Glow-TTS: A Generative Flow for Text-to-Speech via Monotonic Alignment Search 논문리뷰
0
TTS reviews
목록 보기
3/4
Introduction
Autoregressive model
- Real-time inference가 어렵다
- 중복된 단어가 오류를 초래
Paralle TTS
- FastSpeech
- Alignment를 monotonic으로 제약을 두어 잘못 발음하는 경우 ( Mispronounciation ), 중복 단어 건너뛰기 ( Skipping repeating word ) 문제를 해결
- Extranl Alignment의 attention map을 가져와서 모델의 성능이 external aligner에 의존적임
Contribution
- Flow와 DP를 사용하여 text와 speech latent간 가장 확률이 높은 monotonic alignment를 찾을 수 있게함
- 긴 Utterance에서의 성능이 좋음
Related Work
Glow-TTS와 HMM/CTC 사이의 차이
- Glow-TTS & HMM
- DP를 사용한다는 점에서 비슷함
- Glow-TTS는 Parallel이라는 점에서 다름
- Glow-TTS & CTC
- 가장 그럴듯한 alignment를 text와 speech latent에서 찾는 점에서 비슷함
- Glow-TTS는 generative model이라는 점에서 다름
FastSpeech / ParaNet
- External aligner를 사용한다는 점에서 External aligner와 제안한 모델 간의 mismatch가 생길 수 밖에 없음
Flow-based Generative model
- 역변환이 가능한 변환을 사용하여 정확학 확률을 추전하는 모델
- 확률을 최대화하는 방식으로 학습
비슷한 시기의 연구
- AlignTTS
- no need external aligner
- Flow base model이 아니라 Feed-forward network
- FlowTTS
- no need external aligner
- soft attention module을 사용
- FlowTron
- Speech variation의 컨트롤 가능성을 보여줌
- soft attention modul을 사용
Method
Glow-TTS는 monotonic을 전제로 mel-spectrogram을 생성하며 non-skipping alignment를 생성할 수 있음
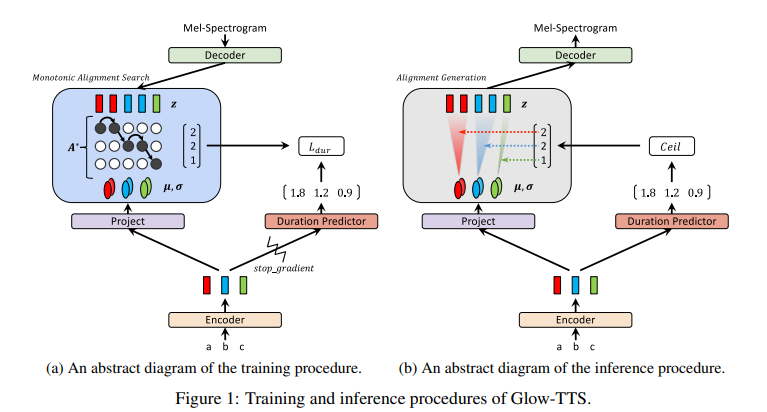
Training and Inference Procedures
- Prior distribution
- Isotropic multivariate Gaussian distribution
- Alignment search
- Global solution을 찾기 어려워서 search space를 줄임
- Monotonic alignment search를 활용
- Duration Predictor
- Alignment와 label의 duration을 맞추기 위해 사용
- stop gradient를 사용하여 log-likelihood의 영향을 주지 않으려고 함
Monotonic alignment Seach ( MAS )
- 특징
- 시간복잡도 : O ( 텍스트 길이 * 멜 스펙토그램 길이 )
- CPU에서도 잘 작동한다
- 전체 Training time의 2% 차지
- Inference에서는 사용하지 않음
Algorithm 설명
- Row : T_text
- Column : T_mel
- Q1_j : 1~j까지의 log ( prior distribution ) 의 합
Procedure
-
메모리 초기화
Q1_1 Q1_2 Q1_3 Q1_4 Q1_5 -inf -inf -inf -inf -inf -inf -inf -inf -inf -inf -inf -inf -inf -inf -inf -
메모리 전체 업데이트
예시 ) Q3_4 = Max(Q2_3 , Q2_4) + log( z4 prior distribution 값 )Q1_1 Q1_2 Q1_3 Q1_4 Q1_5 -inf Q2_2 Q2_3 Q2_4 -inf -inf -inf Q3_3 Q3_4 -inf -inf -inf -inf -inf -inf -
BackTrace를 통해서 A* 리스트 업데이트
예시 ) Q2_4, Q3_4 중에서 확률이 높은 path를 선택하여 Q2_3과 연결탐색 순서 : ←←←
Q1_1 Q1_2 Q1_3 Q1_4 Q1_5 -inf Q2_2 Q2_3 Q2_4 Q2_5 -inf -inf Q3_3 Q3_4 Q3_5 -inf -inf -inf Q4_4 Q4_5 -
Best Path 출력
예시 ) A* List : [0, 0, 1, 2, 2]Q1_1 Q1_2 Q1_3 Q1_4 Q1_5 -inf Q2_2 Q2_3 Q2_4 Q2_5 -inf -inf Q3_3 Q3_4 Q3_5 -inf -inf -inf Q4_4 Q4_5
Model Architecture
- Decoder 구성요소
- Activation normalization layer
- Invertible 1x1 convolution layer
- Affine coupling layer ( WaveGlow )
- Channels
- 80-channel mel-spectrogram frames
- 160-channel feature map
Encoder and Duration Predictor
- Transformer TTS의 encoder에서 변형된 구조
- Positional Encoding를 self-attention을 통한 relative position representation으로 변경
- Encoder의 pre-net에 residual connection 사용
Experiments
Dataset
Single Speaker setting
- LJSpeech
- 대략 24 hours
- 한 명의 여성 화자 데이터
- 12500 / 100 / 500으로 데이터 분리
Multi-Speaker setting
- LibriTTS의 train-clean 100
- 247명의 화자
- 54 hours
- Text length 190 이상인 데이터는 필터링
- 데이터의 처음과 끝은 trim
- 29181 / 88 / 442으로 데이터 분리
Robust test
- Harry Potter and the Philosopher’s Stone의 첫 Chapter의 text
- 최대 길이는 800 초과
비교 모델
- TacoTron2
- WaveGlow
학습 세팅
Single Speaker Setting
- 240K iteration
- Adam optimizer with Noam learning rate shedule
- V100 GPU로 mixed precision training을 사용하여 학습하는데 3일 걸림
Multi-Speaker setting
- Affine coupling layer의 임베딩 크기만 WaveNet과 동일하게
- 나머지는 Single speaker setting과 동일

내가 보려고 만든 논문 정리 블로그
정보에 감사드립니다.