arxiv : https://arxiv.org/abs/2006.04558\
Unofficial code :
1. https://github.com/ming024/FastSpeech2
2. https://github.com/rishikksh20/FastSpeech2
Introduction
-
이전의 Neural TTS Model pipelines
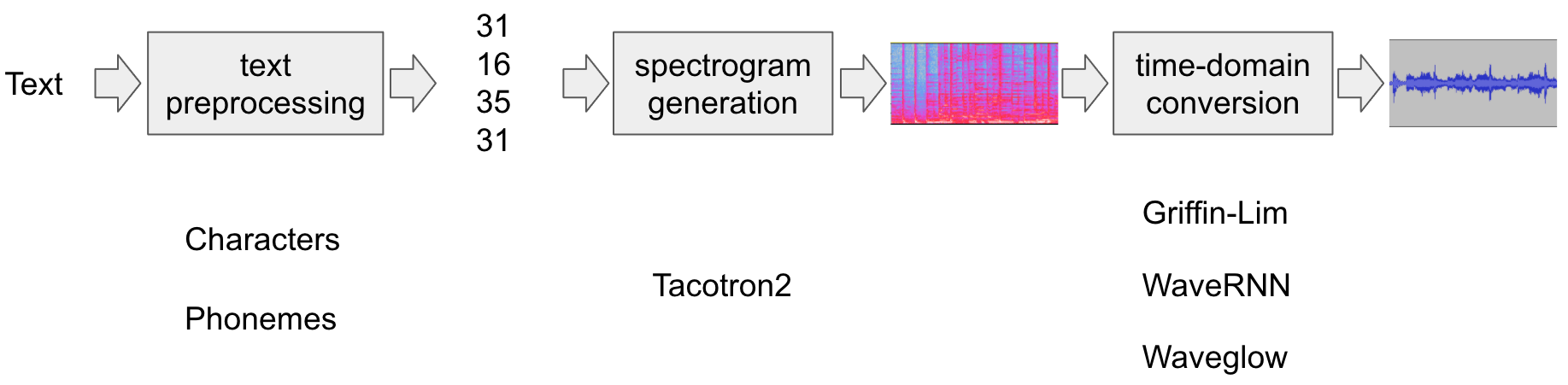
Reference :https://pytorch.org/audio/stable/tutorials/tacotron2_pipeline_tutorial.html -
TTS에서 자주 발생하는 문제점
-
Slow Inference
-
Robustness
→ Non-Autoregressive model의 방식을 통해서 해결하고자 함
-
-
FastSpeech
- 분산을 줄이기 위해서 Auto-regressive teacher model의 mel-spectrogram을 사용
- Teacher model의 attention map에서 추출한 duration information을 소개 ❗Duration information이란? Text 길이와 Mel-spectrogram길이를 맞춰주기 위한 정보
- 이러한 디자인을 통해서 one-to-many problem을 해결하고자 함 ❗one-to-many problem이란? 같은 텍스트에 대해서 여러가지 Speech가 나올 수 있는 문제
- 단점
- Teacher distillation이 복잡하여 모델이 복잡해짐
- 생성된 Mel-Spectrogram의 information loss가 생겨 실제 음성에 비해 합성된 음성이 품질이 좋지 않음
- Attention으로 추출된 duration information loss가 발생할 수 있음
-
FastSpeech2 & FastSpeech 2S
- 두 모델 모두 FastSpeech와 비교하면 간단한 pipeline과 빠르고 robust하며 음성 합성할 때 특히 pitch나 energy에 대해 더 control을 잘 할 수 있음
- 특히, FastSpeech 2S는 inference가 더 빠름
- 두 모델 모두 Fastspeech보다 음성 품질이 올라갔고 FastSpeech2는 autoregressive model보다 좋음
- Variation information of Speech를 소개
-
pitch
-
energy
-
more accurate duration
❗Pitch가 무엇이고 특성은 무엇인지?
- Speech 음율에서 중요한 정보
- 긴 시간에 따라 변동이 큰 데이터는 예측이 어려움
- continuous wavelet transform을 통해서 pitch spectrogram을 생성하는 방식을 채용
-
Main contribution
- FastSpeech 보다 간단한 훈련 파이프라인을 통해서 3배 빠른 훈련 속도를 실현
- 더 좋은 voice 품질을 얻을 수 있고 one-to-many mapping 문제를 완화
FastSpeech 2s는 더 간단한 음성 합성을 위한 inference 파이프라인을 voice 품질을 유지하며 실
FastSpeech2 and 2s
Motivation
- Non-Autoregressive model에서의 input이 오직 text라 정보가 부족함
- Training set에 대한 overfitting 발생 가능
- Overfitting 원인:
-
복잡한 pipeline
-
Target Mel-Spectrogram과의 information loss 존재
-
Ground truth duration과 비교하였을 때 정확성이 부족함
→ 이를 해결하기 위해 FastSpeech2가 고안되었음
-
Model Overview
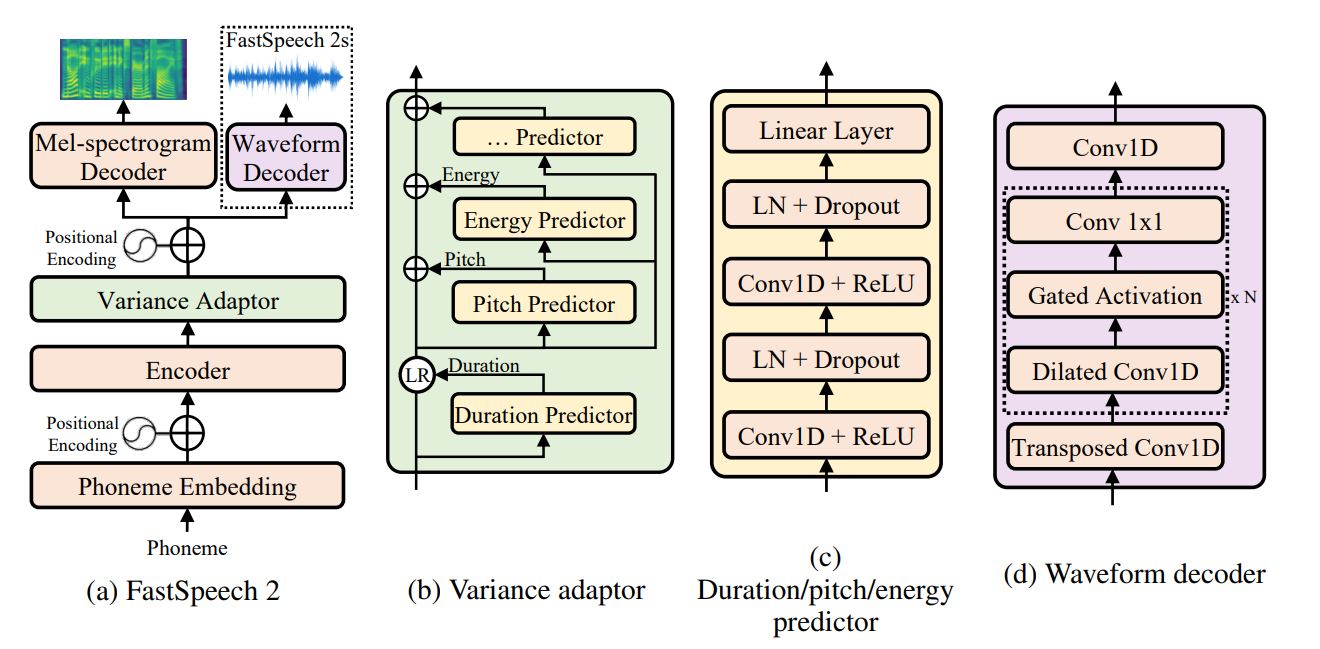
모델의 구성요소
-
Encoder
- Feed-forward Transformer blocks
→ Teacher-student distillation pipeline을 제거하여 information loss를 최소화함
-
Variance Adpater
- Duration Predictor
- forced alignment로 얻는 phoneme duration을 사용
- Pitch Predictor
- Energy Predictor
→ One-to-many problem을 완화하는 효과
- Duration Predictor
-
Decoder
- Mel-Spectrogram decoder ( FastSpeech 2 )
- Feed-forward Transformer blocks
- Waveform decoder ( FastSpeech 2s )
- Mel-Spectrogram decoder ( FastSpeech 2 )
Variance Adapter
- Variance information을 추가하는 역할
-
Phoneme duration → Duration Predictor
Speech voice가 얼마나 길게 소리가 나는가
현재 phoneme에 대해서 몇개의 mel frame이 해당하는가를 log를 취해서 예측
Montreal forced alignment(MFA) tool로 phoneme duration을 추출
-
Pitch → Pitch Predictor
Speech의 운율에 큰 영향을 미치고 감정을 담고 있는 정보
예측의 정확도를 높이기 위해서 continuous wavelet transform ( CWT )응 활용하여 pitch spectrogram을 생성 → Pitch를 더 좋게 만들어주고 prosody도 개선
- Pitch Embedding vector 생성과정
- Input (Pitch contour) → CWT( Pitch spectrogram 생성 ) → iCWT ( Pitch contour 생성 ) → Quantized ( 256 log-scale로 양자화 ) → Output ( pitch embedding vector )
- Input (Pitch contour) → CWT( Pitch spectrogram 생성 ) → iCWT ( Pitch contour 생성 ) → Quantized ( 256 log-scale로 양자화 ) → Output ( pitch embedding vector )
- Pitch Embedding vector 생성과정
-
Energy → Energy Predictor
Mel-spectrogram의 magnitude크기
- Energy embedding vector 생성과정
- Input → 각 STFT frame에 대해서 L2 norm 크기를 계산 → 256개의 수로 Quantized
- Energy embedding vector 생성과정
- 세 종류의 Predictor의 구조는 유사한 형태를 띄고 있음
- 세 구조 모두 MSE Loss를 optimize하는 방향으로 학습
FastSpeech 2s
End-to-End text-to-waveform 생성하는 모델
- Mel-spectrogram representation을 사용하지 않는다
- Challenges
- Waveform이 Mel-spectrogram에 비해서 가진 정보가 더 많기 때문에 아무래도 information gap이 더 클 수 밖에 없음
- 입력 텍스트의 길이가 길어질 수록 생성하는 phoneme의 개수가 많아지면서 phoneme과의 관계를 모델이 파악하는데 어려움을 가지며 큰 GPU 메모리를 필요로 함
- 그래서 현재 모델에서는 짧은 오디오 클립만 사용하여 학습을 진행함
FastSpeech 2s Decoder
- Adversarial training in the waveform decoder
- 위상정보를 모델 스스로 유추하도록 하는 decoder
- Discriminator는 Parallel WaveGAN과 동일한 구조를 사용
- Waveform decoder
- WaveNet 구조를 기반으로 non-casual convolution과 gate activation이 추가된 decoder
- multi-resolution STFT loss와 LSGAN discriminator loss를 사용
Experiments and Results
Datasets
- LJSpeech
Model Configuration
- 4 Feed-forward Transformer blocks for encoder & mel-spectrogram decoder
- Output dimension : 80-dim mel-spectrograms
- Optimize : MAE
Model Performance
Device
- 36 Intel Xeon CPUs
- 256GB memory
- 1 V100 GPU
- Mean Opinion Score ( MOS : Mean Opinion Score ) : 사람들에게서 설문조사
- Vocoder는 모두 WaveGAN을 사용
Baseline models
- Tacotron2
- TransformerTTS
- FastSpeech
Variance Information 분석
Pitch
- Moment 계산하고 pitch distribution의 DTW ( dynamic time warping) distance 평균을 계산
Energy
- MFA에서 추출한 duration 길이 만큼 frame-wise energy 사이의 MAE를 계산
Future works
- Variance Information을 더 넣어서 이를 잘 학습하는 모델의 설계
- 외부 alignment tool과 pitch extraction tool을 사용하였는데 이를 사용하지 않고도 더 간단한 구조로 high-quality and fast한 모델의 설계
