
✍🏻 7일 공부 이야기.
👀 오늘 공부한 내용의 자세한 코드는 아래 깃허브에 올라와 있습니다:)
https://github.com/nabi4442/ZeroBaseDataSchool/blob/main/03.%20Web%20Data(%20~%2050%25%20).ipynb
웹 데이터 수집하고 정리하기
HTML 기초
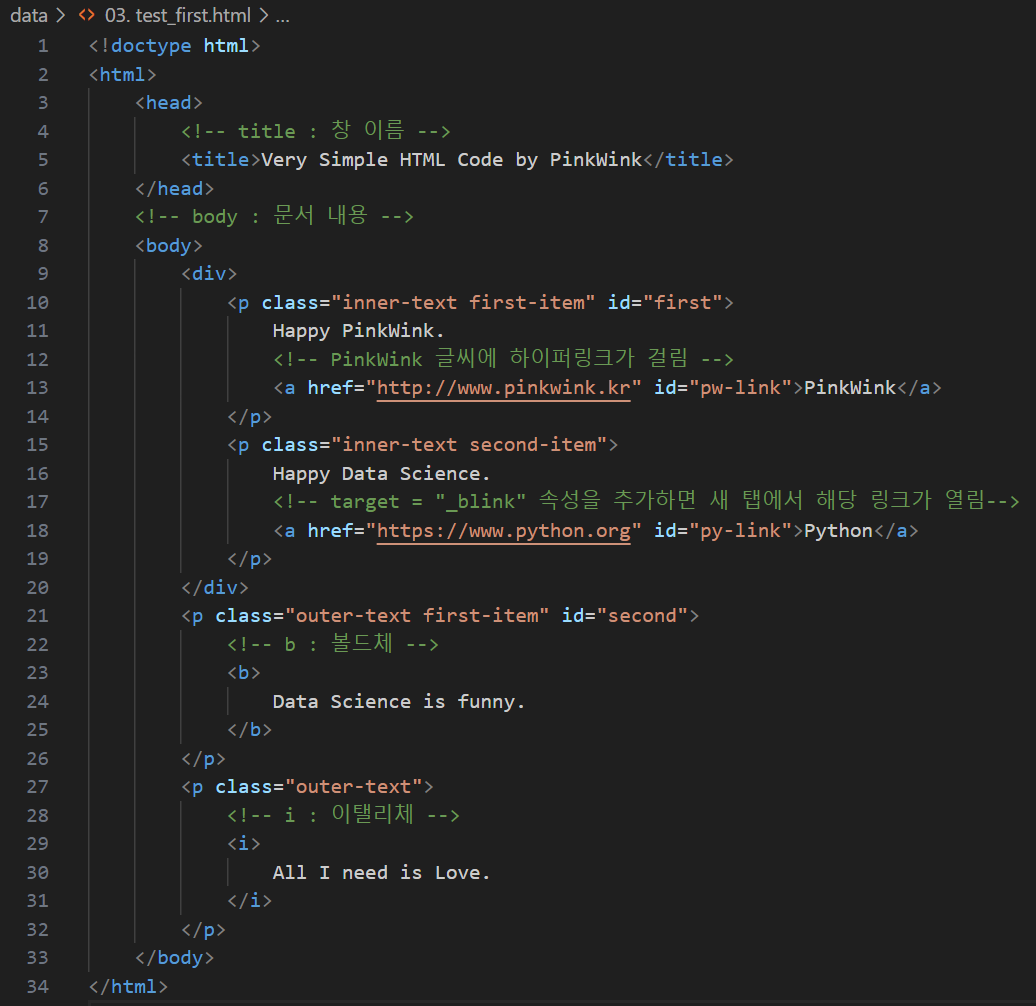
html 태그는 웹 페이지를 표현
head 태그는 눈에 보이진 않지만 문서에 필요한 헤더 정보 보관
body 태그에는 눈에 보이는 정보 보관
p 태그는 문단을 의미
Beautiful Soup for web data
태그로 되어있는 문서를 읽는 기능 Beautiful Soup
예제로 file:///c%3A/Users/nabi4/OneDrive/%EB%AC%B8%EC%84%9C/ds_study/data/03.%20test_first.html 문서를 읽어보자.
pip install beautifulsoup4
from bs4 import BeautifulSoup- 파일로 저장된 html 파일을 읽을 때
page = open("파일경로/파일명.html", "r").read() soup = BeautifulSoup(page, "html.parser") print(soup.prettify())
open: 파일명을 읽어줘야함.html.parser: BeautifulSoup 의 html을 읽는 엔진 중 하나 (📄 parser 관련 공식 문서)prettify(): html 출력을 이쁘게 만들어주는 기능
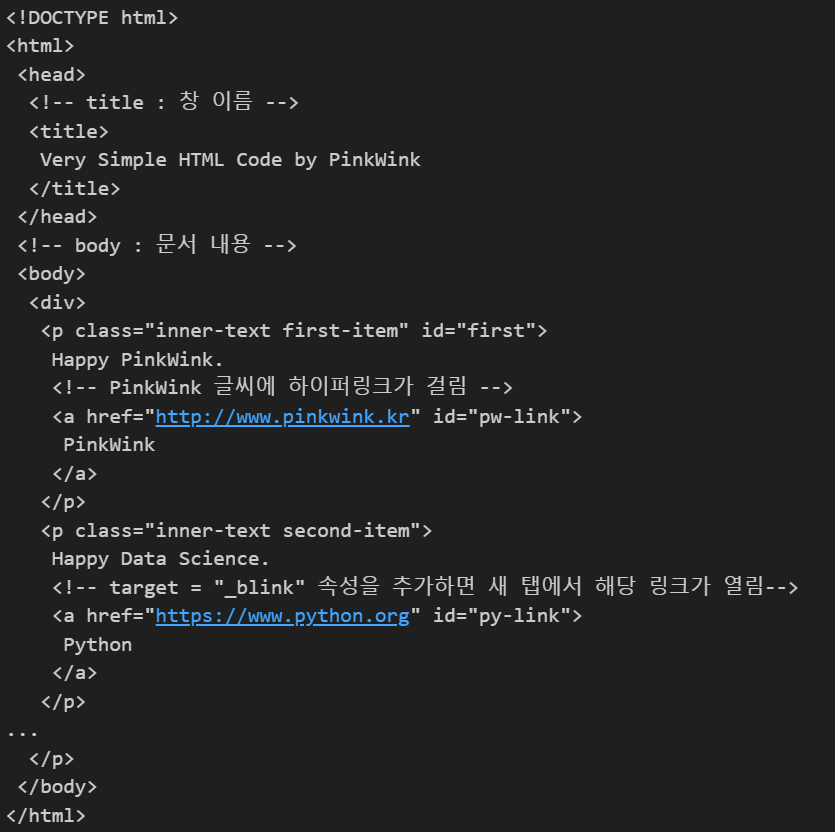
soup.찾고싶은 태그이름: 제일 앞에 위치한 해당 태그 안의 내용을 보여줌soup.find("찾고싶은 태그이름"): 제일 앞에 위치한 해당 태그의 내용을 찾아 보여줌soup.find_all("찾고싶은 태그이름"): 해당 태그의 모든 내용을 찾아 리스트형 데이터로 보여줌- 태그 안의 내용을 찾는 방법
1. 변수명을 생략하고 써주는 경우
soup.find_all("찾고싶은 태그이름" , "클래스 이름 또는 아이디 이름")
2. 변수명을 써주는 경우
soup.find_all("찾고싶은 태그이름" , class_="클래스 이름")
soup.find_all("찾고싶은 태그이름" , id = "아이디 이름")
3. 딕셔너리 형태로 써주는 경우
soup.find("찾고싶은 태그이름", {"class" : "클래스이름", "id" : "아이디이름"}) - 태그로 싸여져있는 텍스트를 추출하는 방법
1.get._text()
2.text.strip() - 리스트로 출력된 내부 텍스트를 출력하는 방법
1..text
2..string
3..get_text()
# 리스트 안에 있기 때문에 인덱스를 활용하여 텍스트를 추출할 수 있음
# .text
# .string
# .get_text()
soup.find_all(id = "pw-link")[0].text- 외부로 연결되는 링크의 주소를 알아내는 방법
# <a href> 태그 안에 링크가 저장되어 있음
# href 속성을 가져오는 2가지 방법
# print(links[0].get("href"))
# print(links[1]["href"])
links = soup.find_all("a")
for each in links:
href = each.get("href") #each["href"]
text = each.get_text()
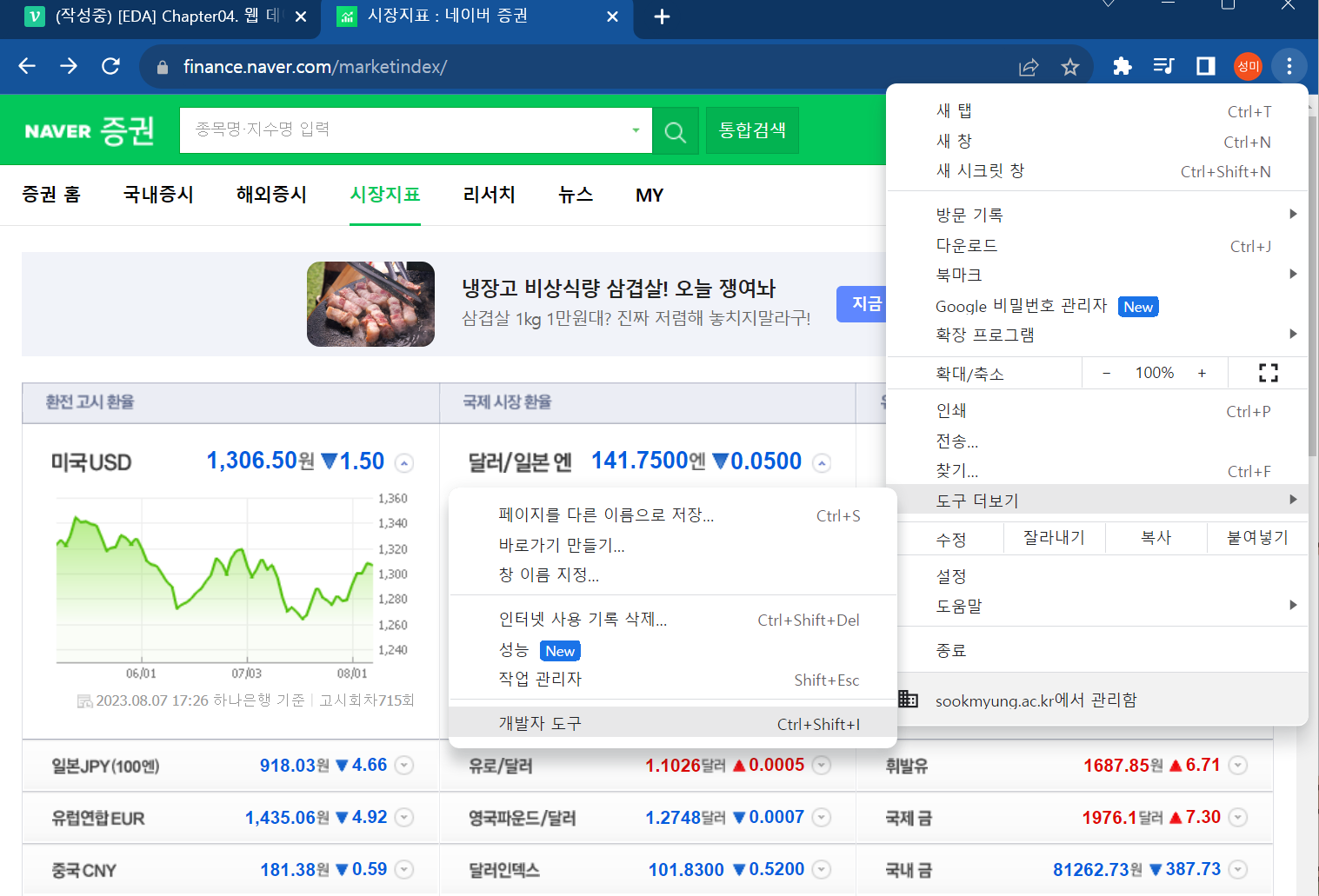
print(text + " => " + href)크롬 개발자 도구
크롬 설정 - 도구 더보기 - 개발자도구 (화면 오른쪽부터 선택)
단축키 : Ctrl + Shift + I
환율 정보 가져오기
https://finance.naver.com/marketindex/
환율 정보를 가져와보자.
- 국가 이름
- 환율
- 변동
- 하락/상승
- 해당 국가 지표 링크
pip install requests
import requests #from urlib.request.Request와 같은 기능find 대신 requests 방식도 써보자!
두 명령어는 같은 기능을 수행해주는데, 사용자마다 본인에게 맞는 명령어를 사용하는 추세이다.
구글에 find_all select를 검색해봐도 차이점과 장단점을 많이 볼 수 있다!
import requests
from bs4 import BeautifulSoup
url = "https://finance.naver.com/marketindex/"
response = requests.get(url) #get방식, post 방식
soup = BeautifulSoup(response.text, "html.parser")
# soup.find_all ("li", "on")
# id => #
# class => .
# id는 고유한 값이기 때문에 다른 것들에 비해 많이 사용됨
exchangeList = soup.select("#exchangeList > li") #id가 exchangeList 인 li 태그
'''
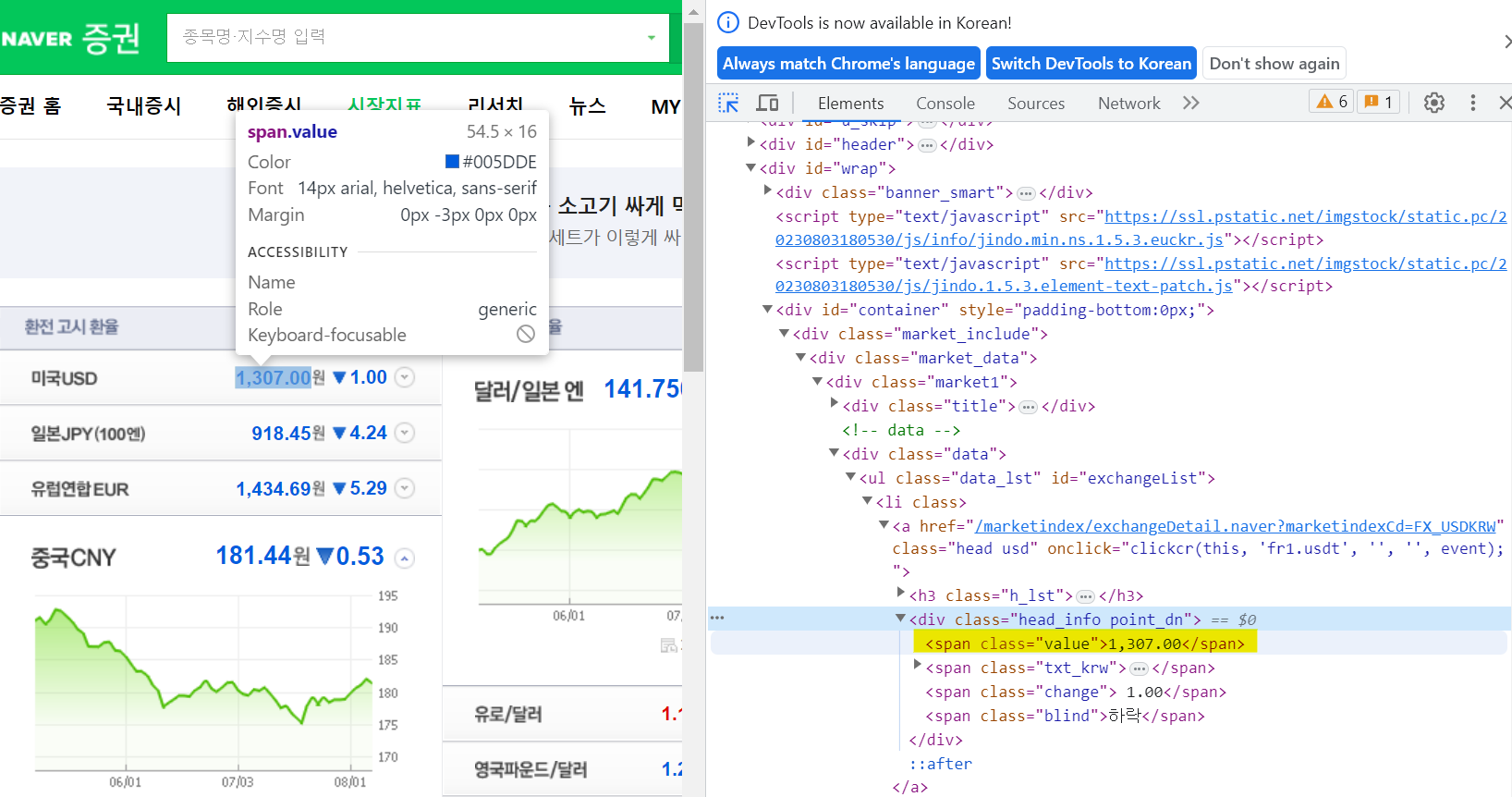
개발자도구의 클래스, 아이디 이름을 보면서 미국에 대한 환율 정보를 출력하면 아래와 같다.
title = exchangeList[0].select_one(".h_lst").text
exchange = exchangeList[0].select_one(".value").text
change = exchangeList[0].select_one(".change").text
# head_info point_dn 와 같이 표시된 것은 속성값이 head_info와 point_dn으로 나뉘어져있는 것으로
# 속성값이 2개임을 표시해주어야 한다.
# 그래서 div 태그 밑의 .head_info.point_dn 클래스를 가져와라 라고 표시한 것이다.
# div.head_info.point_dn.blind 을 하게되면 처음으로 만나는 blind가 있어서 다른 값이 나오는데
# div.head_info.point_dn 바로 하위 속성의 blind를 추출하라는 뜻으로 > 을 작성해준다.
# div 태그임을 생략해줘도 됨
# select는 하위 속성값들을 한번에 표시할 수 있다는 장점이 있음
updown = exchangeList[0].select_one("div.head_info.point_dn > .blind").text
# exchangeList[0].select_one("a").get("href") 만 하면
# 앞에 링크 주소가 짤려 나오기 때문에 페이지를 열 수 없다.
# 링크를 연결해주는 기능도 있지만,
# 아래와 같이 연결해줄 수도 있다.
baseUrl = "https://finance.naver.com"
link = baseUrl + exchangeList[0].select_one("a").get("href")
위 코드를 이용해 모든 국가의 환율 정보를 출력해보자.
'''
exchange_datas = []
baseUrl = "https://finance.naver.com"
for item in exchangeList:
data = {
"title" : item.select_one(".h_lst").text,
"exchange" : item.select_one(".value").text,
"change" : item.select_one(".change").text,
"updown" : item.select_one("div.head_info.point_dn > .blind").text,
"link" : baseUrl + item.select_one("a").get("href")
}
exchange_datas.append(data)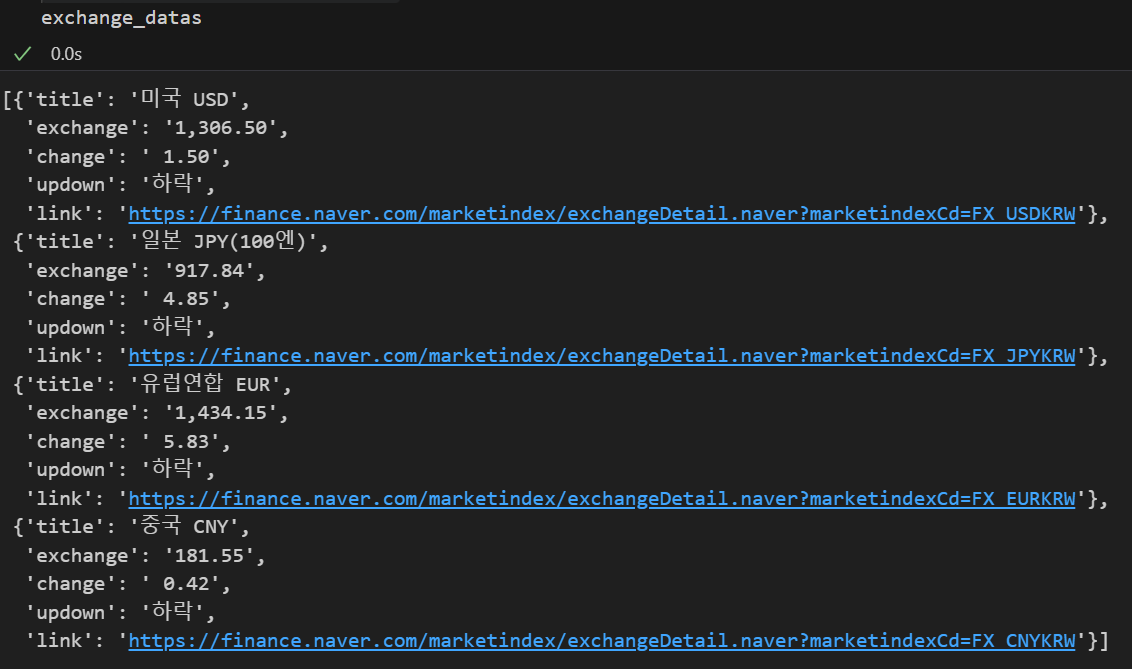
# 크롤링한 데이터를 엑셀 파일로 저장할 수 있다.
import pandas as pd
df = pd.DataFrame(exchange_datas)
df.to_excel("./naverfinance.xlsx", encoding = "utf-8")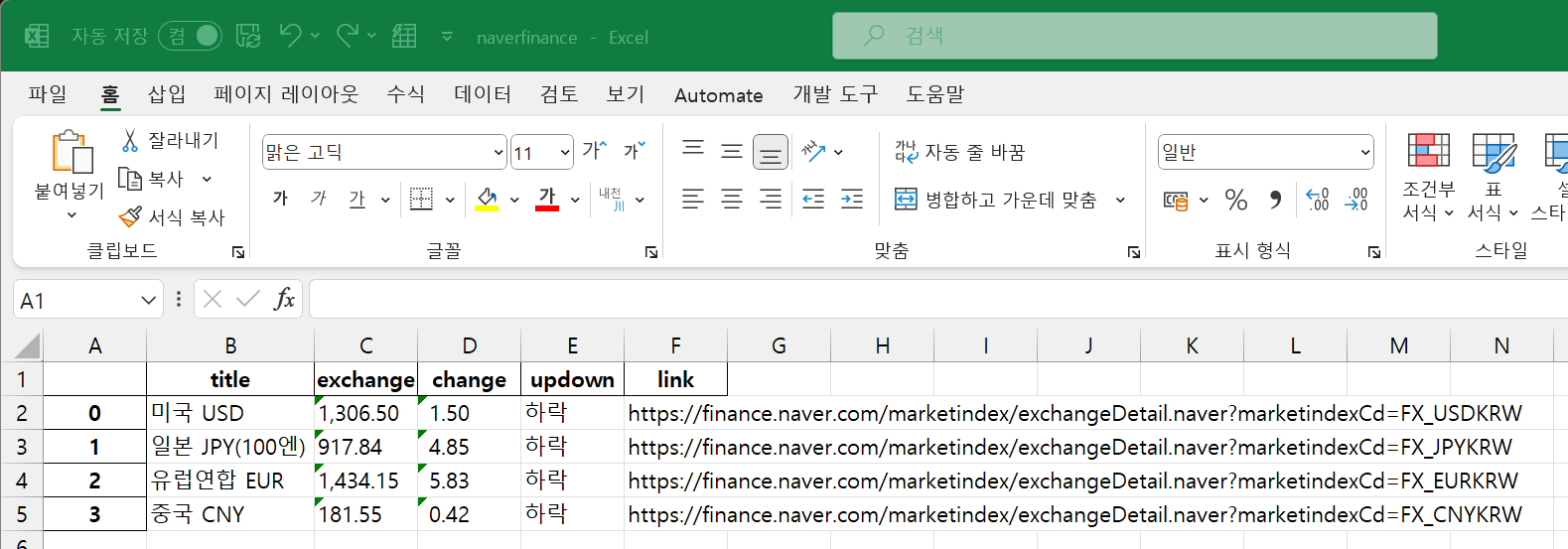
위키백과 데이터 가져오기
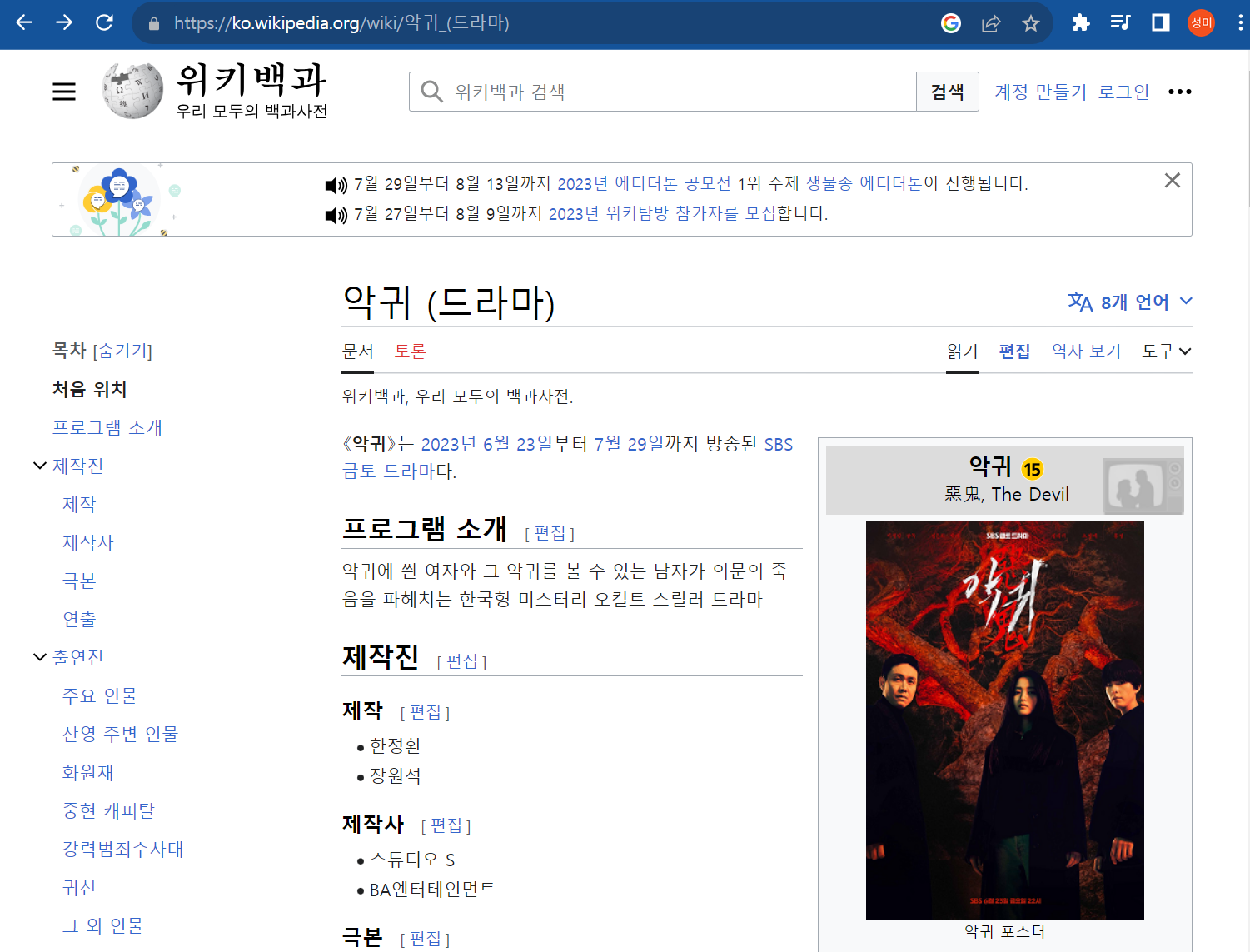
👀 이 예제에서 눈여겨 볼 것은 URL 링크가 한글로 이루어졌다는 것이다.

보시다시피 뒤에 한글로 되어있는 것을 볼 수 있는데, 위 링크를 복사 붙여넣기 해보면
https://ko.wikipedia.org/wiki/%EC%95%85%EA%B7%80_(%EB%93%9C%EB%9D%BC%EB%A7%88)
위와 같이 이상한 문자로 변환되어 있는 것을 볼 수 있다.
이를 해결하기 위해선 아래를 중점적으로 코드를 봐주면 좋을 것 같다:)
- 문자열 변수에서 {}로 쌓여져있는 것은 변수이다.
parse.quote("한글문자열")한글문자열을 utf-8로 인코딩해준다.
출연진, 주요 인물 이름을 가져와보자.
# 한글로 되어있는 URL을 복사 붙여넣기하면
# https://ko.wikipedia.org/wiki/%EC%95%85%EA%B7%80_(%EB%93%9C%EB%9D%BC%EB%A7%88)
# 위와 같이 깨지는 것을 볼 수 있다.
# 이런 경우에는
# URL을 decode해주는 https://www.urldecoder.org/
# 위와 같은 홈페이지에 들어가
# https://ko.wikipedia.org/wiki/악귀_(드라마)
# decode된 url 주소를 얻거나
# 아래와 같이 포매팅을 해주어야함.
import urllib
from urllib.request import urlopen, Request
html = "https://ko.wikipedia.org/wiki/{search_words}"
req = Request(html.format(search_words = urllib.parse.quote("악귀_(드라마)"))) #글자를 url로 인코딩
response = urlopen(req)
soup = BeautifulSoup(response, "html.parser")
#print(soup.prettify())
'''
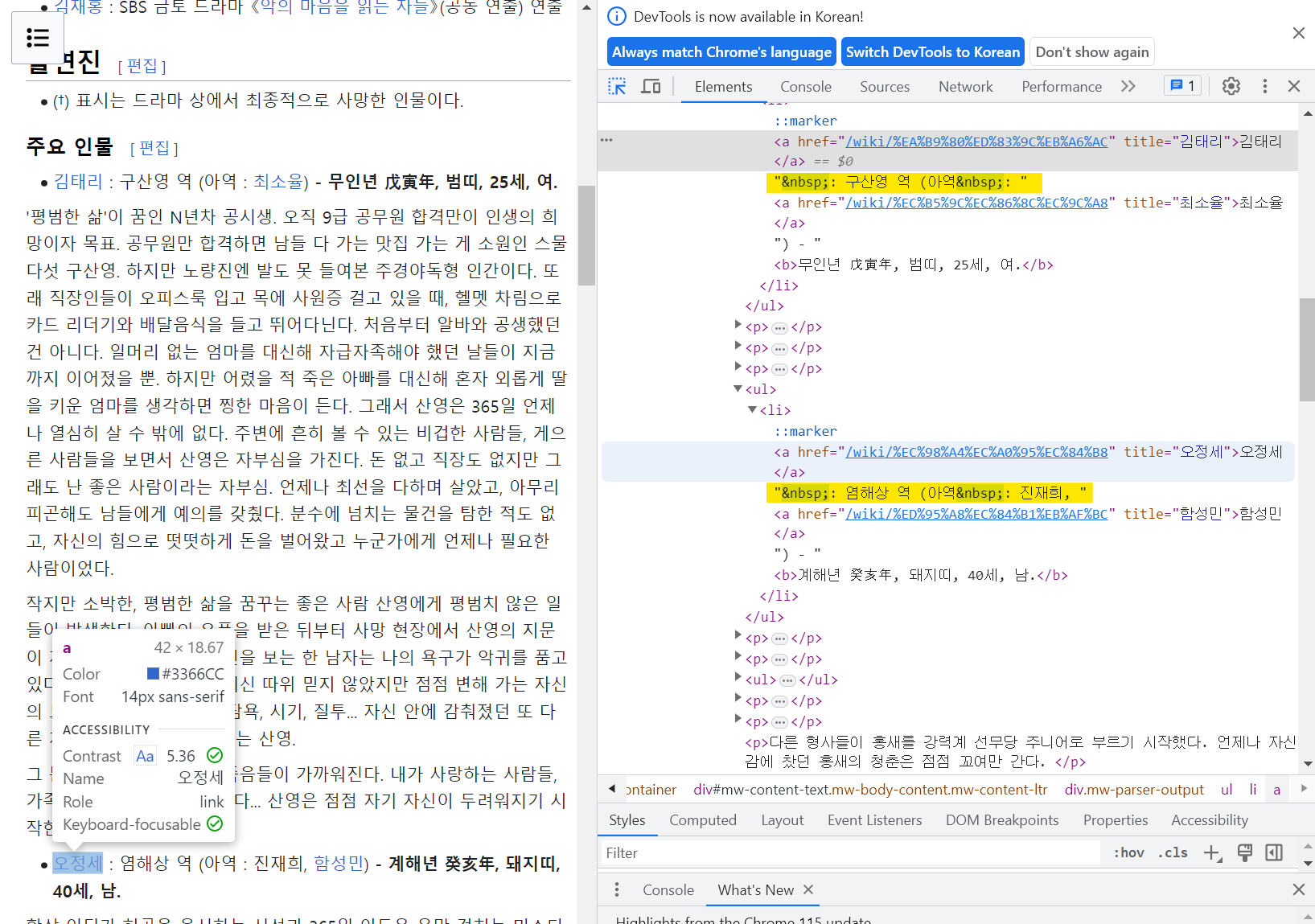
# 개발자도구에서 주인공 이름이 나오는 곳 찾기
soup.find_all("li")[72]
<li><a href="/wiki/%EA%B9%80%ED%83%9C%EB%A6%AC" title="김태리">김태리</a> : 구산영 역 (아역 : <a href="/wiki/%EC%B5%9C%EC%86%8C%EC%9C%A8" title="최소율">최소율</a>) - <b>무인년 戊寅年, 범띠, 25세, 여.</b></li>
위와 같이 출력됨
# 이름 추출
# 공백을 구분자로 문자열을 나눈후
# 첫번째 문자열을 가져옴
soup.find_all("li")[72].text.strip().replace("\xa0", " ").split()[0]
'김태리'
'''
for idx in range(72, 75):
print(soup.find_all("li")[idx].text.strip().replace("\xa0", " ").split()[0])💻 출력
김태리
오정세
홍경
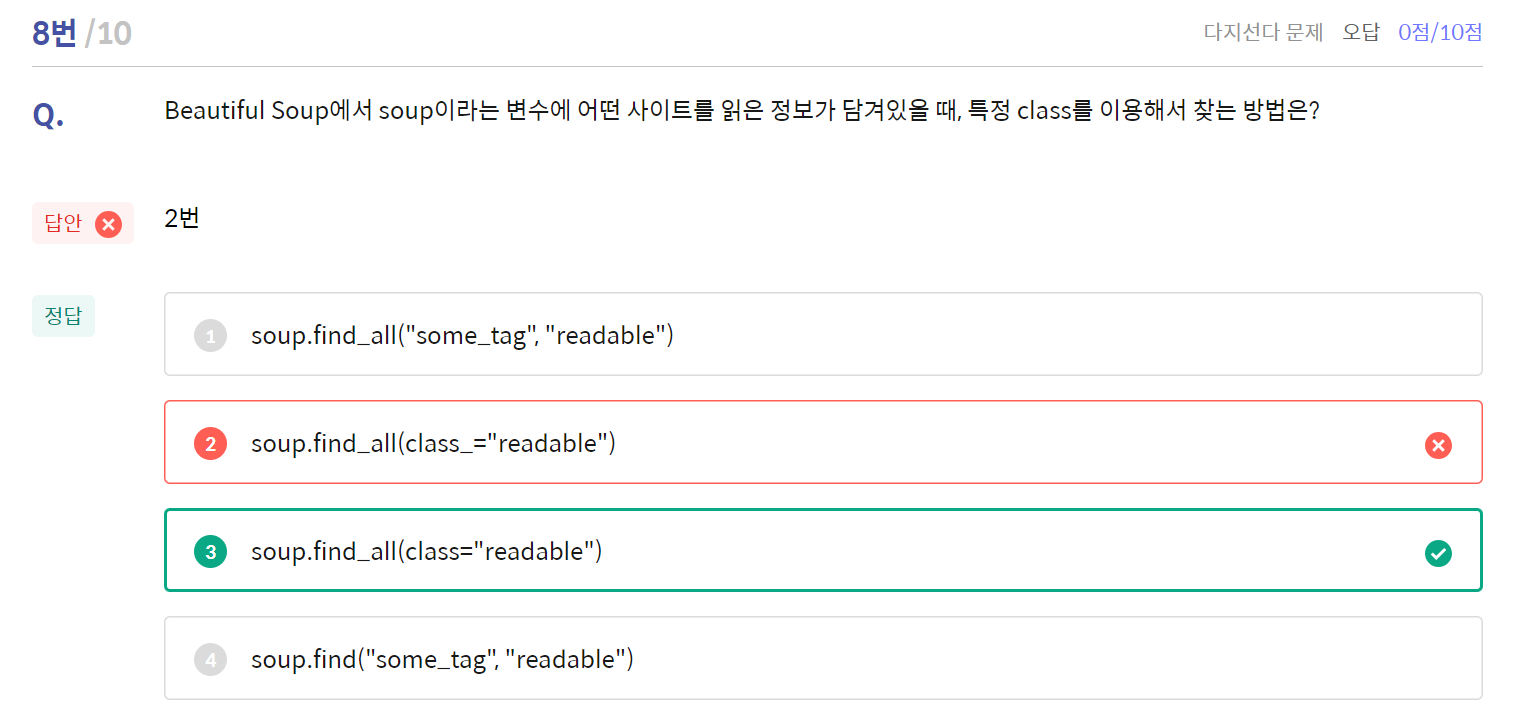
오늘 본 퀴즈 중 한 문제다..
아무리봐도 class 만 쓰면 오류인데.. class_로 써야된다고 배웠는데..
다른 코드들도 어떻게 보면 태그가 포함되어있긴 하지만, 특정 class를 이용하는 것도 맞아서 혹시나 문제가 ~ 찾는 방법이 아닌 것은? 이여서 답이 3번인가 싶어 여쭤봤는데 문제에 이상이 없단다..🤯
도대체 나는 어디서 또 혼자서 헤매고 있는고지..?ㅋㅋㅋㅋㅋ
(08.12. 내용 추가)
8월 7일에 교수님께 여쭤보기 시작해서.. 이제야 이 문제가 풀렸다..😂🤯 아직 퀴즈 제출 기한이 남아서 슬랙에는 자세한 답변 얘기를 할 수가 없었다. 그래서 직접적으로 'class_'가 아니라 왜 'class'가 정답이냐..!고 여쭤보지 못하고 빙빙 둘러 물어볼 수 밖에 없었다.
며칠에 걸쳐서 여쭤봤었는데 교수님과 내가 말하고 있는 방향성(?)이 다른 것 같아 결국 다이렉트 메세지로 여쭤보게 되었다.
위 캡쳐를 보내드렸더니 일이 한 방에 해결되어따...!!🥲
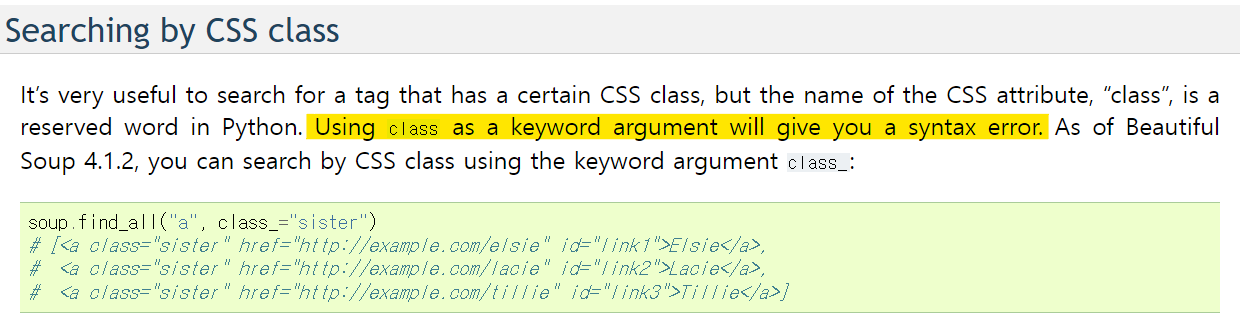
(정말 위 문제 때문에 공식 문서를 얼마나 찾아봤는지 모르겠다..ㅠㅠ class를 쓰면 syntax error가 뜬다!!!)
교수님의 답변으론 정답은 2번이 맞고
<~ 찾는 방법이 아닌 것은?>이라는 문제였다면 3번이 정답이겠지만, 1, 4번이 클래스만 이용해서 찾는 것은 아니기에 이 또한 애매해질 수 있기 때문에 2번을 정답으로 수정하는 것으로 해결되었다 :)
※ 그렇다면.. 문제를 <특정 class만 이용해서 찾는 방법은?>으로 고치는게 더 오해의 소지가 없을 것 같다!
