들어가며
올해 4학년 1학기 프로젝트에 들어가기 앞서 한 가지 목표를 세웠다. 지난 프로젝트 마지막에 AWS에서 배포를 해보려고 했으나 실력 부족으로 성공하지 못했다. 따라서 이번 프로젝트에서는 꼭 프로젝트를 배포해서 실 사용자를 유치해보자라는 목표를 세웠고 프로젝트를 시작했다.
프로젝트 주제 선정
이번 프로젝트 팀 주제 선정에 있어서 다들 한번씩 경험해봤기 때문에 다양한 주제가 나왔다. 그 중 우리가 선택한 주제는 "청년들에게 행복 주택 정보를 제공하는 커뮤니티"이다.
문제 정의
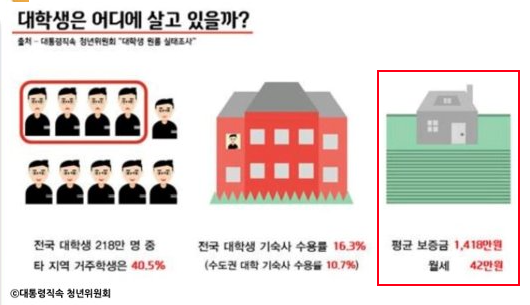
지속적인 경제 불안정은 부동산 폭등으로 이어졌으며 청년들이 재산에 맞는 집을 찾기 어려웠다. 아래 자료에 따르면 청년들이 내집 마련에 필요한 시간은 약 7년 4개월이 걸리며 이는 사회 초년생들에게 큰 부담이 된다.

이러한 청년들에게 행복주택은 좋은 대안이다. 실제로 아래 자료에 따르면 행복주택의 보증금과 임대료를 대학생 평균과 비교했을 때, 비슷한 보증금에 월세가 약 6배 차이나는 것을 확인할 수 있다.

그러나 실제 청년들이 행복주택 제도를 활용하기에는 어려움이 존재한다. 이러한 문제는 다음과 같은 원인으로 야기된다.
현 시장의 문제점
우선적으로 절대적인 정보의 부족이다. 행복 주택은 정부에서 시행하는 사업으로 정부에서 제공하는 정보에 의존한다. 따라서 시행사나 부동산에서 정보를 제공하는 민간에 비해 정보가 매우 부족하다.
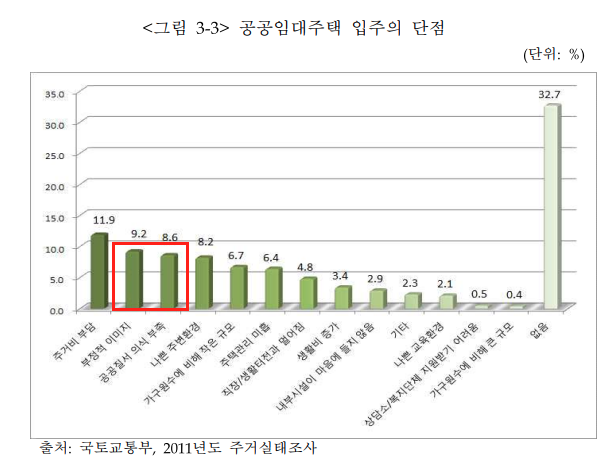
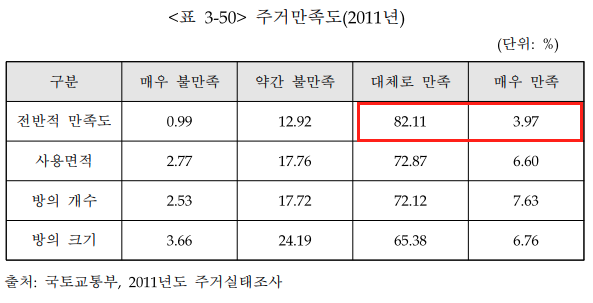
두번째로는 행복주택에 대한 부정적인 인식이다. 2017년도에 발표된 "공공주택정책의 개선방안 연구"에 따르면 입주 단점에 대한 설문조사에서 67.2%가 있다고 답했다. 그 중 9.2%가 부정적 이미지, 8.6%가 공공질서 의식 부족이었다. 그러나 실제 주거 만족도에서 만족스럽다는 평가가 약 86%에 달한다. 즉 실제로 행복 주택에서의 삶은 만족스럽지만 외부인이 봤을 때 부정적인 이미지로 보인다는 것이다.
기 진출한 서비스 플랫폼의 문제
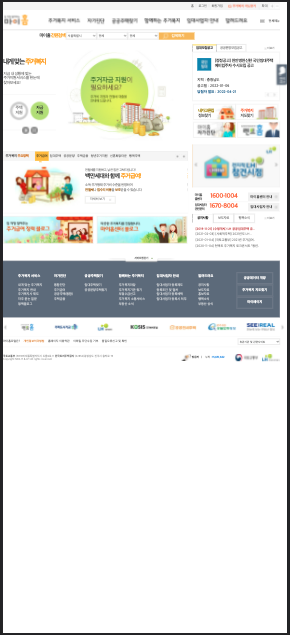
첫 번째 문제점은 바로 불편한 사용자 인터페이스다. 아래 페이지는 실제 정부에서 운영하는 마이홈 페이지를 모바일로 접속했을 때 보이는 화면이다. 청년들은 거의 모든 정보를 모바일을 통해서 획득하는데 마이홈 포털 모바일 인터페이스의 접근성은 매우 낮다.
두 번째 문제점은 서비스 제공자 중심의 정보 공급이다. 현재 대표적인 서비스 플랫폼은 직방과 집토스가 있다. 둘은 사용자 후기를 제공한다 안한다의 차이가 있지만 민간에서 제공하는 모든 부동산 정보를 다룬다. 따라서 해당 플랫폼에서 행복주택 정보 및 후기를 찾는 것은 오래 걸리고 번거롭다.
도출한 결론
따라서 우리 팀은 행복주택의 유용한 정보를 분기/반기별 통계 수치로 제공하고 리뷰 서비스를 통한 주택의 신뢰도 및 새로운 정보 획득 할 수 있으며 사용하기 편한 사용자 친화적 UI 제공을 통해 위의 문제를 해결하고자 한다.
요구사항 도출
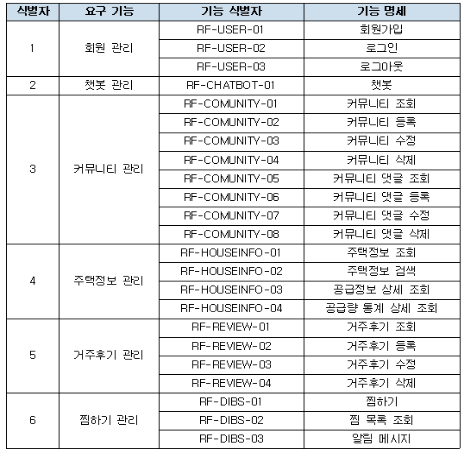
서비스 기능 정의
행복주택 알리미에서 제공하는 기능을 정의했으며 아래와 같다.
프로젝트 설계
프로젝트 기술 스택
- 웹 개발

MERN 스택은 MongoDB, Express js, React, Node js로 구성된 스택으로 Javascript 기반으로 개발 가능한 웹 풀스택이다. React를 활용하여 사용자 친화적인 UX/UI 개발이 쉬우며 MongoDB와 Express js는 빠르게 서버 구축이 가능하다는 장점이 있어 프로토 타입 구축이 쉬워 다음과 같은 스택으로 결정했다.
- 데이터 분석

파이썬은 현재 대표적인 데이터 분석 언어로 활용되고 있으며 사용자 친화적인 고수준의 언어이고 직관적이기 때문에 파이썬을 채택했으며 우리가 필요로 하는 데이터를 공공데이터포털에서 가져와 가공하여 제공하고자 한다.
- 인프라 구축

AWS를 통해 24시간 운영 가능한 서버를 구축하고 AWS의 CDN 서버인 CloudFront를 활용해 속도를 향상시키고 API Gateway를 통해 서버 보안을 강화했다. docker의 OS 가상화 기술을 활용하여 서버 OS에 제약받지 않는 배포 환경을 구축하고자 한다.
- Logging & Application Monitoring
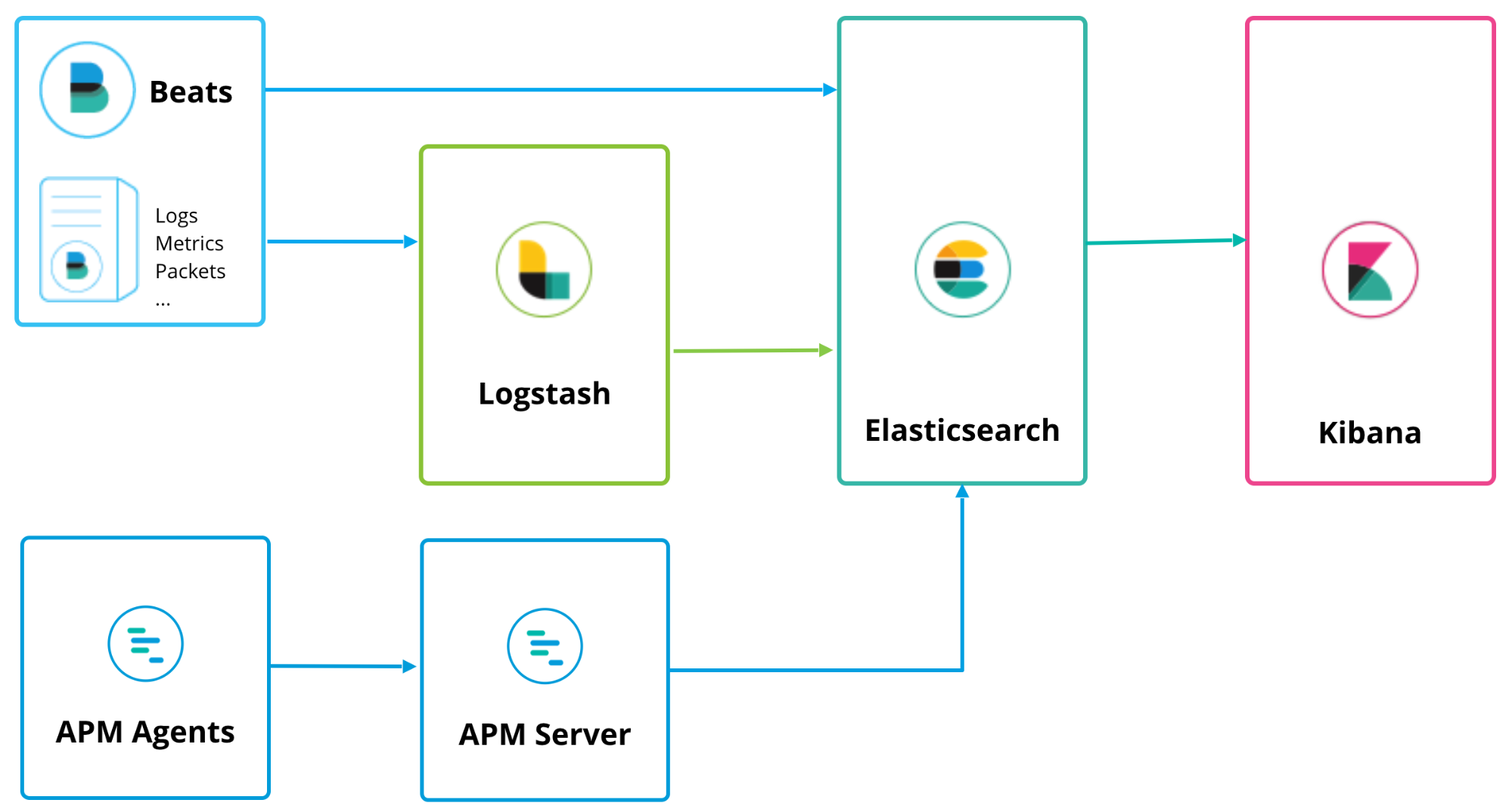
Elasticsearch는 Apache Lucene( 아파치 루씬 ) 기반의 Java 오픈소스 분산 검색 엔진으로 방대한 양의 데이터를 신속하게, 거의 실시간(NRT, Near Real Time)으로 저장, 검색, 분석할 수 있다. 이와 logstatsh와 kibana를 함께 사용하여 로그모니터링을 할 수 있으며 APM을 통해 서버 어플리케이션 모니터링을 구축하고자 한다.
최종 시스템 설계도
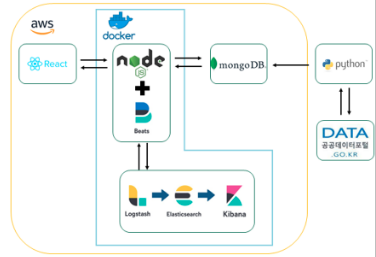
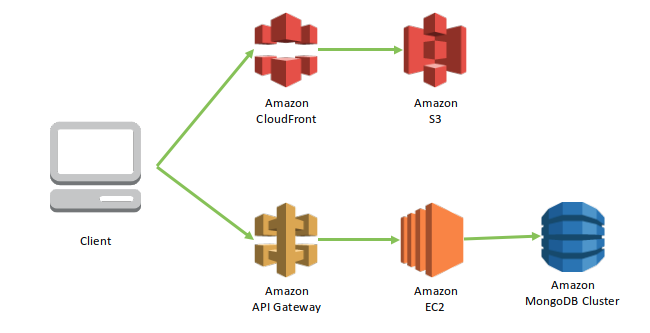
프로젝트 개발 진행
이슈 1. 어떤 데이터가 유용한 데이터인가??
이제 요구사항 추출과 설계가 완료됐으니 개발을 진행해야 한다. 그러나 아직까지 우리는 사용자에게 어떤 데이터를 제공해야 유용할 지에 대해 정해지지 않았다.
행복주택 주변의 로드뷰 제공, 근처 맛집 리스트 제공, 주택의 빈 방 제공 등 다양한 의견이 제시됐지만 확 와닿지 않았다. 이때 행복주택의 주변 시설을 다른 행복주택들과 비교해서 보여주는 것이 어떤가라는 의견을 제시했고 채택이 되어 행복주택 데이터 제공를 담당하게 됐다.(이때는 엄청난 고생을 할 것이라고 생각도 못했다.)
이제 어떤 데이터를 제공해야하나에 대해 리서치를 했다. 우선 행복주택을 이용하는 계층을 분석했고 1인 가구가 많다는 것을 확인했다. 이에 1인 가구가 이사할 때 중점으로 보는 요소를 찾아 다음과 같은 키워드를 추출했다.
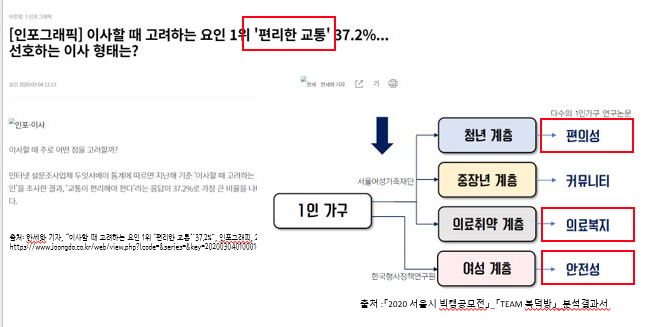
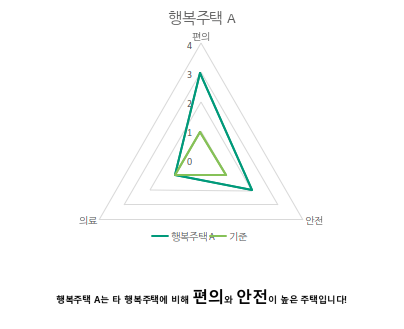
청년 계층이 선호하는 편의성은 편리한 교통과 일맥 상통하기 때문에 두 키워드를 합쳤고 중장년 계층의 커뮤니티는 우리 사이트가 제공하는 커뮤니티 기능으로 제공 가능하기에 제외했다. 그 밖에 의료복지와 안전성 키워드를 가져와서 아래와 같이 방사형 그래프를 만들어 제공하기로 했다.
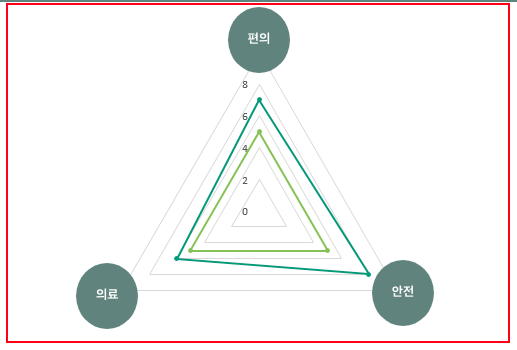
이제 각 키워드의 점수를 계산해야 하는데 점수 산출 방식은 "해당 행복주택 인근의 키워드와 관련된 시설의 개수"를 기준으로 산출하였다.
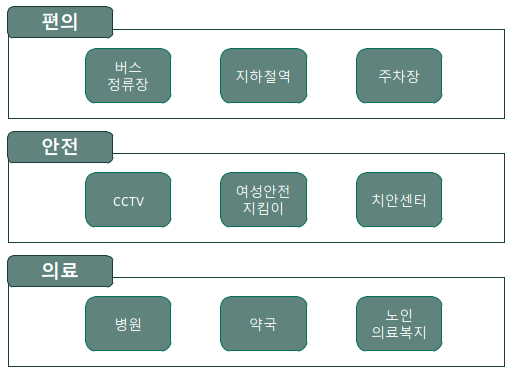
편의 시설은 교통과 관련된 시설로 정했으며 행복주택 주변 버스정거장, 지하철역, 주차장으로 선정했다. 의료 시설은 행복 주택 주변 병원, 약국, 노인 복지 센터로 선정했으며 안전 시설은 CCTV, 여성안전지킴이, 치안센터로 선정했다.
공공데이터 포털에서 제공하는 API와 CSV를 통해 데이터를 수집하였고 총 42만개의 데이터를 모을 수 있었다.
이제 행복주택 인근에 존재하는 시설의 개수를 파악해야 했다. 이때 사용한 라이브러리는 haversin 라이브러리로 파이썬에서 거리를 측정할 수 있는데 반경 1km이내의 시설 개수를 측정하기로 했다.
# 간단한 예시 코드
# 실제 코드는 가독성이 떨어져서 대표 예시 코드를 임의로 구현했습니다.
from haversine import haversine
list = []
# 위경도 입력
target = (getLat(), getLong()) #Latitude, Longitude
for i in facilitis: # 엑셀에서 데이터를 받아와 미리 저장한 객체
if haversine(target, i, unit = 'km') < 1:
list.append(i)
그러나 어떤 데이터는 도로명 주소를, 어떤 데이터는 위경도 데이터를 제공했다. 따라서 이 데이터들을 위경도 데이터로 통일시켜야 했다. 이때 사용한 툴이 Geocoder-Xr이다.
처음에는 구글맵 api에서 제공하는 기능을 사용했으나 데이터가 워낙 많아서 프리티어를 다 사용했기 때문에 Geocoder-Xr 툴로 변경했다.
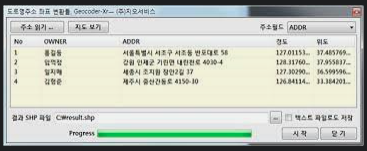
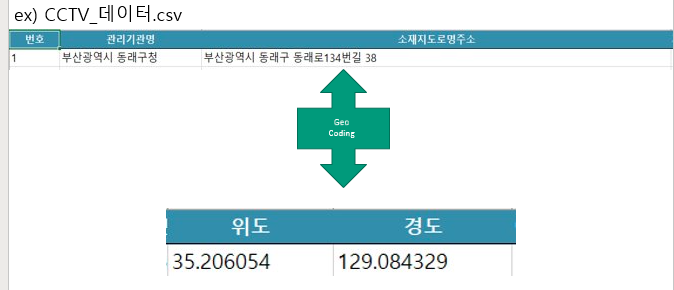
이제 변경된 위경도 데이터를 가지고 반경 1km 내의 시설 개수를 측정, 최대 최소 정규화 방법을 통해 0~1까지의 수치로 변환시켰습니다.
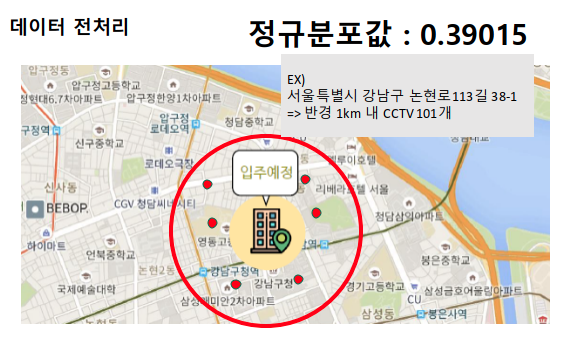
그리고 가중치를 부여해서(최솟값 정의 등) 1부터 3까지의(보통 ~ 매우 좋음) 방사형 그래프로 표현했습니다. 다만 여기서 몇점부터 좋은 행복주택인가?에 대한 기준이 필요했습니다. 그래서 모든 행복주택의 키워드별 산점도를 출력했습니다.
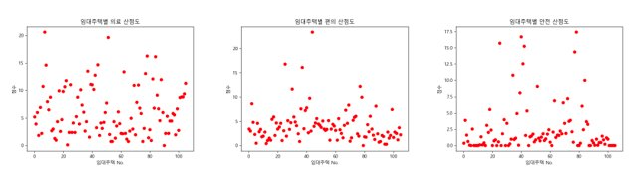
이제 각 산점도 별로 주택이 많이 분포하는 범위를 선정하여 다음과 같은 기준을 세웠습니다.
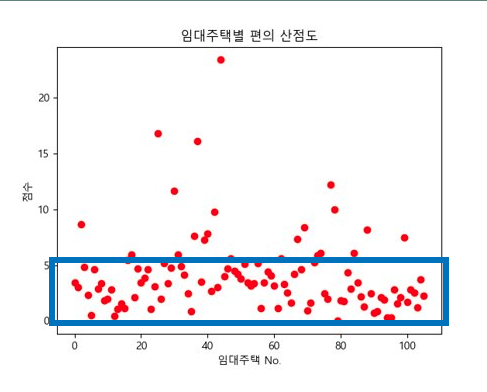
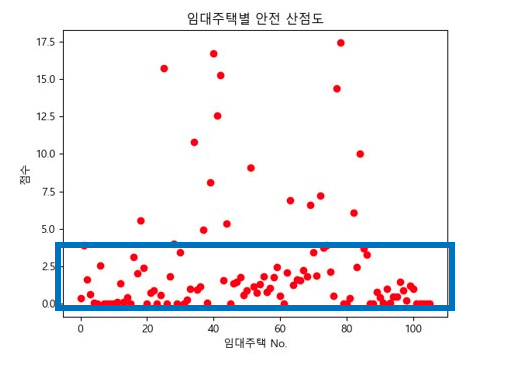
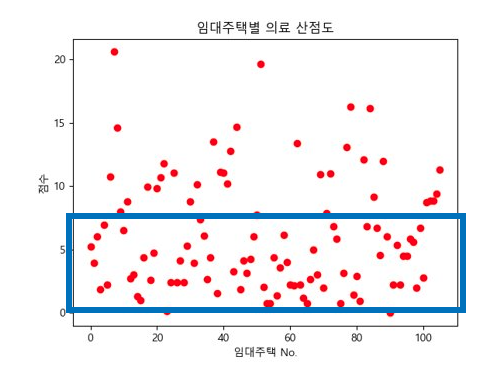

실제 각 기준별 행복주택 분포 개수를 보면 다음과 같이 분포된 것을 확인할 수 있으며 최종적으로 아래의 그래프를 도출하였습니다.
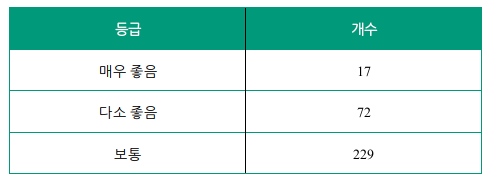
이슈 2. Restful한 서버 개발
이제 제공할 데이터가 정해졌으니 필요한 데이터를 어떻게 front에게 전달해줄 것이냐는 이슈가 남았다. 우리가 선택한 방법은 Restful API 방식이다.
로이 필딩이 발표한 REST paper을 보면 효율적인 데이터 처리를 위해 REST API라는 아키텍처를 제시했다. 여기서 로이 필딩은 아키텍쳐의 제약을 가하면서 발전시키는 방식을 제시하면서 'Clinent-side Architecture'와 'layerd Architecture', 그리고 'REST Architecture'를 제안했다.
이 REST Architecture은 제약이 정말 많다. 서버는 stateless해야 하고 response는 cachable한 지 라벨링을 해야 하며 리소스의 자원 출처를 표기하는 Uniform Interface를 제공해야 한다. 이 모든 제약을 지키기엔 너무 오래걸릴 듯 하여 우리는 Method와 URI를 통해 리소스를 가져오는 방식만 RESTful 하게 구현하자는 결론을 도출했다.
- Member 예시
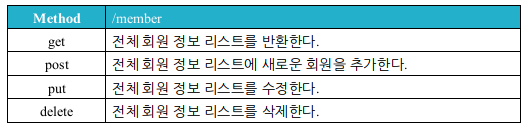
이제 구현한 서버 기능을 front 개발자들이 쉽게 사용할 수 있도록 API 기술 문서를 작성해야했다. 지금에서는 Swagger UI 등을 활용할 테지만 그 당시에는 몰랐기에 일일이 작성했다. 너무 자세하게 작성하기엔 생각보다 양이 많았기 때문에 시퀀스 다이어그램과 Request, Response만 기술하였다.
-
Chat Bot 예시
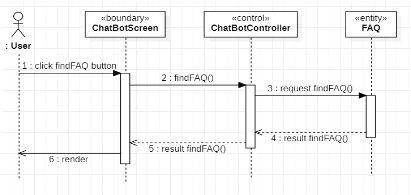
-
Request
| 메소드 | URI | 기능 설명 |
|---|---|---|
| GET | base_url/FAQs | findFAQ() 메소드에 사용하는 URI로 서버에 등록된 모든 FAQ 자료가 넘어옵니다. |
- Responce
{
FAQList :
{
id: String,
category: String,
question: String,
answer: String
},
{
id: String,
category: String,
question: String,
answer: String
},
}이슈 3. Front 코드 리팩토링
서버 기능 구현이 마무리되고 front에서 기능을 구현을 마무리하면 되는 단계가 됐다. 이제 front 기능이 마무리되면 배포할 수 있도록 AWS와 Docker에 대해 공부하고 있었다.
그러다 Front 개발자님이 "서버에서 데이터 받아오는데 너무 오래걸려요!"라고 연락을 주셨다. 서버 코드를 바로 확인해봤는데 큰 문제가 없었고 Postman으로 확인해봐도 281ms 정도로 느리지 않았다.
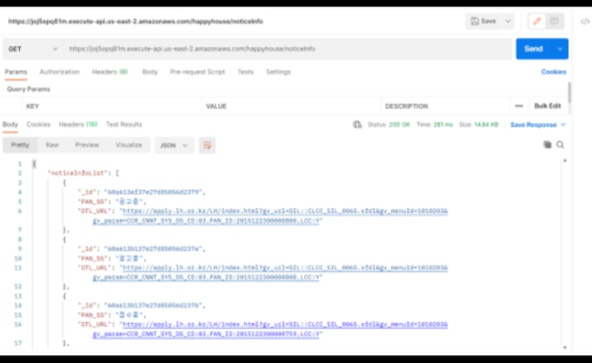
그래서 Front에서 속도가 느리다는 부분을 살펴봤다. 거기서 몇가지 문제점을 발견할 수 있었다. 하나는 서버에서 리소스를 받아오는 메소드를 핸들링하지 않은 것이고 다른 하나는 리랜더링이 필요한 부분과 필요없는 부분을 구분하지 않고 한꺼번에 구현한 것이다.
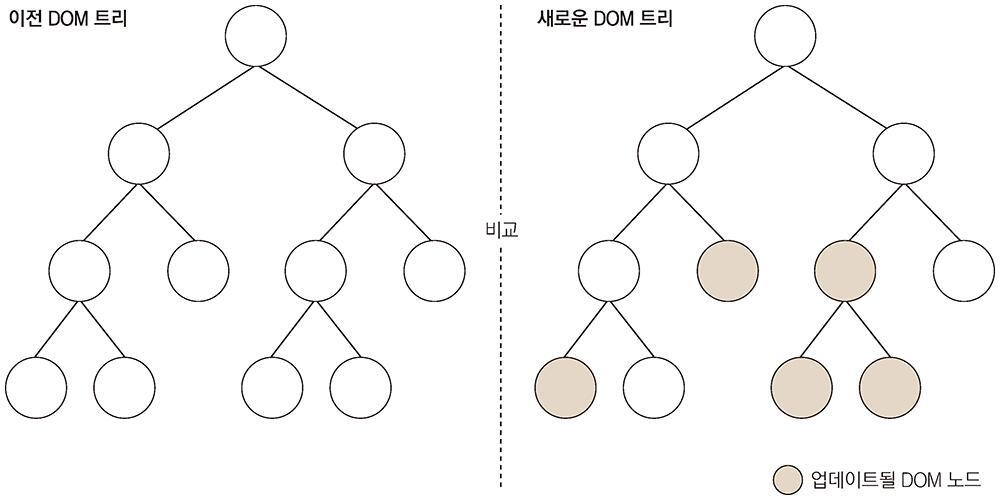
React에서는 리렌더링이라는 개념이 있다. 컴포넌트에서 데이터에 변화가 있을 때마다 View가 바뀌는 것으로 보이지만 실제로는 새로운 요소로 갈아 끼워지는 것이다. 이때 가상 DOM이라는 개념을 도입해서 기존의 DOM과 가상 DOM의 내용을 비교해서 바뀐 것이 있으면 새로운 요소로 갈아끼운다. 갈아끼우면서 변경된 부분의 코드를 재실행한다. 따라서 리렌더링할 부분을 잘 제어하지 않으면 불필요한 부분도 리렌더링되어 성능에 이슈가 생긴다.
아래 코드를 살펴보면 loadDibsData() 메소드를 통해서 서버에서 찜하기 데이터를 받아온다. 그러나 별다른 핸들링없이 바로 {loadDibsData()}로 실행해버렸다. 그래서 리렌더링될 때 마다 서버의 데이터를 요청했고 클라이언트와 서버 모두에 부담을 주면서 성능이 저하된 것이다. 따라서 찜하기 데이터가 필요할 때 가져올 수 있도록 Onclick() 핸들링을 지정했다.
Before
function loadDibsData () {
axios.get(`https://joj5opq81m.execute-api.us-east-2.amazonaws.com/happyhouse/dibs/userid/${userId}`).then(({data}) => {
data = data.dibs
setDibs(data.map(dibs))
})
}
return (
<div menu-bar-wrap>
<div className="menu-bar">
{loadDibsData()} // 리렌더링 될 때마다 서버 데이터 호출!
<div className="logo" onClick = {()=>{window.location.href ='/'}}>
<img alt='logo' src={logo} className="logoImage" />
</div>
...After
...
<div className = "user-container">
<div> {userId} 님 <img alt="likelist hide" src={like} id="likeImage" onClick={()=> {likeShow();loadDibsData()}}/></div>
<div onClick = {() => {alert("안녕히 가세요!"); localStorage.clear(); setIsLogin(false); window.location.replace('/')}}>
<img alt='logo' src={logoutLogo} className="logoutImage" />
</div>
</div>
...
두번째로 리렌더링이 필요한 부분과 필요 없는 부분을 구분하지 못한 경우다. 우리 프로젝트에서 메인 페이지는 MapMarkers 페이지다. 여기서 행복주택의 세부 정보를 보여주는 곳이 바로 왼쪽에 위치한 사이드바다.
이때 사이드바가 MapMarkers.js 안에 다음과 같이 구현되어있다. 사이드바에서 주택 타입 버튼을 클릭하면 MapMarker 전체가 리렌더링됐다. 사이드바는 초기 렌더링에 서버에서 필요한 데이터를 다 가져오기 때문에 리렌더링이 필요없다. 따라서 사이드바의 리렌더링을 막고 MapMarker와 리렌더링 단위를 분리해야한다.
우선 사이드바 코드를 SideBar.js 컴포넌트로 분리하고 react.memo() 함수를 사용하기로 했다. react.memo()는 메모라이제이션이라는 뜻으로 부모 컴포넌트로부터 주입받은 props가 변경되지 않는 한 리렌더링을 하지 않는 기능이다!
Before
// MapMarker.js
...
<div className="side-bar-wrap" >
<div className="side-bar" id="sideBar">
<img alt="sidebar hide" src={cancel} id="sidebarHide" onClick={()=> sidebarHide()}
className="toggle-menu"
/>
<div className="content">
<div className = "imageSection">
<img src={room4} id="roomImage"></img>
</div>
<div id = "houseInfoSection1">
<table className ="houseInfoTable1">
<tr>
<td class = "houseName" colspan="2">{houseDetail.danjiName}</td>
<td class="likeButton"> <img id = "tmp"alt='like' src={like1} className="likeImage" onClick={() => changeImage()}/></td>
</tr>
<tr>
<td className ="houseAddress">{houseDetail.address}</td>
</tr>
</table>
</div>
<div id = "houseInfoSection2">
<div class = "test2">주택정보</div>
{countFunction()}
{countFunctionDetail()}
<table class="houseInfoTable2">
<tr>
<td id = "td1">공급세대</td>
<td colspan="2">{houseDetail.houseHoldNum} 세대</td>
</tr>
<tr>
<td id = "td1">준공일자</td>
<td colspan = "2">
<Moment format="YYYY / MM / DD">{houseDetail.competeDate}</Moment>
</td>
</tr>
<tr>
<td id="td1">주택형</td>
<td id="td1">공공 공용면적</td>
<td id="td1"> 개인 공용면적</td>
</tr>
<tr>
<td>{typeName[selectedIndex]}</td>
<td>{suplyCommuseArea[selectedIndex]}(㎡)</td>
<td>{suplyPrivateArea[selectedIndex]}(㎡)</td>
</tr>
<tr>
<td id="td1">임대 보증금</td>
<td id="td1">전환 보증금</td>
<td id="td1">월 임대료</td>
</tr>
<tr>
<td>{numeral(bassRentDeposit[selectedIndex]).format('0,0')}</td>
<td>{numeral(bassConversionDeposit[selectedIndex]).format('0,0')}</td>
<td>{numeral(bassMonthlyRentCharge[selectedIndex]).format('0,0')}</td>
</tr>
</table>
{drawGraph()}
</div>
<div id = "houseInfoSection4">
<div class = "test2">거주후기<button id = "moreReview" onClick = {()=>{window.location.href ='/reviews'}}>더보기</button></div>
</div>
...After
// MapMarker.js
<div id = "sideBar" style = {{display : "none"}}>
<SideBar houseDetail = {houseDetail} toggle = {()=>sidebarHide()}></SideBar>
</div>// SideBar.js
const SideBar = (props) => {
...
}
export default React.memo(SideBar);이슈 4. 서비스 배포 - 반응형 웹
이번 학기 프로젝트 최종 발표를 일주일 남겨두고 우리 팀은 실제 서비스를 배포해서 실 사용자를 유치해보기로 했다.
네이버의 공공임대주택 카페와 생활코딩에서 홍보를 하였고 서비스를 배포하고 이제 자려고 하는데 PM께 다음과 같이 연락이 왔다.
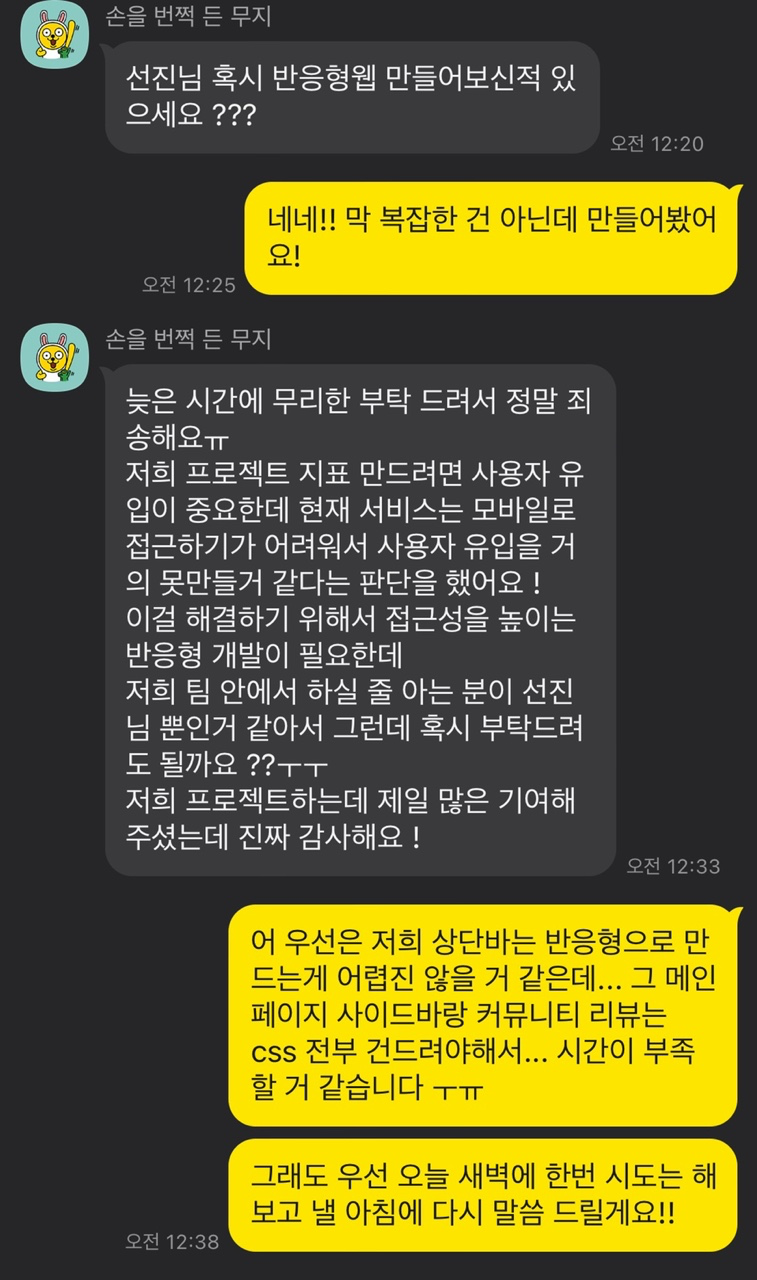
나는 백엔드 개발자인데... front는 나랑 안맞고 어려운데... 하지만 우리 프로젝트 성공을 위해 mediaquery를 활용해서 css 작업을 시작했다.
우선 PM님께 디자인 가이드라인을 요청했고 다음과 같이 디자인 시안을 받았다.
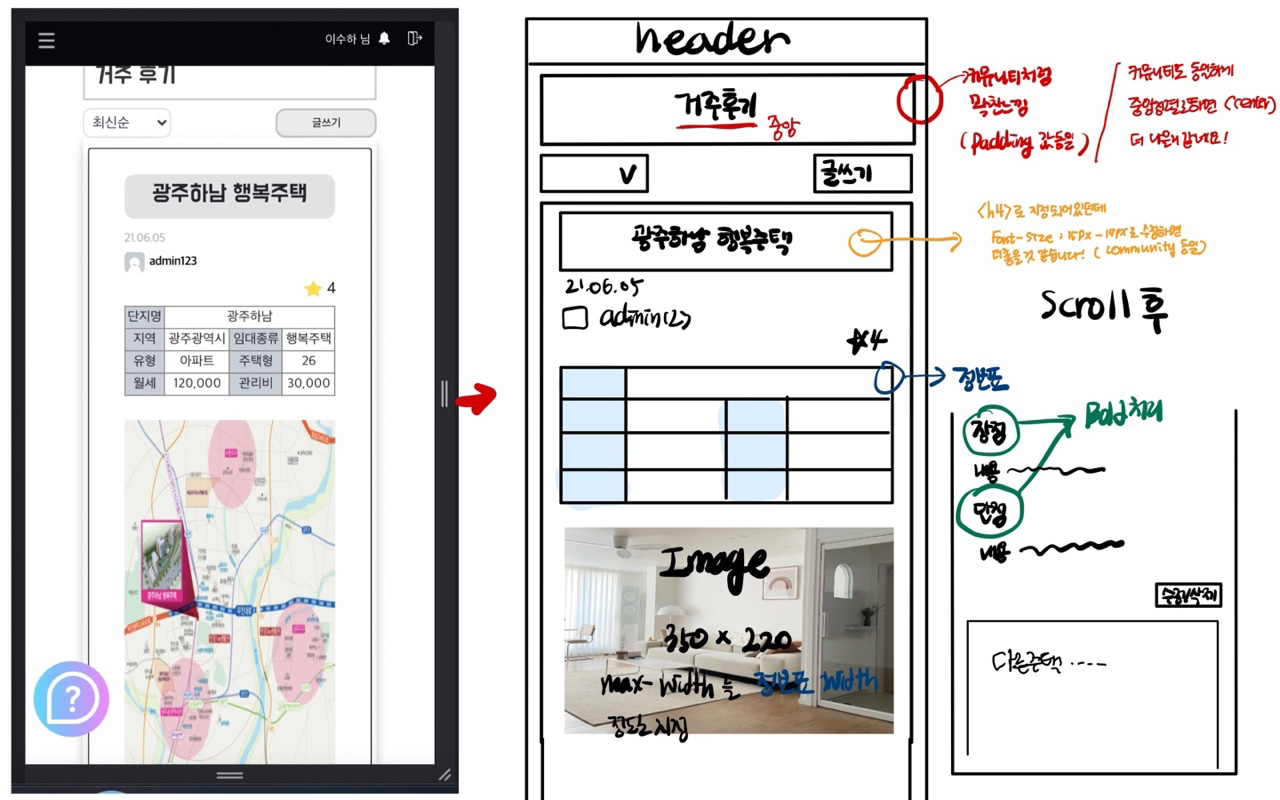
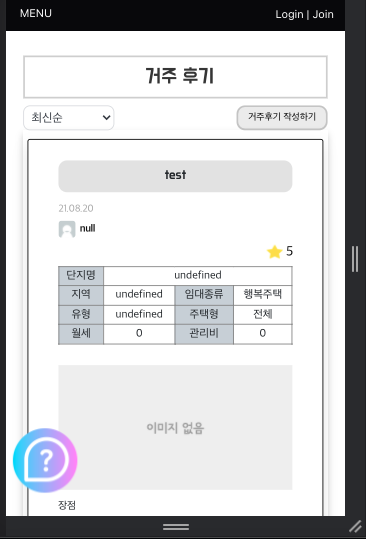
mediaquery를 통해 높이 600이하인 경우 css를 수정하게 했다. 다만 이때 디자인이 크게 달라지는데 웹 상에서의 버튼 위치와 모바일 상의 버튼 위치가 바뀐다. 따라서 react에서 mobile인 경우, mobile이 아닌 경우를 나눠서 컴포넌트를 출력하도록 수정했다.
...
<div className="search-button-group-com">
<select id="community-search-option">
<option>제목</option>
</select>
<button id="community-upload" className={"createCommunityButton"}>글쓰기</button>
</div>
}
</div>
{ !isMobile && activityHistoryList}
{ isMobile && activityHistoryListOfMobile}
...
이슈 5. 서비스 운영 - Log & APM 모니터링
서비스 배포가 끝나고 사용자가 유입되면서 ELK Stack와 Elastic APM에 데이터가 쌓이기 시작했다.
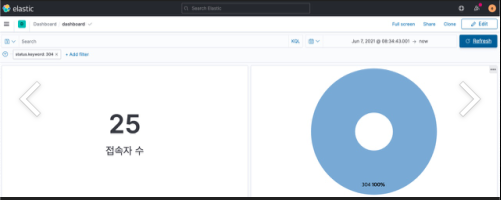
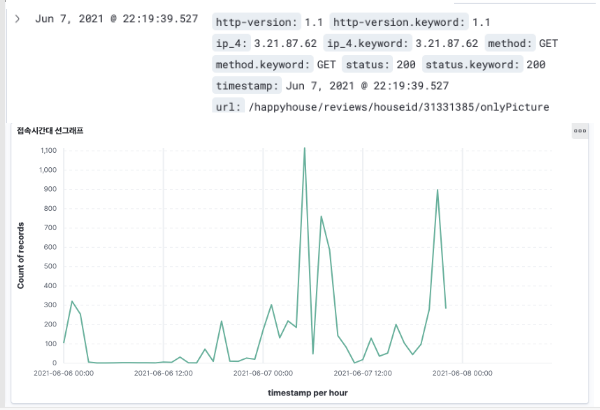
그러다 발표 바로 전 날 팀원들에게 다음과 같은 에러 페이지가 뜬다고 했다.

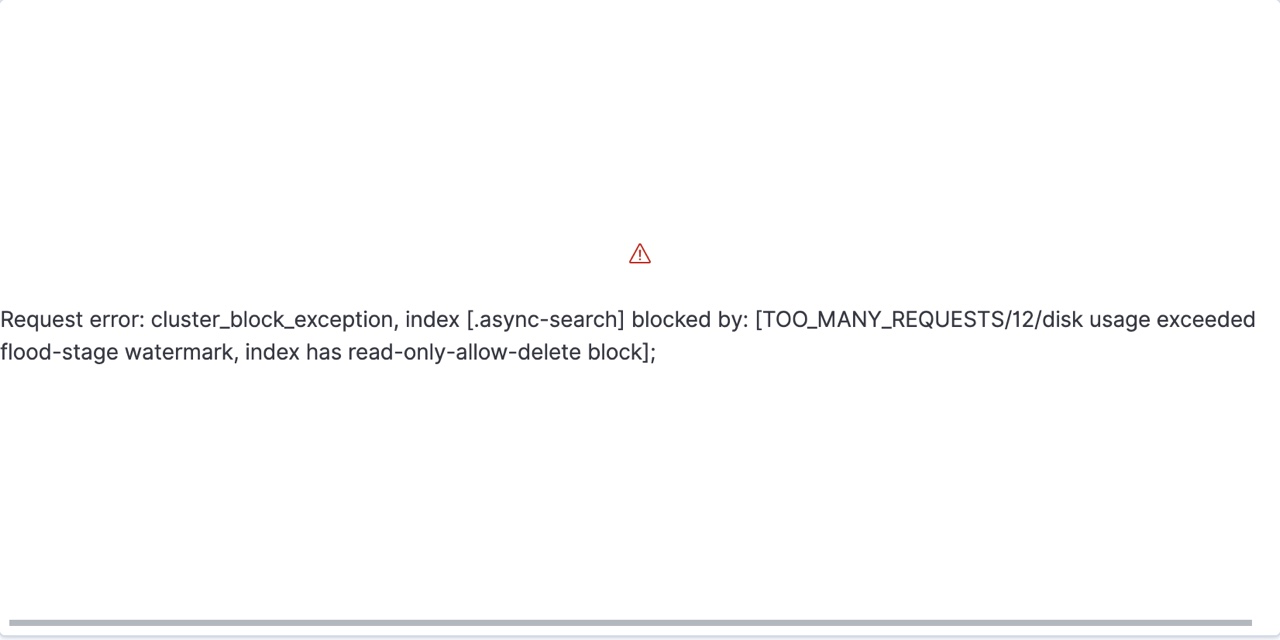
구글신께 여쭤보니 이는 elastic search의 용량 부족 문제라고 한다. 모니터링 환경을 Docker로 구축했는데 로그를 받아오는 경우, 1주일만 해도 엄청난 양의 로그가 쌓여 Docker Container가 감당 하지 못해고 터진 것이다.
EC2 인스턴스를 새로 만들어서 다시 모니터링 환경을 구축하면 되지만 문제는 발표 바로 전 날이라는 것이 문제였다. 지금까지 모아왔던 실 사용자들의 데이터들이 날라가기 때문에 어떻게든 현재 모니터링 인스턴스 내에서 문제를 해결해야했다.
Docker의 용량을 늘리기 위해 bind, mount 등 구글신이 알려주신 메모리 관련된 모든 기능을 다 따라해봤지만 용량은 부족했다! 어떻게 해야하나 고민하던 중 그냥 EC2 자체를 스케일 업 하면 되지 않나 라는 생각이 들었다.
학생인지라 AWS 사용을 프리티어 내에서만 사용해야 한다는 강박이 있었다. 따라서 어차피 내일 발표인데 하루 대여로는 충분히 감당할 수 있다는 생각이 들었고 볼륨을 8 -> 256으로 확 늘려버리니까 잘 열렸다.
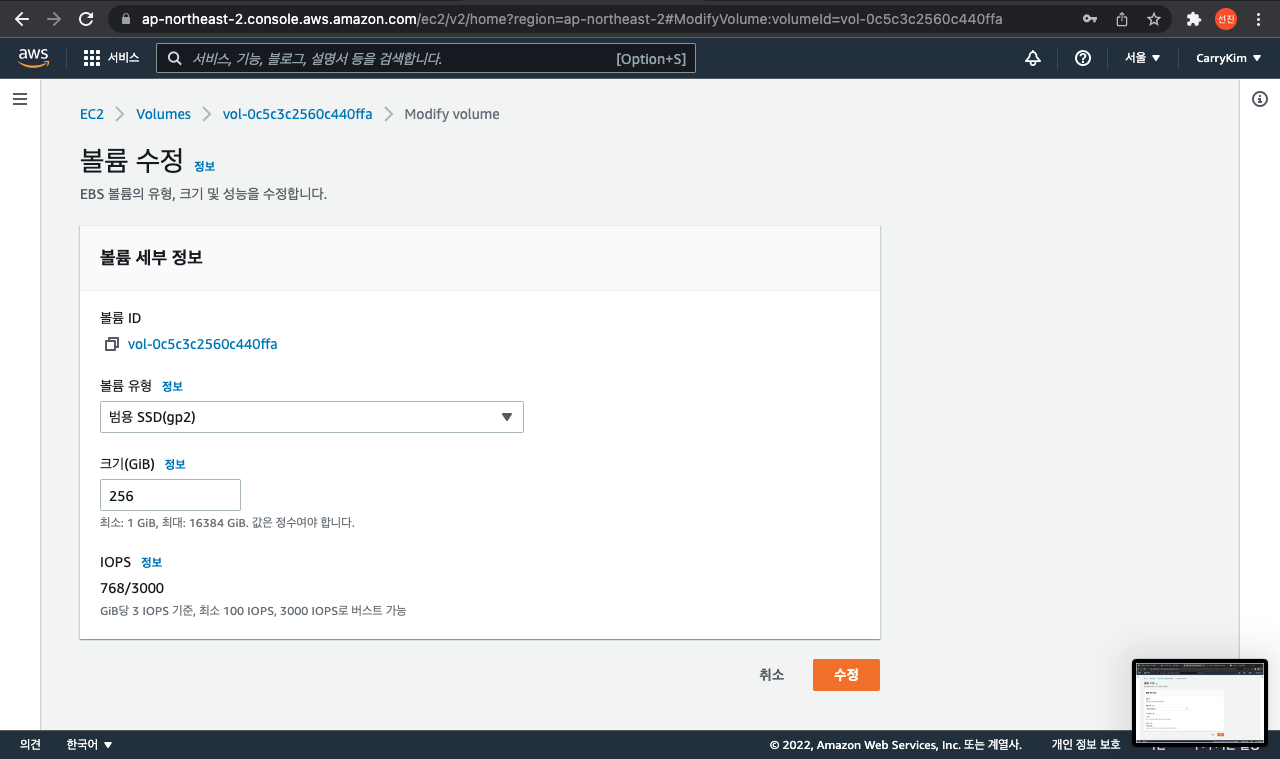
그러나 EC2 볼륨을 키운 상태에서 계속 서비스를 운영하면 비용이 너무 많이 들었다. 볼륨 사이즈가 큰 EC2 인스턴스 하나만 운영하는 것보다 EC2 여러 개의 인스턴스를 운영하는 것이 더 저렴했다. 그래서 별도의 Elastic Search 서버로 분리하여 운영하기로 했다.
새로운 Elastic Search 서버를 구축하고 기존 Node 서버와의 연결은 쉬웠지만 기존에 로그 데이터를 옮기는 것이 문제였다. Elastic Search 홈페이지를 찾아봤을 때, 인덱스를 다시 매핑해야하는 등 불편했고 dump라는 tool을 통해서 해결했다.
- Elastic dump를 활용한 데이터 마이그레이션 방법
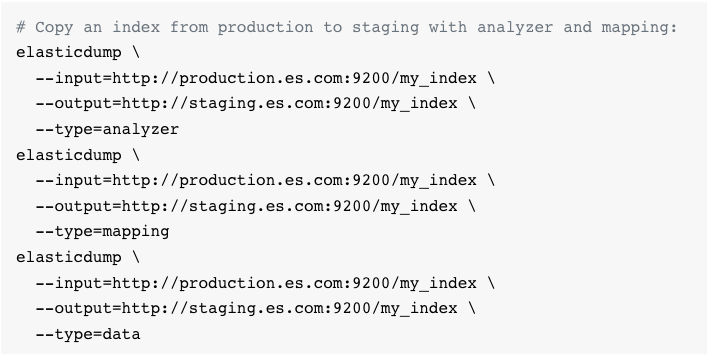
이후 기존 서버의 Elastic Search를 삭제하고 볼륨을 내림으로써 Elastic 서버 이전에 성공하였다.
결론
위 내용들을 잘 정리해서 성공적으로 발표했고 A+이라는 성적을 받았다. 실제로 처음 서비스를 배포해서 사용자를 받아보고 처음 모니터링을 해봤는데 백엔드 개발자는 어떤 업무를 해야하며 Front와 어떻게 의사소통을 해야하는 지 깨달을 수 있는 프로젝트였다.
(Front-end, Back-end, Data Scientist 역할도 해야해서 정말 힘들었다.)
