
✍🏻 3일 공부 이야기.
👀 공부한 내용의 자세한 코드는 아래 깃허브에 올려두었습니다!
https://github.com/nabi4442/ZeroBaseDataSchool/blob/main/02.%20Analysis%20Seoul%20Crime(%20~%2050%25%20).ipynb
서울시 범죄 현황 데이터 분석
🤔"서울 강남3구가 범죄로부터 안전하다는 기사가 나왔었는데, 실제로 그렇게 말할 수 있는지 데이터로 말해보자."
[공공데이터포털]

📌 이번 프로젝트의 목표 : GoogleMaps, Folium, Seaborn, Pivot_table 익히기
데이터 읽기
저번 프로젝트 때 고생했던.. 천 단위 구분 기호를 빼고 읽는 방법이 있어따...ㅠ
pd.read_csv("파일경로/파일명.csv", thousands = ",") #콤마를 제거하고 숫자형으로 읽음- 읽어드린 데이터프레임에 Nan 데이터가 포함되어있는 경우 Nan을 삭제해주어야 함.
crime_raw_data = crime_raw_data[crime_raw_data["죄종"].notnull()]목적에 맞게 우리가 원하는 데이터프레임으로 만들기
- index를 경찰서 이름 -> 구별(원본 데이터에서는 '구분' 컬럼)
- 사건의 합을 기록하기 위해 aggfunc 옵션에 sum
- multi column 정리
crime_station = crime_raw_data.pivot_table(
crime_raw_data,
index = "구분",
columns = ["죄종", "발생검거"],
aggfunc = [np.sum]) # 대괄호없이 np.sum을 해주면 level0의 sum 인덱스가 사라짐
crime_station.columns = crime_station.columns.droplevel([0,1]) #다중 컬럼에서 특정 컬럼 제거GoogleMaps API 설치
경찰서 이름으로 경찰서가 속해있는 구 이름을 찾아내기 위함!
-
Google Cloud Platform 계정을 만든 후, 'Geocoding API'를 검색해 <사용> 눌러주기
-
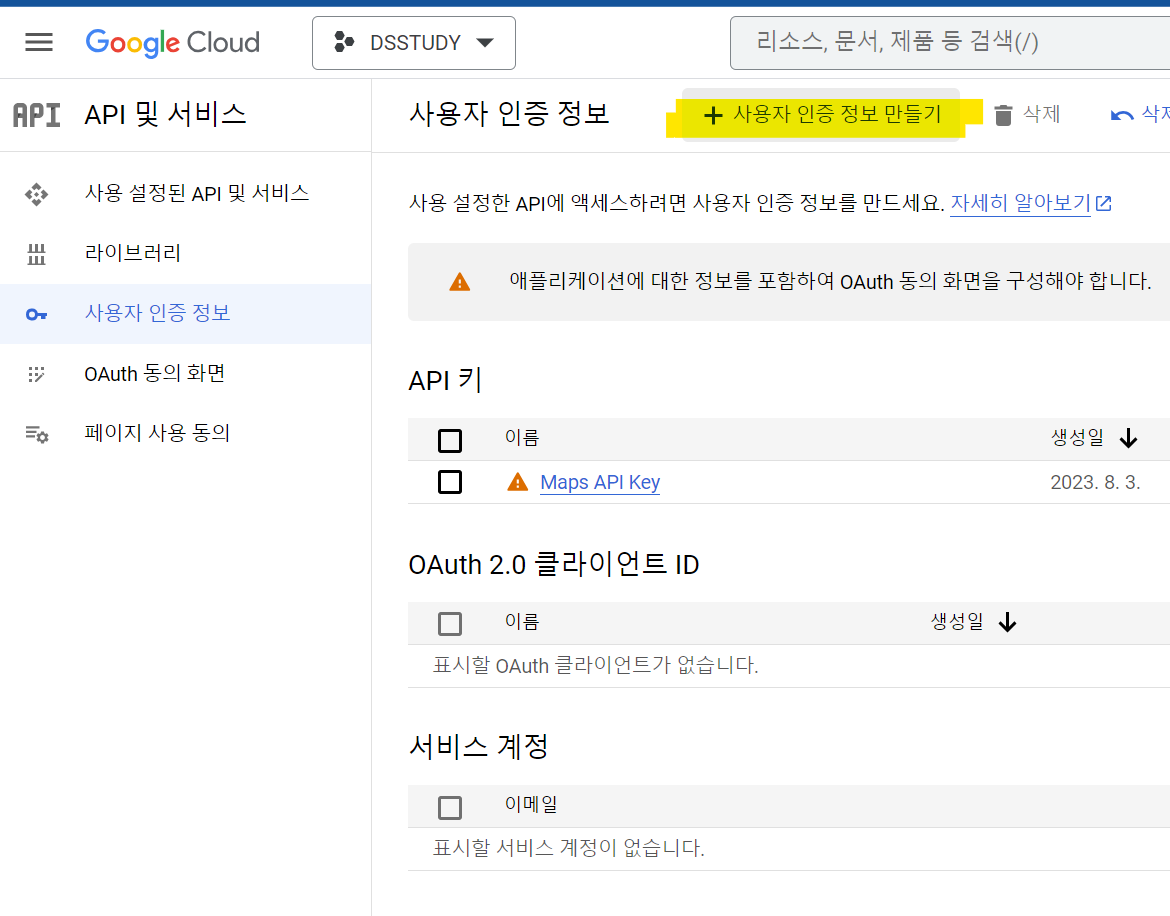
-
위 사진에 들어가서 API KEY 발급받기
-
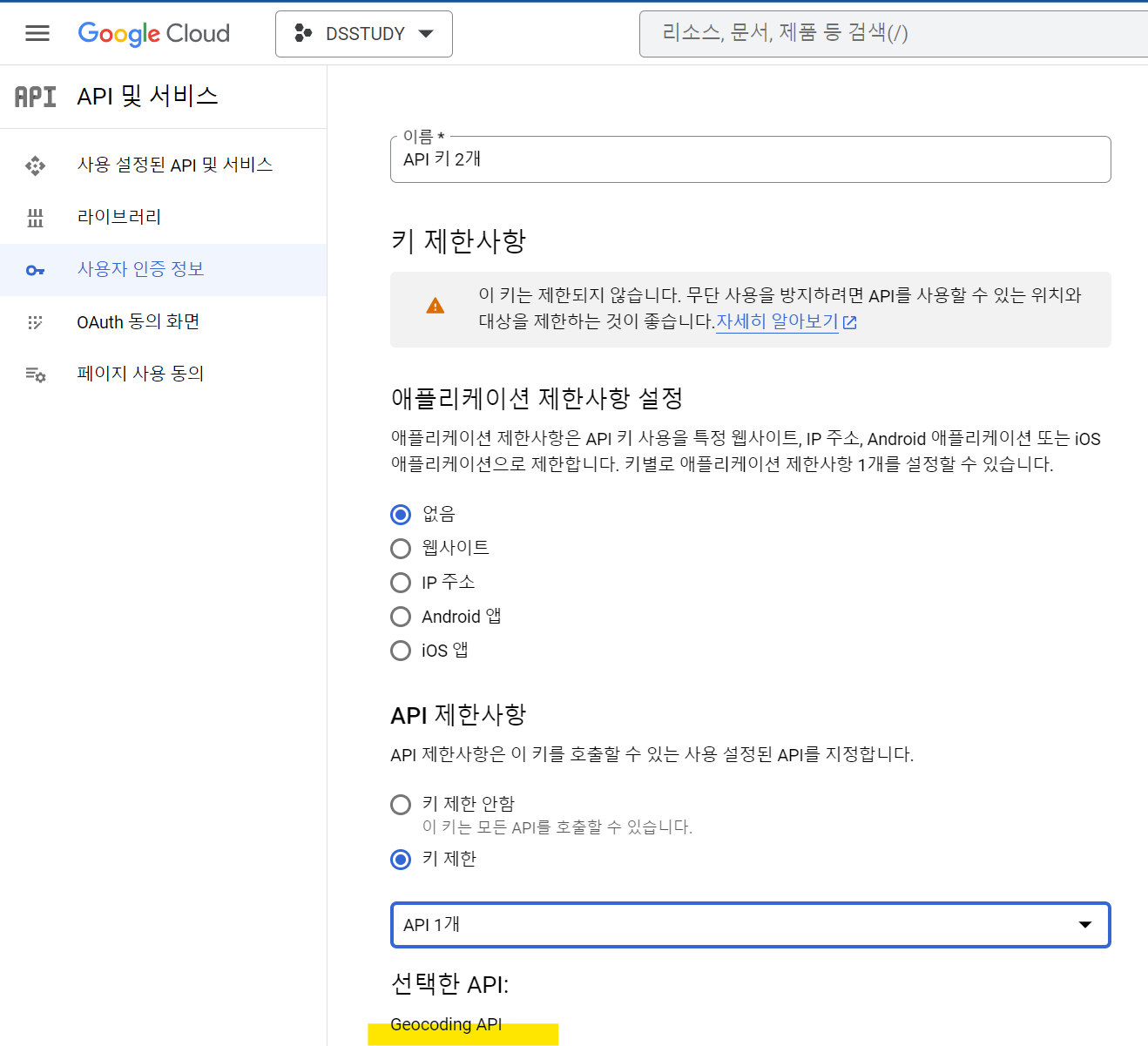
-
Geocoding API 를 선택해서 키제한 해주기
-
프롬프트 또는 주피터노트북에서 googlemaps 설치하기
pip install googlemaps -
정상적으로 잘 작동하는지 확인하기
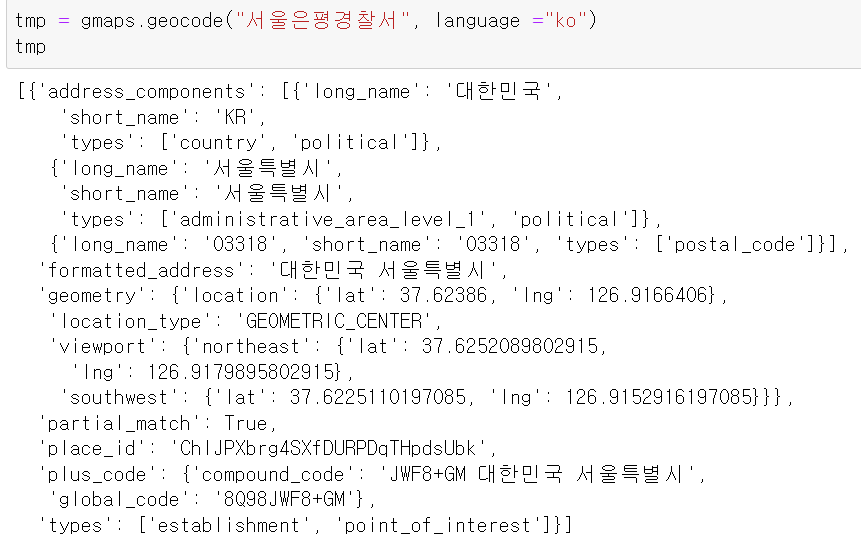
import googlemaps gmaps_key = "본인 API KEY" gmaps = googlemaps.Client(key = gmaps_key) gmaps.geocode("서울영등포경찰서", language = "ko")
Google Maps를 이용한 데이터 정리
위 코드를 실행해서 살펴보면 <전체 결과 크기가 1인 리스트형>이 출력됨.
큰 리스트 안에는 딕셔너리형태로 구분 지어진 데이터들을 볼 수 있는데,
우리가 필요한 데이터를 get명령어를 통해 얻어볼 수 있음.
구 이름을 얻어보고, 위도 경도 정보까지 저장된 데이터프레임을 만들어보자.
tmp[0].get("formatted_address").split()[2] #구 이름에 접근
tmp[0].get("geometry")["location"]["lat"] # 위도 데이터에 접근
tmp[0].get("geometry")["location"]["lng"] # 경도 데이터에 접근# 컬럼 만들어주기
crime_station["구별"] = np.nan
crime_station["lat"] = np.nan
crime_station["lng"] = np.nan
'''
- 경찰서 이름에서 소속된 구 이름 얻기
- 구 이름과 위도, 경도 정보를 저장
- 반복문을 이용해 위 표의 Nan을 모두 채워주자(iterrosw() 이용)
'''
count = 0 #작업이 잘 진행되고 있는지 확인하기 위한 변구
for idx, rows in crime_station.iterrows(): #idx : 인덱스(현재 경찰서 이름)
station_name = "서울" + str(idx) + "경찰서"
# 위 예시에서 gmaps.geocode("서울영등포경찰서", language ="ko") 와 같이 접근한 것 처럼
# 데이터 프레임의 idx를 "서울idx경찰서" 로 만들어줌 -> print(station_name)을 통해 잘 변환된 것을 확인 가능
tmp = gmaps.geocode(station_name, language ="ko")
if count == 25: # (26번째 행 서울은평경찰서만 주소가 ~서울특별시에서 끝나 구 이름이 출력이 안 됨.)
tmp_gu = "은평구"
else:
tmp_gu = tmp[0].get("formatted_address").split()[2]
lat = tmp[0].get("geometry")["location"]["lat"]
lng = tmp[0].get("geometry")["location"]["lng"]
# 컬럼 채워주기
crime_station.loc[idx, "구별"] = tmp_gu
crime_station.loc[idx, "lat"] = lat
crime_station.loc[idx, "lng"] = lng
#작업이 잘 진행되고 있는지 확인하기 위함
print(count) # 30까지 출력되면 진행이 다 된 것임!
count += 126번째 행에 있는 "서울은평경찰서"는 주소가 제대로 출력이 안되어서 직접 추가해줌.
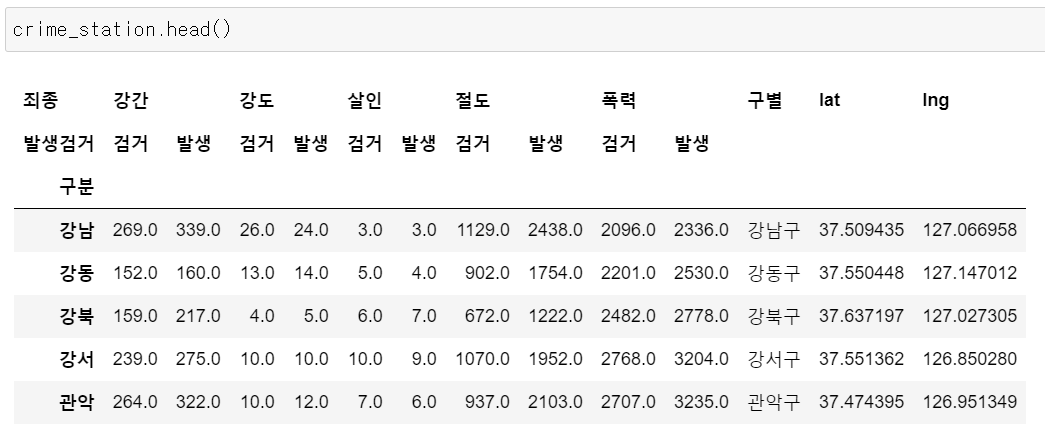
지금까지의 데이터프레임
컬럼에 레벨이 생기면서 표가 복잡한 것을 볼 수 있음
crime_station.columns.get_level_values을 보면 레벨에 따른 컬럼명들을 확인할 수 있는데
crime_station.columns.get_level_values(0)[2] + crime_station.columns.get_level_values(1)[2] #str 타입이라 + 문자열로 붙일 수 있음위 코드를 통해 레벨이 다른 컬럼을 합칠 수 있음.
tmp = [
crime_station.columns.get_level_values(0)[n] + crime_station.columns.get_level_values(1)[n]
for n in range(0, len(crime_station.columns.get_level_values(0)))
]
# 컬럼명 변경
crime_station.columns = tmp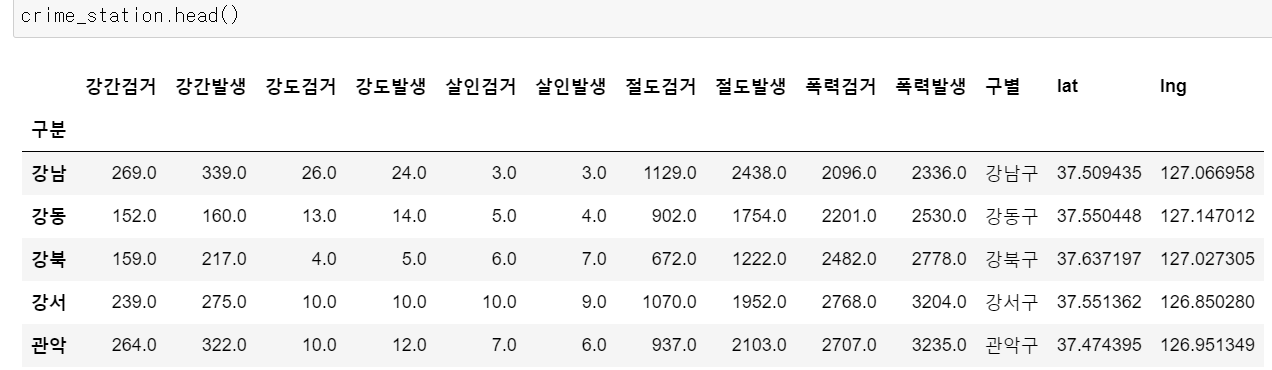
구별 데이터 얻기
서울은 한 구에 경찰서가 두 곳인 구가 있으므로 구 이름으로 정렬해야할 필요가 있음.
인덱스가 구 이름인 데이터 프레임을 만들고, 검거율 컬럼을 추가해보자.
crime_anal_gu = pd.pivot_table(crime_anal_station,
index = "구별",
aggfunc = np.sum
)
# 지금 데이터 프레임엔 위도, 경도가 필요없으므로 삭제(열을 삭제하는 방법 2가지)
del crime_anal_gu["lat"]
crime_anal_gu.drop("lng", axis = 1, inplace = True)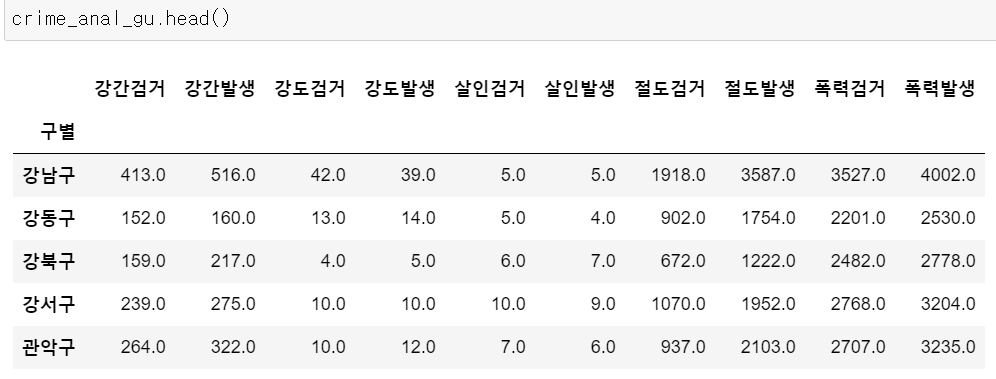
- 다수의 컬럼을 다수의 컬럼으로 나누고 싶은 경우
target = ["강간검거율", "강도검거율", "살인검거율", "절도검거율" , "폭력검거율"]
num = ["강간검거", "강도검거", "살인검거", "절도검거" , "폭력검거"]
den = ["강간발생", "강도발생", "살인발생", "절도발생" , "폭력발생"]
crime_anal_gu[target] = crime_anal_gu[num].div(crime_anal_gu[den].values) * 100
crime_anal_gu.head()- 검거율이 100이 넘는다?
-> 발생 연도와 검거 연도가 구분 짓지 않은 데이터라 단순 계산 상으로 검거율이 100이 넘을 수도 있다.
-> 이후 heatmap 작업에서의 문제가 될 수도 있으니 100 이상의 수치를 100으로 맞춰주자.
# 100보다 큰 숫자 찾아서 바꾸기
crime_anal_gu[crime_anal_gu[target] > 100] = 100
# 컬럼 이름 변경
crime_anal_gu.rename(columns = {"강간발생" : "강간",
"강도발생" : "강도",
"살인발생" : "살인",
"절도발생" : "절도",
"폭력발생" : "폭력"}, inplace = True)
crime_anal_gu.head()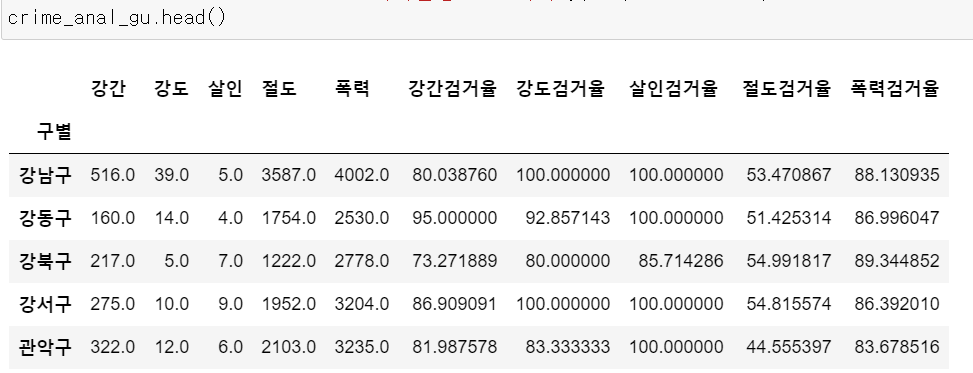
범죄 데이터 정렬을 위한 데이터 정리
범죄의 경중에 따라 발생 건수의 차이가 발생된 것 같음. 자릿수를 맞춰주자.
범죄 발생 건수 컬럼들을 정규화 시킨 데이터프레임을 만들어보자.
col = ["강간", "강도", "살인", "절도", "폭력"]
crime_anal_gu_norm = crime_anal_gu[col] / crime_anal_gu[col].max()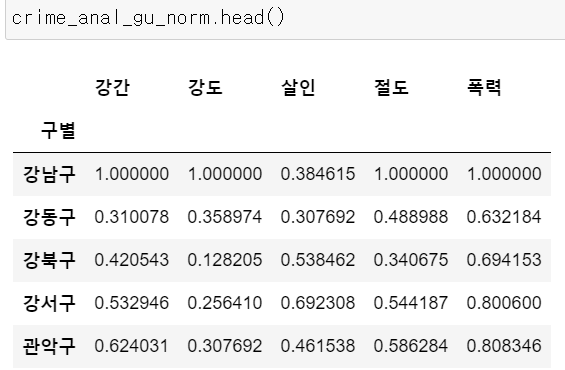
구별 CCTV 자료에서 인구수와 CCTV 수 컬럼을 가져와 범죄 발생 건수 및 검거율 데이터프레임에 붙여보자.
# 검거율 추가
col2 = ["강간검거율", "강도검거율", "살인검거율", "절도검거율", "폭력검거율"]
crime_anal_gu_norm[col2] = crime_anal_gu[col2]
# 구별 CCTV 자료에서 인구수와 CCTV 수 추가
result_CCTV = pd.read_csv("../data/01. CCTV_result.csv", index_col = "구별", encoding = "utf-8")
crime_anal_gu_norm[["인구수", "CCTV"]] = result_CCTV[["인구수", "소계"]]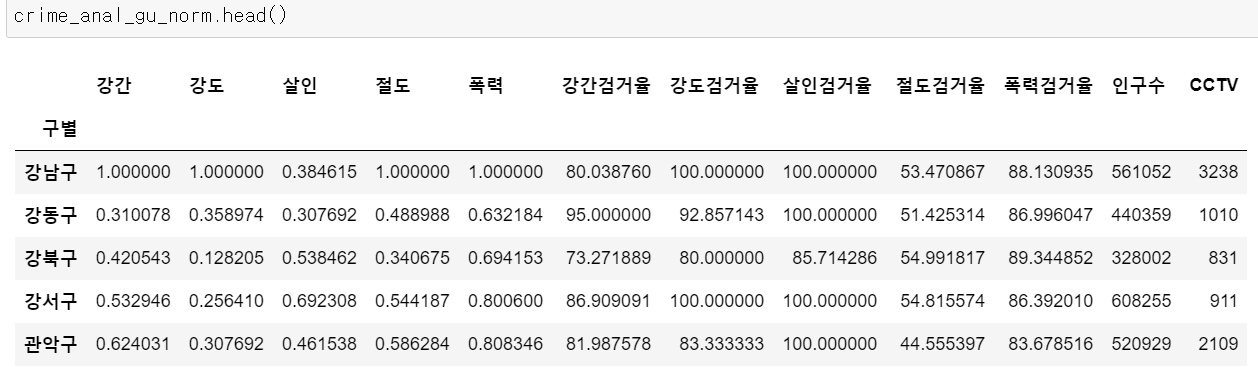
정규화된 범죄발생 건수 전체의 평균을 구해 범죄의 대표값으로 사용하고 검거율의 평균을 구해 검거의 대표값으로 사용해보면서, 우리 프로젝트의 목적인 강남 3구가 범죄로부터 안전한지 살펴보자.
# 정규화된 범죄발생 건수 전체의 평균을 구해서 범죄 컬럼 대표값으로 사용
col = ["강간", "강도", "살인", "절도", "폭력"]
crime_anal_gu_norm["범죄"] = np.mean(crime_anal_gu_norm[col], axis = 1)
# 검거율의 평균을 구해서 검거 컬럼의 대표값으로 사용
col = ["강간검거율", "강도검거율", "살인검거율", "절도검거율", "폭력검거율"]
crime_anal_gu_norm["검거"] = np.mean(crime_anal_gu_norm[col], axis = 1)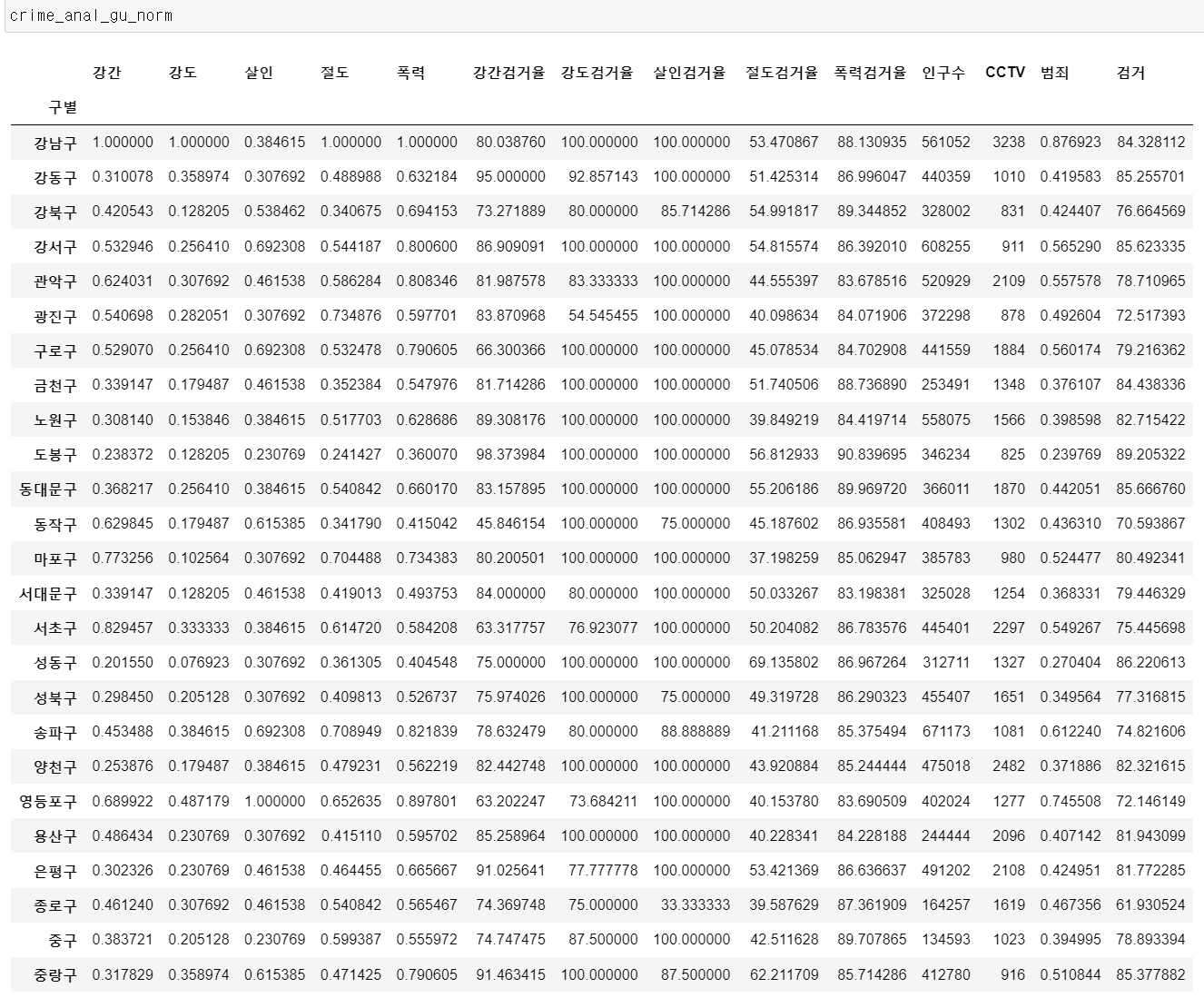

이런 유용한 정보를 나눠주셔서 감사합니다.