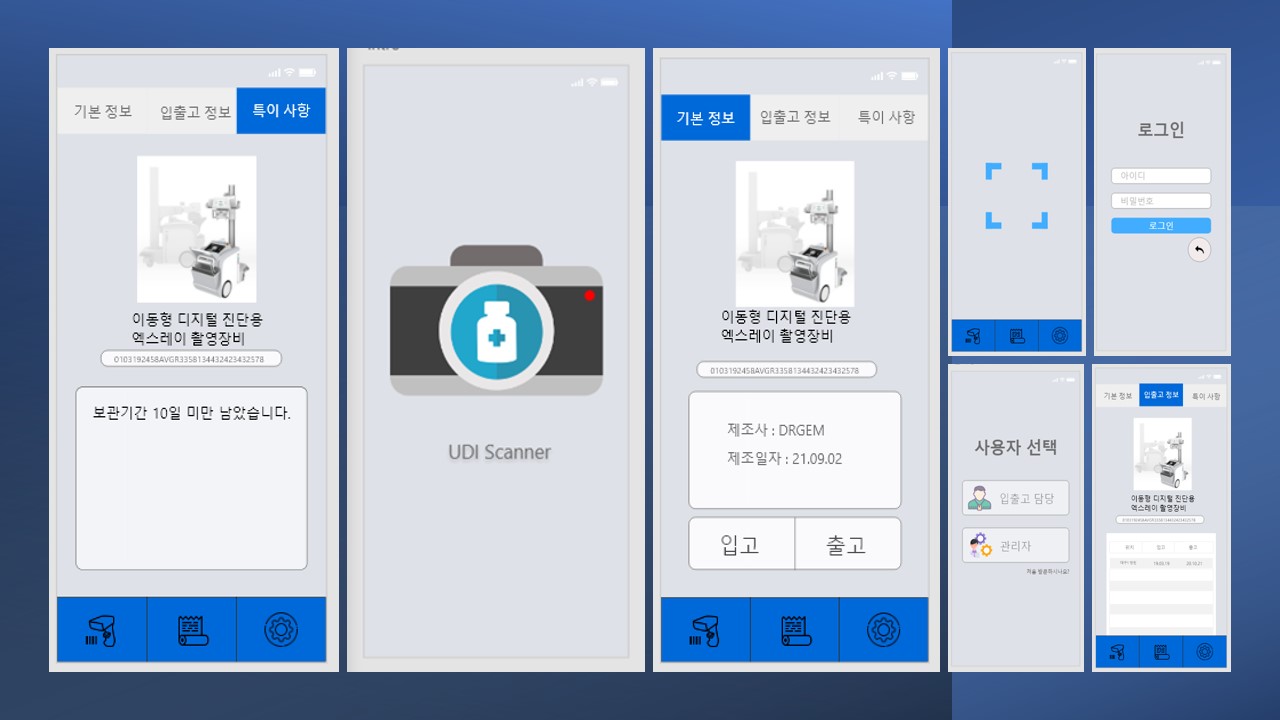
기술 스택 결정
마지막으로 어떤 프로그래밍 언어를 사용해서 개발할 것인지 정했다. 초기 프로토 타입 개발 단계와 차후 서비스 및 스택 확장까지 고려해서 결정했다.
| 범위 | 프로그래밍 언어 | 설명 |
|---|---|---|
| App | Flutter | Flutter를 활용하여 Android와 ios에서 사용 가능한 앱 어플리케이션을 제작한다. |
| Server | Python | Python과 flask를 사용하여 UDI 바코드를 해석하고 의료지원시스템과 통신 가능한 서버를 구축한다. |
| Node js | (차후 확장 기능) Node js를 활용하여 의료지원시스템의 기능을 구현한 Mock server를 구축한다. | |
| DB | MySQL | (차후 확장 기능) 프로토 타입 개발에는 In-Memory(배열)를 사용하여 구현하고 차후 MySQL로 확장한다. |
ch.2 바코드 인식 기능 세부 설계
바코드 해석 방법 선택

바코드 데이터를 해석하기 위한 라이브러리로 zbar를 사용하기로 했다. ZBar 는 C++, Python, Perl 및 Ruby 바인딩 이 포함된 오픈 소스 C 바코드 판독 라이브러리로 바코드 패턴 인식 부분에서 가장 많이 사용되는 라이브러리다.
python에서는 zbar 라이브러리를 사용하기 위해선 pyzbar 라는 라이브러리를 별도로 사용해야한다.
Python 웹 프레임워크 선택
Python 웹 프레임워크에는 django와 flask가 있다. 나는 고민 끝에 flask를 사용하기로 했다.
이때 내가 고려한 점은 아래와 같다.
- 후배들이 쉽게 로컬 서버 개발환경을 구축할 수 있는가?
- 초기 진입 장벽이 낮은가?
1. 후배들이 쉽게 로컬 서버 개발환경을 구축할 수 있는가?
후배들은 DB 수업을 듣지 않았기 때문에 DB 환경 세팅 및 ORM, SQL에 대한 개념이 잡혀있지 않았다. 이 때문에 별도의 DB를 사용하지 않고 내부 배열을 사용한다.
그러나 django는 ORM을 사용하기 때문에 MySQL과 같은 DB가 필수적이다. 만일 django를 선택하면 별도의 DB 세팅과 ORM의 개념 학습이 필요하기 때문에 로컬 서버 개발환경 구축이 어려울 것이다.
2. 초기 진입 장벽이 낮은가?
django는 flask랑 비교했을 때 약 10배 가량 무거운 프레임워크다. 따라서 지켜야할 규칙(?) flask에 비해 많다. MTV 구조나 wsgi, 의존성 주입 등 django에 익숙해지기 위한 개념 공부가 선행되야 한다.
3~4 개월이라는 짧은 개발 기간동안 진행되는 상황에서 django 스터디에 할애할 시간이 부족했기 때문에 초기 진입 장벽은 낮은(물론 숙달됐을 경우 django가 훨 쉽지만) flask를 사용하는 것이 좋다고 판단했다.

바코드 인식 시퀀스 정의
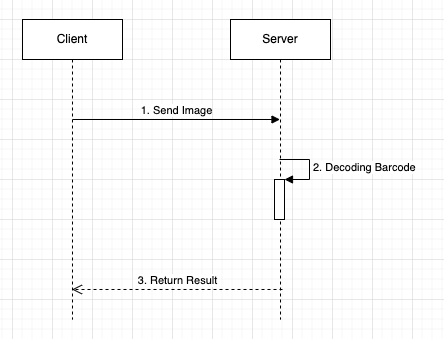
- multiple file을 통해서 barcode image를 flask 서버로 전송
- pyzbar & zbar 라이브러리를 통해 barcode image 해석
- 해석한 데이터를 반환
ch.3 바코드 인식 기능 개선
우리 서비스의 핵심은 얼마나 정확하게 barcode를 인식하냐 이고 현재 이 기능은 zbar 라이브러리에 의존적이다.
따라서 우리가 구한 UDI 바코드를 가지고 24개의 테스트 케이스를 만들어서 zbar 라이브러리만 사용했을 때 성공률을 구해봤다.
테스트에 사용한 라이브러리는 pytest 라이브러리이며 95%의 성공률을 보여야 테스트 통과이다.
from src.main.item.service.ItemService import ItemService
from src.main.item.infra.ItemRepositoryDataSourceImple import ItemRepositoryDataSourceImple
from werkzeug.utils import secure_filename
import numpy as np
import cv2
import pytest
itemRepository = ItemRepositoryDataSourceImple()
itemService = ItemService(itemRepository)
def test_success_upload_read_frame():
# given
targets = []
value_results = []
index_results = []
for i in range(1,21):
targets.append("barcode_" + str(i) + ".jpeg")
# when
for target in targets:
img = cv2.imread('static/uploads/' + secure_filename(target))
result = itemService.read_frame(img)
value_results.append(result.result)
for index, result in enumerate(value_results):
if result:
index_results.append(index)
point = len(index_results) / len(targets)
# then
print()
print(f"point : {point}")
assert point > 0.95python3 -m pytest 'test file path'
단순히 zbar 라이브러리만 사용했을 경우, 성공률은 약 65%으로 매우 낮은 수치다.
아무리 프로토타입이라고 해도 이는 너무 낮은 수치였기 때문에 이미지 전처리 과정을 통해서 성공률을 높여야 한다.
우선 여러 전처리 기법을 적용해보면서 가장 성공률이 높은 케이스를 찾아보기로 했다.
제일 처음 적용할 전처리 기법은 이미지 흑백 처리다. 이미지 처리할 때, 다양한 색상은 오히려 정확도를 낮출 수 있기 때문에 이를 흑백 처리하여 정확도를 높일 수 있다.
# when
for target in targets:
img = cv2.imread('static/uploads/' + secure_filename(target))
# 흑백 처리
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
result = itemService.read_frame(gray)
value_results.append(result.result)
그 결과 정확도는 78%까지 올라갔다.
다음으로는 이진화 처리를 해보기로 했다. 이진화 처리는 threshold 값을 정해줘서 그 값보다 크면 255, 작으면 0으로 값은 반환시켜 흑백 대비를 강하게 해준다.
# when
for target in targets:
img = cv2.imread('static/uploads/' + secure_filename(target))
# 흑백 처리
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 이진화 처리
ret, t_image = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
result = itemService.read_frame(t_image)
value_results.append(result.result)
이진화처리를 하니 오히려 성능이 43%대로 떨어졌다.
관련 리서치를 해보니 이진화처리 전에 sharpning 처리를 해주면 성능이 올라갈 수 있다고 한다.
# when
for target in targets:
img = cv2.imread('static/uploads/' + secure_filename(target))
# 흑백 처리
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# sharpning mask
kernel_sharpen_1 = np.array([[1,-2,1],[-2,5,-2],[1,-2,1]])
# sharpning
f_image = cv2.filter2D(gray,-1,kernel_sharpen_1)
# 이진화 처리
ret, t_image = cv2.threshold(f_image, 127, 255, cv2.THRESH_BINARY)
result = itemService.read_frame(t_image)
value_results.append(result.result)
성능이 39%대로 더 떨어졌다. 아무래도 테스트 케이스의 밝기 값이 일정하지 않다보니 sharpning과 이진화 처리가 마이너스 효과를 가져온 듯 하다.
따라서 barcode 이미지에 흑백 처리만 해주기로 했고 약 65%의 성공률을 78%까지 올릴 수 있었다.
# 최종 테스트 코드
from src.main.item.service.ItemService import ItemService
from src.main.item.infra.ItemRepositoryDataSourceImple import ItemRepositoryDataSourceImple
from werkzeug.utils import secure_filename
import numpy as np
import cv2
import pytest
itemRepository = ItemRepositoryDataSourceImple()
itemService = ItemService(itemRepository)
def test_success_upload_read_frame():
# given
targets = []
value_results = []
index_results = []
for i in range(1,24):
targets.append("barcode_" + str(i) + ".jpeg")
# when
for target in targets:
img = cv2.imread('static/uploads/' + secure_filename(target))
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
'''
kernel_sharpen_1 = np.array([[1,-2,1],[-2,5,-2],[1,-2,1]])
f_image = cv2.filter2D(gray,-1,kernel_sharpen_1)
ret, t_image = cv2.threshold(f_image, 127, 255, cv2.THRESH_BINARY)
'''
result = itemService.read_frame(gray)
value_results.append(result.result)
for index, result in enumerate(value_results):
if result:
index_results.append(index)
point = len(index_results) / len(targets)
# then
print()
print(f"point : {point}")
assert point > 0.95ch.4 서비스 배포
서비스 구현이 끝나고 발표 준비를 위해 AWS EC2에 서버를 배포하고자 했다.

이때 zbar 라이브러리 설치 관련 이슈가 생겼다.

AWS EC2의 Linux에서는 yum을 통해서 패키지를 관리하는데 yum에 zbar 라이브러리가 등록되어 있지 않았다.
여기서는 apt-get 패지키 관리자도 쓸 수 없기 때문에 zbar을 설치할 수 없었다.
rpm 패키지를 사용할 수 있으나 베이스 path 설정 문제랑 pyzbar와의 호환 문제로 설치할 수 없었다.
이 EC2 zbar 설치 이슈 해결을 위해서 Docker를 사용하기로 했다.
Docker는 가상화 OS 기술로 Docker만 설치할 수 있으면 OS에 구애받지 않고 배포 환경을 구축할 수 있다.
즉 EC2에 도커를 설치하고 도커 컨테이너에 zbar를 설치한 후, flask 서버를 돌리면 충분히 배포를 할 수 있을거란 판단이었다.
바로 도커파일을 만들어서 배포 환경을 구축했고 EC2 서버에 컨테이너를 돌렸다.
Dockerfile
# start with a base image
FROM python:3.9
# update working directories
ADD . .
WORKDIR .
# install dependencies
RUN apt-get update
RUN apt-get upgrade -y
RUN apt-get install zbar-tools -y
RUN apt-get install libzbar-dev -y
RUN apt-get install libgl1-mesa-glx -y
RUN pip3 install -r requirements.txt
EXPOSE 3000
CMD ["python3", "app.py"]EC2 내 커맨드
sudo yum install docker -y
sudo systemctl start docker
git clone https://github.com/gimseonjin/bacord_recognition_server.git
cd barcode_recongition_server
sudo docker build -t barcode_recongition_server .
sudo docker run -p 8080:8080 barcode_recongition_server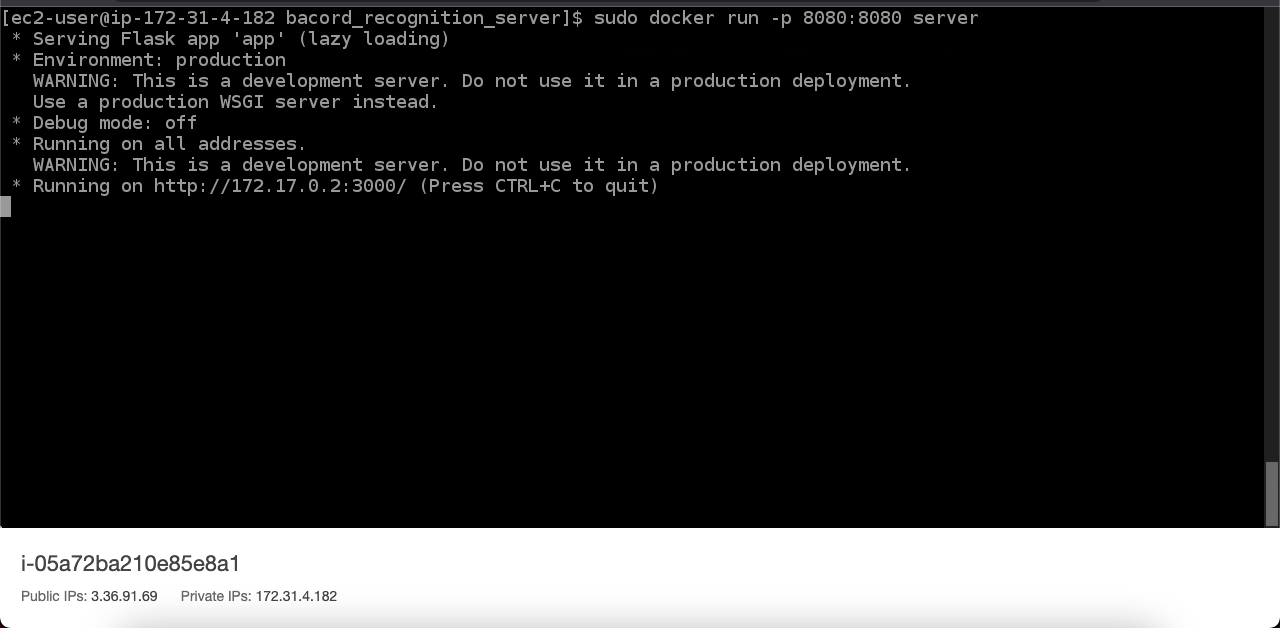
성공적으로 배포한 것을 확인할 수 있다!!!
ch.5 결론
처음 PM으로써 프로젝트를 진행해봤다. 초기 요구사항 분석부터 설계, 구현, 배포 및 발표까지 개발 사이클을 처음부터 끝까지 돌려봤으며 그러한 과정을 통해 정말 많은 것을 배웠다.
그 중 가장 크게 와닿은 것은 PM의 덕목 중 하나는 달성할 수 있는 목표를 정해야 한다. 는 것이다.
실제 프로젝트를 진행하면서 위에서 설계한 기능 7개 중 4개 밖에 구현하지 못했다. 심지어 의료기기통합정보시스템과의 API 통신 기능은 손도 대지 못했다.
따라서 이부분은 차후 확장 가능한 기능이다! 라고 발표를 하긴 했지만 제대로 목표를 설정하지 못해서 애매하게 마무리한 것이기 때문에 많이 찜찜했다. 특히 애자일에서는 목표 설정이 중요한데 제대로 하지 못한 것 같아서 너무 아쉬웠다.
따라서 나는 이 프로젝트 경험을 통해 백엔드 개발자로써의 역량을 갖추는 것도 중요하지만 PM의 능력도 함께 갖춘 인재가 되고 싶단 생각이 들었고 앞으로 쭈욱 준비를 해나가야겠다고 다짐했다.
(아 여담으로 우리는 해당 공모전에서 동상을 수상했다.)

