VITS : Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech
0
TTS reviews
목록 보기
4/4
VITS
Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech
Arxiv : https://arxiv.org/abs/2106.06103
Introduction
TTS system pipeline
- 0 Stage : Text-preprocessing
- 1 Stage : Mel-spectrogram과 같은 intermediate representation으로 표현
- 2 Stage : Mel-spectrogram → waveform
이전 TTS system들의 특징
Neural network-based autoregressive TTS
- Sequential generative process때문에 병렬화에 어려움
Non-autoregressive TTS
- Pre-trained autoregressive teacher network를 통해 얻은 attention map을 통해서 alignment를 개선
Likelihood-based method
- Target mel-spectrogram의 likelihood를 최대화하는 방식으로 alignment를 개선
- External alignment dependency의 제거
GAN-based feed-forward networks with multiple discriminators
- Sample의 다른 scale과 period를 구분하기 위한 방법
- High-quality 음성 합성 구현
Two-stages pipelines
- Sequence training이나 fine-tuning이 필요
- 2 Stage에서의 학습에서 1 Stage에서의 결과가 필요하여 dependency 발생
End-to-End training method
- FastSpeech 2s, EATS
- 짧은 audio clip을 입력으로 사용
- Generated speech과 Target speech의 길이의 mismatch를 최소화
고안한 내용
- VAE를 사용하여 2개의 Stage를 결합
- Two-stages model을 Normalizing flows를 적용
- Waveform domain에 adversarial training을 적용
- One-to-Many problem을 해결하기 위해 stochastic duration predictor를 사용
Method
제안 방법
- Conditional VAE formulation
- Alignment estimation
- Adversarial training을 통해 음성 합성 성능 개선
Loss
VAE Loss + Duration predictor loss + Hifi-GAN Loss
Model architecture
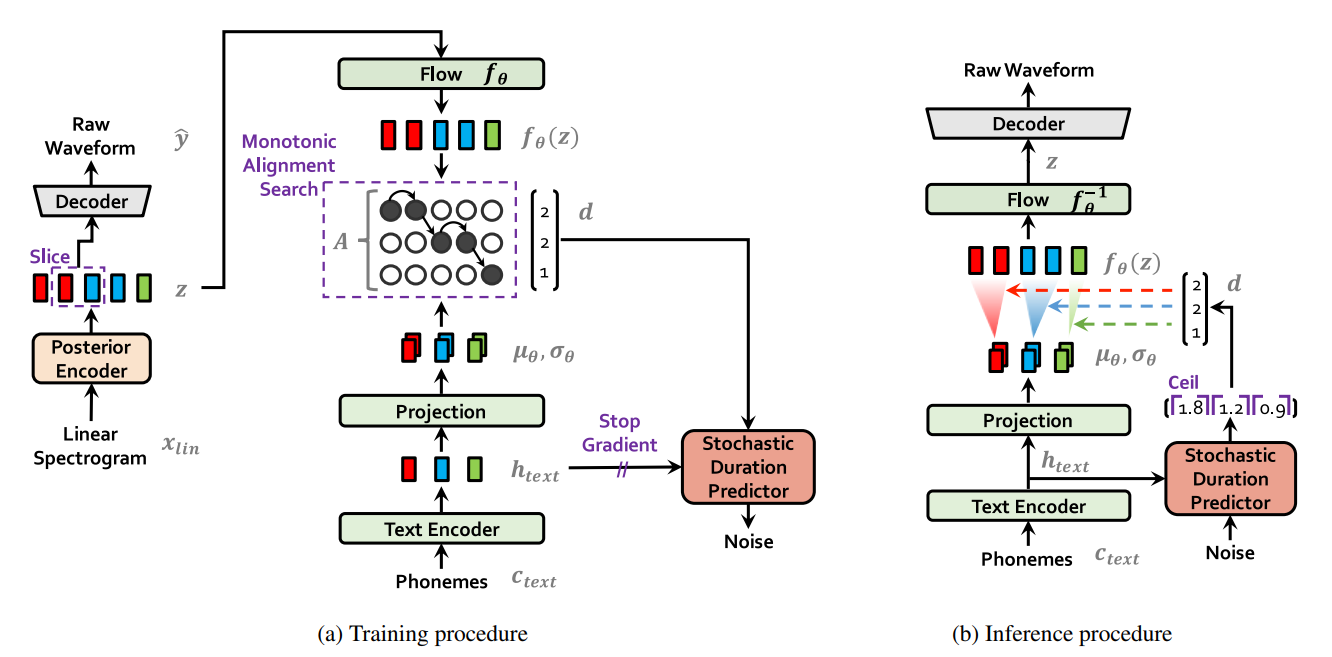
Stochastic Duration Predictor
- 문제점
-
Duration : discrete
Flow model : continuous
⇒ Variational dequantized 필요
-
Scalar 값은 고차원 변환시 역변환에 영향이 간다
⇒ Variational data augmentation 필요
-
- Stop gradient를 사용하는 이유?
- 다른 모듈에 영향을 주지 않기 위해
- DDS conv를 사용하는 이유?
- Large receptive field size를 유지하면서 효율적으로 파라미터화를 하기 위해
- Monotonic rational-quadratic splines를 사용하는 이유?
- 일반적으로 사용하는 Affine coupling layer flow보다 표현력 증가
Monotonic rational-quadratic splines flow
- 랜덤 변수 u , v ( 시퀸스와 동일 차원 )
- u ( dequantization을 위해 ) 값 범위 [ 0 , 1 ) : d - u 가 양수가 되도록
- v ( data augmentation을 위해 )
- u ( dequantization을 위해 ) 값 범위 [ 0 , 1 ) : d - u 가 양수가 되도록
- Affine coupling layer와 다른점
- Affine : posterior distribution의 노이즈를 u, v로 변환
- Splines : log likelihood augmented and dequantized data 위해 d-u, v로 노이즈를 변환
Decoder ( Hifi-GAN )
- Multi receptive field fusion module ( MRF )
- 다른 receptive field의 residual block의 sum
Discriminator ( Hifi-GAN )
- Multi-period discriminator
- Mixture of Markovian window-based sub discriminator
- 입력 waveform의 다양한 periodic pattern 생
Settings
Data settings
LJSpeech
- 1 Speaker
- 24 hours
- 13,100 short audio clips
- 12500 / 100 / 500 ( train/valid/test )
VTCK
- 109 English speaker with various accent
- 44 hours
- 44,900 short audio clips
공통
- 16-bit PCM audio format
- 22kHz sampling rate ( VTCK 원래 44kHz인데 22kHz로 downsampling )
전처리
- Linear spectrogram
- STFT
- FFT : 1024
- Winsow size : 1024
- Hop size : 256
- 80 bands mel-scale spectrogram ( Reconstruction loss 계산 시 )
- STFT
- Phoneme
- IPA sequence phoneme으로 변환
- Glow-TTS와 동일
Model settings
Training
- AdamW ( betas = ( 0.8, 0.99 ), weight_decay = 1e-2, lr = 2e-4 )
- Windowed generator training
- Commons.py의 def rand_slice_segment()
- Time / Memory를 줄이기 위해 사용
- window size : 32
- Batch size : 64
- Iteration : 800K steps
Evaluation
- Crowded-sourced MOS ( CMOS )
Experiments
Speech Variation
- Stochastic duration predictor가 얼마나 다양한 길이의 출력을 내는지 실
- 합성된 speech가 얼마나 다른 speech 특성을 지니고 있는지 실험
Data
- LJSpeech ( a )
- ‘How much variation is there’ duration 확률
- VTCK ( b )
- 5 speaker의 100가지의 생성된 utterance 분석
F0 contour
YIN algorithm으로 분석한 pitch 정보
- VITS ( multi-speaker )에서 pitch의 변화가 더 넓게 분포하는 것을 확인
- Glow-TTS는 표준편차의 변화로 pitch의 범위를 조절 할 수 있지만 결과 품질이 떨어
Multi-speaker setting
- Text Encoder에 speaker identity를 주지 않음 ⇒ Text Encoder가 speaker independent한 representation을 생성한다고 볼 수 있음 ⇒ voice만 바꾸는 task가 쉽게 가능해짐
Related works
End-to-end TTS
Fastspeech 2s
- Adversarial training
- Auxilary mel-spectrogram decoder
- 단점 : Training time에 pitch, energy등 여러 feature를 뽑아야함
EATS
- Adversarial training
- Differentiable alignment scheme
- Soft dynamic time warping loss
- Length mismatch의 완화
WaveTacotron
- Autoregressive model
- Tacotron2 + normalizing flow
VAE
Conditional VAE
- Latent prior distribution의 modulate
BVAE-TTS
- Bidirectional VAE in parallel
여러 논문들
- Normalizing flow로 VAE의 성능 개선
Flow-seq
- 기계번역 task
- Conditional VAE with normalizaing flow ( non-autoregressive model )이라는 점에서 유사
- VITS가 더 명확한 alignment
- MAS로 latent sequence의 부담 제거
Duration prediction
Parallel-TTS
- Deterministic duration predictor
Future works
- 텍스트 전처리 문제가 여전히 남아있다
- 전처리 과정을 제거한 self-supervised learning을 활용하는 방안

내가 보려고 만든 논문 정리 블로그
정보 감사합니다.