
✍🏻 31일, 1일 공부 이야기
👀 공부한 자세한 내용의 코드는 아래 깃허브에 올라가있습니다!!
https://github.com/nabi4442/ZeroBaseDataSchool/tree/main/EDA%20%EA%B8%B0%EC%B4%88%20%EB%8B%A4%EC%A7%80%EA%B8%B0
데이터 병합하고 정리하기
📄 01. Analysis Seoul CCTV.ipynb 파일 참고
데이터 병합
- pd.concat()
- pd.merge()
- pd.join()
우리는 pd.merge()를 이용해볼 것!!
pd.merge()
pd.merge(데이터프레임1, 데이터프레임2, on = "키값")
- 두 데이터 프레임에서 컬럼이나 인덱스를 기준으로 잡고 병합하는 방법
- 기준이 되는 컬럼이나 인덱스를 키값이라 함
- 키값은 두 데이터 프레임에 모두 포함되어 있어야 함
- 📄 공식 문서
##데이터 만드는 방법
##1. 딕셔너리 안에 리스트 형태
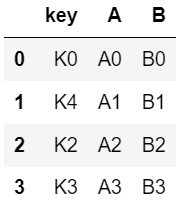
left = pd.DataFrame({
"key" : ["K0" ,"K4" ,"K2" ,"K3"],
"A" : ["A0" ,"A1" ,"A2" ,"A3"],
"B" : ["B0" ,"B1" ,"B2" ,"B3"]
})
##2. 리스트 안에 딕셔너리 형태
right = pd.DataFrame([
{"key" : "K0" , "C" : "C0", "D" : "D0"},
{"key" : "K1" , "C" : "C1", "D" : "D1"},
{"key" : "K2" , "C" : "C2", "D" : "D2"},
{"key" : "K3" , "C" : "C3", "D" : "D3"}
]) left left | 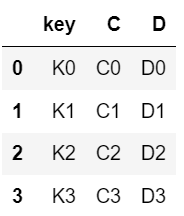 right right |
|---|
pd.merge(left, right, on = "key") #key를 기준으로 잡고 병합. 공통된 부분만 추출됨
#디폴트 값으로 how = "inner"가 되어있음(두 데이터 프레임의 공통된 부분만 출력)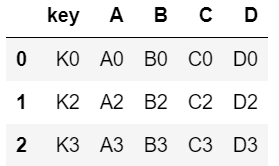
how 옵션
pd.merge(left, right, how = "left", on = "key")
#key를 기준으로 병합하되, left 데이터프레임의 키를 기준으로 하라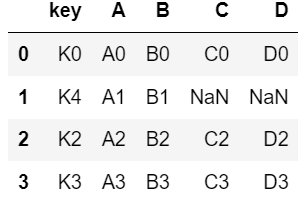
pd.merge(left, right, how = "right", on = "key")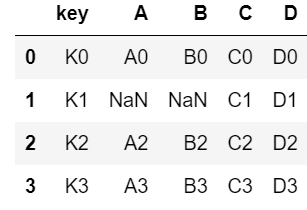
pd.merge(left, right, how = "outer", on = "key")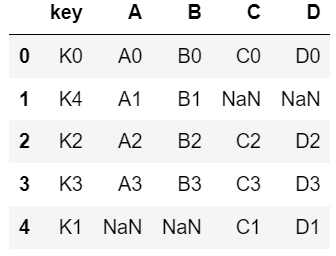
데이터 정리
데이터프레임 인덱스 변경
의미있는 라벨을 인덱스로 사용하여 원하는 행에 빠르제 접근하거나, 데이터프레임 병합과 같은 전처리를 쉽게 하기 위함.
데이터프레임명.set.index("컬럼명", inplace = True)
상관계수
데이터프레임 변수들 간의 상관계수를 살펴보면서 데이터 간의 패턴이나 특성을 파악하여 데이터의 인사이트를 도출할 수도 있고 전처리를 하기 위함.
👀 상관계수가 0.2 이상인 데이터를 비교해보자.
데이터프레임명.corr()
📌 숫자형 변수들끼리만 상관계수를 알아낼 수 있으므로, 만약 비교하고 싶은 변수가 문자형 데이터라면 숫자형으로 변환 후 상관계수를 알아볼 것!
데이터프레임명 = 데이터프레임명.astype({'컬럼명' : 'int'})
데이터프레임명.info() #데이터형이 바뀌었는지 확인 가능그래프 그리기
matplotlib
import matplotlib.pyplot as plt
from matplotlib import rc
rc("font", family = "Malgun Gothic")
get_ipython().run_line_magic("matplotlib", "inline") #주피터노트북에 그래프를 나타내기 위함
#https://m.blog.naver.com/kiddwannabe/221202864701
#그래프 마이너스가 깨져서 추가한 코드
plt.rcParams['axes.unicode_minus'] = False matplotlib 그래프 기본 형태
1. plt.figure(figsize = (가로 사이즈, 세로 사이즈))
2. plt.plot(x,y)
3. plt.show()
👀 그래프 그리는 코드를 함수 형태로 만들어두면 사용이 편하다!
📄 matplotlib.pyplot 공식 문서
📄 matplotlib 예제들
import numpy as np
t = np.arange(0,12,0.01)
y = np.sin(t)
def drawGraph():
plt.figure(figsize = (10,6))
plt.plot(t, np.sin(t))
plt.plot(t, np.cos(t))
plt.grid(True) #1. 격자무늬 추가
plt.title("Example of sinwave") #2. 그래프 제목 추가
plt.xlabel("time") #3. x축, y축 제목 추가
plt.ylabel("Amitude")
plt.legend(labels = ["sin", "cos"]) #4. 주황색 파란색 선 데이터 의미 구분
'''
plt.plot(t, np.sin(t), label = "sin")
plt.plot(t, np.cos(t), label = "cos")
이라 썼다면
plt.legend() 로도 범례 생성 가능
loc 옵션을 설정하여 범례 위치를 설정할 수 있음
'''
plt.show()
drawGraph()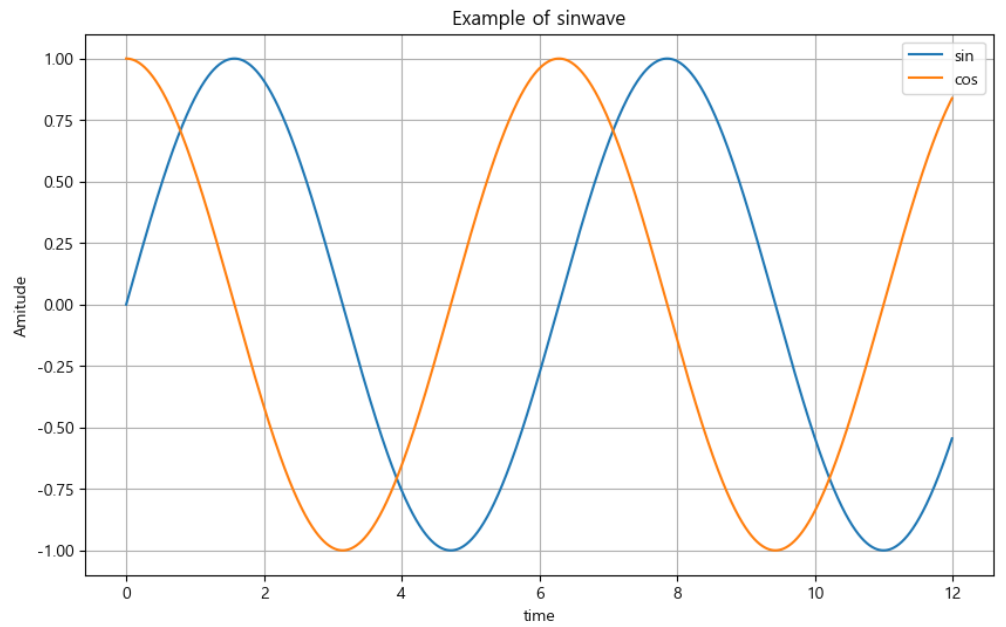
Pandas pivot table
📄 02. Analysis Seoul Crime.ipynb 파일 참고
원하는대로 데이터프레임을 만들 수 있어 자주 사용함
- index 설정
데이터프레임명.pivot_table(index = "인덱스로 할 컬럼명")
# pd.pivot_table(데이터프레임명, index = "인덱스로 할 컬럼명") 또한 같은 작업을 실행해줌
## 멀티 인덱스로 설정하고 싶다면
## index = ["컬렴1", "컬렴2", "컬렴3"] 과 같이 리스트 형태로 만들어주면 됨.- value 설정
데이터프레임명.pivot_table(values = "원하는 값")- value에 함수를 적용하고 싶은 경우
데이터프레임명.pivot_table(values = "원하는 값" , aggfunc = 적용할 함수)
# 함수를 2개 이상 적용하고 싶다면 이 역시 리스트 형태로 넣어주기
# aggfunc = [함수1, 함수2]- columns 설정
데이터프레임명.pivot_table(columns = "컬럼으로 할 컬럼명")
# Nan이 생긴다면 이를 채워줄 옵션 설정 : fill_value
데이터프레임명.pivot_table(columns = "컬럼으로 할 컬럼명" , fill_value = 0) #Nan이 0으로 표시됨파이썬의 반복문
Pandas에 잘 맞춰진 반복문용 명령 iterrows()
- Pandas 데이터 프레임은 대부분 2차원인데, 이럴때 for문을 사용하면 n번째라는 지정을 반복해서 가독률이 떨어짐.
- 그래서 iterows() 옵션을 사용하면 편함!!
- 받을 때, 인덱스와 내용으로 나누어 받아야하는 것만 주의하기
Seaborn
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib import rc
# 그래프의 마이너스가 깨지지 않기 위함
plt.rcParams['axes.unicode_minus'] = False
# 한글이 깨지지 않기 위함
rc("font", family = "Malgun Gothic")
get_ipython().run_line_magic("matplotlib", "inline")- tips, flights 실습용 데이터가 공부하기 좋음!!
- background 타입 설정
sns.set_style("배경명")
#대표적으로 "white", "dark, "whitegrid", "darkgrid", "ticks"가 있다.- boxplot
📄 seaborn.boxplot 공식 문서
plt.figure(figsize = (가로 사이즈, 세로 사이즈))
sns.boxplot(
x = "x축으로 할 컬럼명",
y = "y축으로 할 컬럼명",
data = 데이터프레임명 ,
hue = "카테고리형 컬럼명" , #카테고리형 변수를 넣어주면 해당 변수 값의 색상을 달리하여 그래프를 그려줌
palette = "색상코드명"
)
plt.show()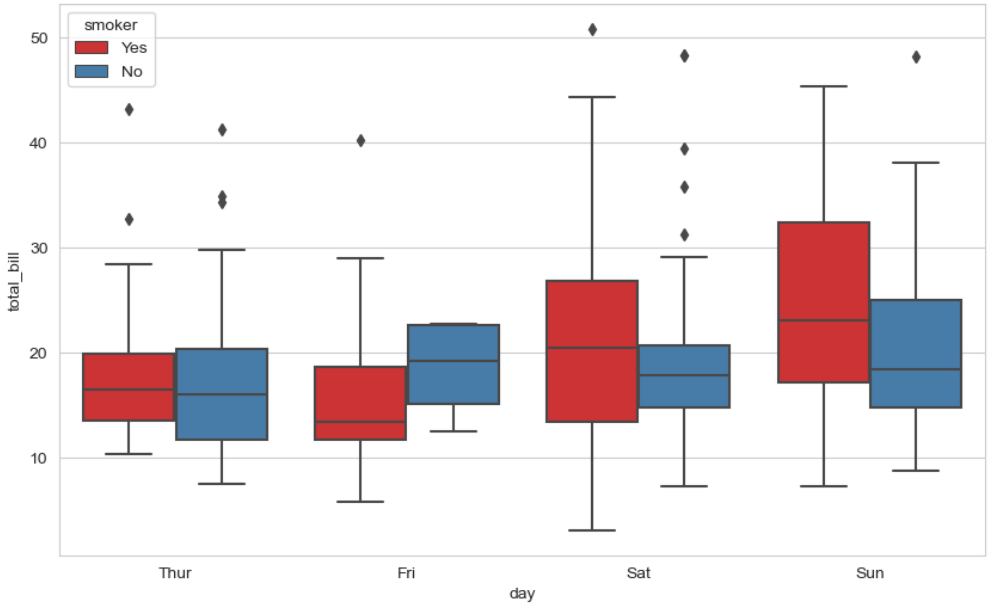
- swarmplot
📄 swarmplot 공식 문서
plt.figure(figsize = (가로 사이즈, 세로 사이즈))
sns.swarmplot(
x = "x축으로 할 컬럼명",
y = "y축으로 할 컬럼명",
data = 데이터프레임명 ,
color = "숫자값" #0(검은색) ~ 1(흰색) 사이의 숫자를 입력하는 색깔 옵션
)
plt.show()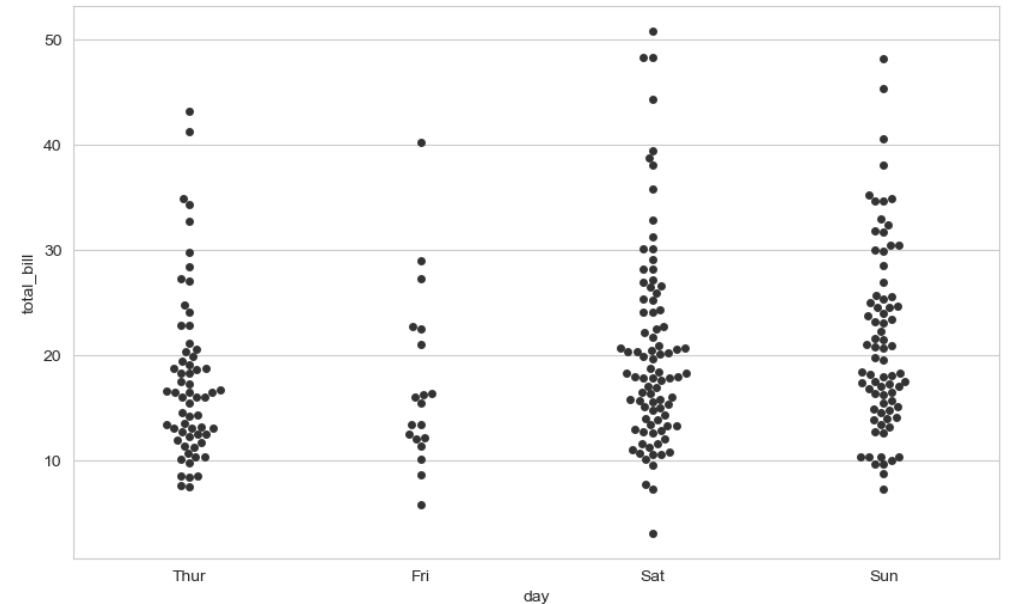
- lmplot (산점도 & 회귀 직선)
📄 lmplot 공식 문서
sns.set_style("배경명")
sns.lmplot(
x = "x축으로 할 컬럼명",
y = "y축으로 할 컬럼명",
data = 데이터프레임명 ,
height = 원하는크기(숫자),
hue = "카테고리형 컬럼명",
ci = None #신뢰구간 선택,
scatter_kws = {'s': 원하는 크기}, #딕셔너리 형태로, 산점도 점의 크기('s'). 크기 이외에 다양한 옵션이 있음
order = 원하는 값 ,#값이 커질수록 회귀 직선을 더 굴곡있게 그려줌
robust = True #이상치를 제외하고 선형회귀를 그려줌
)
plt.show()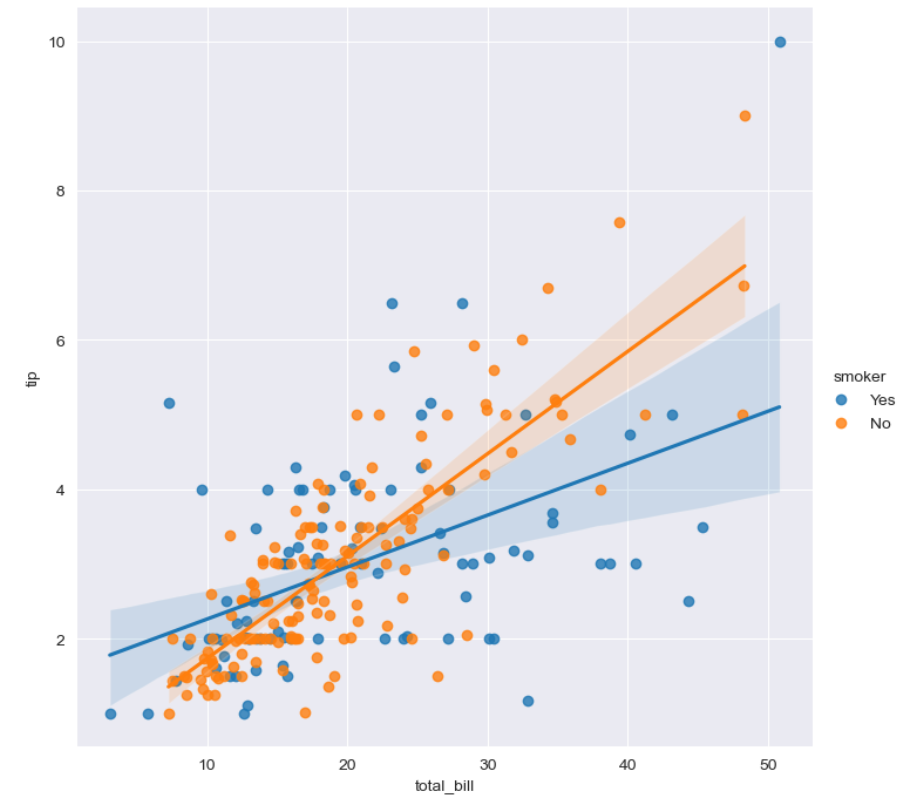
- heatmap
📄 heatmap 공식 문서
plt.figure(figsize = (가로 사이즈, 세로 사이즈))
sns.heatmap(
data = 데이터프레임명,
annot = True, #데이터 값 표시 옵션
fmt = "d" , # "d"는 데이터 값을 정수로 표시
cmap = "색상코드명"
)
plt.show()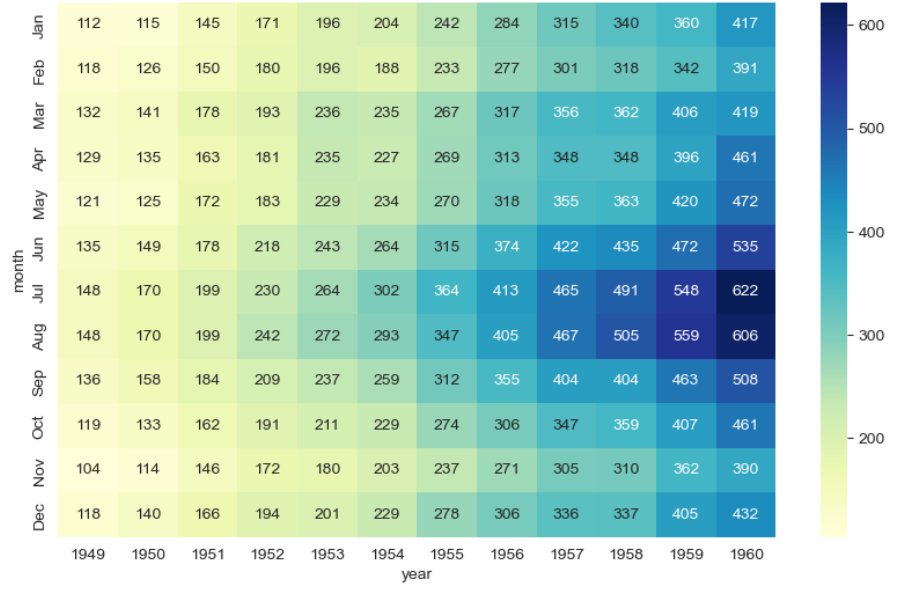
- pairplot
sns.set_style("배경명")
sns.pairplot(
데이터프레임명,
hue = "카테고리형 변수",
#원하는 컬럼만 pairplot을 그리는 옵션
x_vars = ["x축으로 원하는 컬럼값1", "x축으로 원하는 컬럼값2"],
y_vars = ["y축으로 원하는 컬럼값1", "y축으로 원하는 컬럼값2"]
)
plt.show()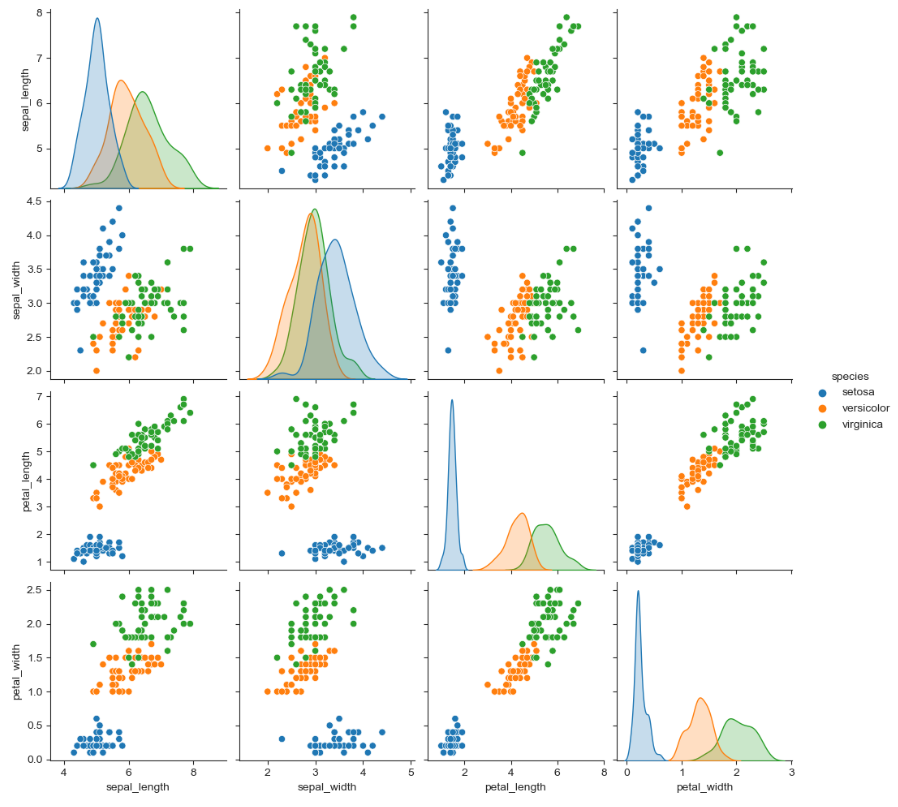
파이썬 리스트
- 반복문 사용 편리
for i in 리스트이름:
pass- in 명령 사용 편리
if 찾고자하는값 in 리스트이름:
pass- append : 리스트 제일 뒤에 추가
리스트이름.append("추가할 값")- pop : 제일 뒤 자료 하나 지움
리스트이름.pop()- extend : 제일 뒤에 다수의 아이템 추가
리스트이름.extend(['추가할 값1', '추가할 값2', '추가할 값3'])- remove : 같은 이름의 아이템 지움
리스트이름.remove("지우고자하는 값")- 슬라이싱 : [n:m] n번째부터 m-1번째까지
리스트이름[n:m]- inset : 원하는 위치에 아이템 삽입
리스트이름.inset(삽입할 인덱스, 추가할 값)-isinstance : 자료형이 list인지 확인 가능
isinstance(리스트이름, list) #True이면 리스트