💡 Isolation Level
다수 사용자 환경에서 여러 Transaction 이 동시에 실행될 때 발생할 수 있는 다양한 이상현상들을 제어하는 수준으로,
Transaction 의 ACID 원칙 중 Isolation 을 지원하기 위해 제공된다.
- Isolation Level 이 높다
- 높은 Serializability
- 높은 안정성
- 동시 처리 가능한 트랜잭션 수 감소
- Isolation Level 이 낮다
- 낮은 Serializability
- 낮은 안정성
- 동시 처리 가능한 트랜잭션 수 증가
다시 말해, Isolation Level 에서 데이터의 정합성과 성능은 trade-off 관계에 있으며, 개발자는 애플리케이션 혹은 개발하고자 하는 기능의 특성을 고려하여 적절한 Isolation Level 을 선택할 수 있어야 한다.
Read Uncommitted
- Commit 되지 않은 데이터를 Read 할 수 있다.
- 가장 낮은 수준의 Isolation Level
- 가장 높은 동시 처리량
- 발생 가능한 이상현상
- Dirty read
- Non-repeatable read
- Phantom read
Read committed
- Commit 된 데이터만 Read 할 수 있다.
- 대부분의 RDBMS 가 default 로 가지는 Isolation Level
- Read Uncommitted 보다 높은 수준의 Isolation Level
- 발생 가능한 이상현상
- Non-repeatable read
- Phantom read
Repeatable Read
- 동일 Transaction 내 다수 Read 연산 시, 결과값의 일관성을 보장한다.
- MySQL 이 default 로 가지는 Isolation Level
- Read Committed 보다 높은 수준의 Isolation Level
- 발생 가능한 이상현상
- Phantom read
Serializable
- 어떠한 이상현상도 발생하지 않는다.
- 가장 높은 수준의 Isolation Level
- 가장 낮은 동시 처리량
Caution
SQL 표준에 정의된 Isolation Level 을 기준으로 작성하였으며, 각 Isolation Level 에서의 동작은 RDBMS 별로 다를 수 있습니다.
또한, 앞서 명시된 Dirty read, Non-repeatable read, Phantom read 외에도 Dirty write, Lost Update, Read skew, Write skew 등의 이상현상이 발생할 수 있습니다.
Snapshot Isolation
SQL 표준에 정의되지 않은 비표준 Isolation Level 이다.
기존의 SQL 표준에서 미리 정의된 이상현상을 기준으로 Isolation Level 을 분류하였다는 점, 상용 RDBMS 가 실제로 사용하는 방법을 Isolation Level 분류 시에 고려하지 않았다는 점을 비판하면서 새롭게 제시되었다.
- Transaction 의 시작 시점을 기준으로 Snapshot 을 생성한다.
- Transaction 진행 도중 변경되는 데이터들을 DB 에 즉시 반영하지 않고 Snapshot 으로 만들어두었다가, Commit 시 DB 에 반영한다.
- 다수의 Transaction 이 동일한 데이터에 대해 Write 작업을 시도하는 Write Conflict 가 발생할 경우, 먼저 Commit 된 Transaction 만이 DB 에 반영되고, 이후의 Transaction 은 Abort(Roll back) 된다. 이러한 방법을 First-Committer Win 이라고 부른다.
이처럼, Snapshot Isolation 은 Transaction 의 시작 시점에 생성한 Snapshot 을 활용하여 변경되는 데이터들의 Multi-version 을 관리하는 MVCC 의 한 종류라고 볼 수 있다.
💡 Locking
앞서 살펴본 바와 같이, 다수의 Transaction 이 동일한 데이터에 Read 혹은 Write 작업을 수행할 경우, Database 는 예상치 못한 위험에 빠질 수 있다.
따라서, 이러한 문제를 해결하기 위해 RDBMS 는 Lock 매커니즘을 사용한다.
Lock 매커니즘에서 각 Transaction 은 특정 데이터에 Read/Write 작업을 수행하기 위해 Read Lock 혹은 Write Lock 을 취득하여야 한다.
이 때, 이미 해당 데이터에 Lock 을 취득한 Transaction 이 존재한다면 Lock 취득에 실패하게 되고, Lock 을 반환할 때까지 대기하게 된다.
Shared Lock(read-lock)
SELECT… FOR SHARE MODE시에 사용되는 LockINSERT,UPDATE,DELETE와 같은 Write 작업에 사용 불가- 다른 Transaction 의 Shared Lock 만을 허용한다.
Exclusive Lock(write-lock)
INSERT,UPDATE,DELETE시에 사용되는 LockSELECT… FOR UPDATE시에 사용 가능- 다른 Transaction 의 모든 Shared Lock, Exclusive Lock 을 허용하지 않는다.
Caution
일반적인 Select 쿼리에서는 Lock 을 사용하지 않음에 주의하여야 합니다.
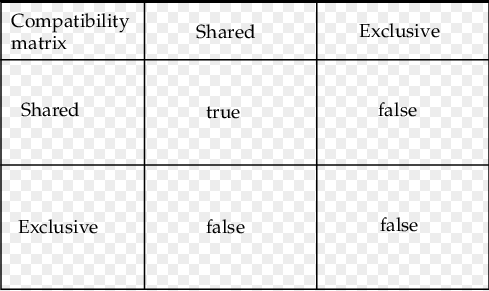
Lock Compatibility Matrix

Transaction 이 Lock 을 취득할 수 있는 상황과 취득에 실패하는 상황에 대해 정리한 Matrix
- Lock 을 취득할 수 있는 상황 ✅
- Read(t1) → Data ← Read(t2)
- Lock 을 취득할 수 없는 상황 ❌
- Write(t1) → Data ← Read(t2)
- Read(t1) → Data ← Write(t2)
- Write(t1) → Data ← Write(t2)
정리하면, 특정 데이터에 대해 Read Lock 이 걸려있는 경우 다른 Transaction 은 Read Lock 을 취득할 수 있고, 이를 제외한 모든 상황에서는 Lock 을 취득할 수 없어 대기하여야 한다.
이렇듯 Lock 매커니즘을 활용하게 되면 Write Lock 과 함께 수정 작업 중인 데이터에 대한 모든 Transaction 의 접근을 차단하여 이상현상의 발생을 효과적으로 줄일 수 있다는 장점이 있다.
하지만 Lock 매커니즘을 사용하여도 이상현상의 발생가능성은 여전히 존재하며, (이를 위해 Lock 의 취득과 반환 순서를 조절하는 Strict 2PL, Strong Strict 2PL 과 같은 2PL 프로토콜을 사용하기도 하지만 Deadlock 발생의 위험성이 있다.) 결론적으로 Database 의 동시 처리량이 감소하여 성능이 떨어지게 된다는 단점 또한 존재한다.
Lock 매커니즘은 분명 각 Isolation Level 에서 발생가능한 이상현상을 효과적으로 제어할 수 있는 시스템이지만, 결국 Write 작업에 대한 다른 Transaction 의 접근을 차단하여 해결하였다는 점에서 성능 상의 한계가 뚜렷하다.
MVCC(Multi Version Concurrency Control) 는 이러한 Lock 매커니즘의 한계를 극복하면서도 특정 데이터에 대한 Read Lock 과 Write Lock 상황에서의 안전한 작업을 보장할 수 있는 시스템으로, 이상현상의 발생을 최대한 억제하고 여러 Transaction 의 동시 처리를 지원하기 위해 대부분의 RDBMS 에서 기본적으로 제공하고 있는 기능이다.
💡 MVCC(Multi-Version Concurrency Control)
MVCC 는 이전의 Lock 매커니즘이 Read 연산의 동시 트랜잭션을 허용하고 이외의 모든 경우의 수를 허용하지 않았던 것과는 달리, Read 와 Write 연산의 동시 트랜잭션을 해결함으로서 높은 동시성 제공과 함께 이상현상의 발생을 효과적으로 억제할 수 있도록 하는 동시성 제어 기법이다.
MVCC Compatibility Matrix
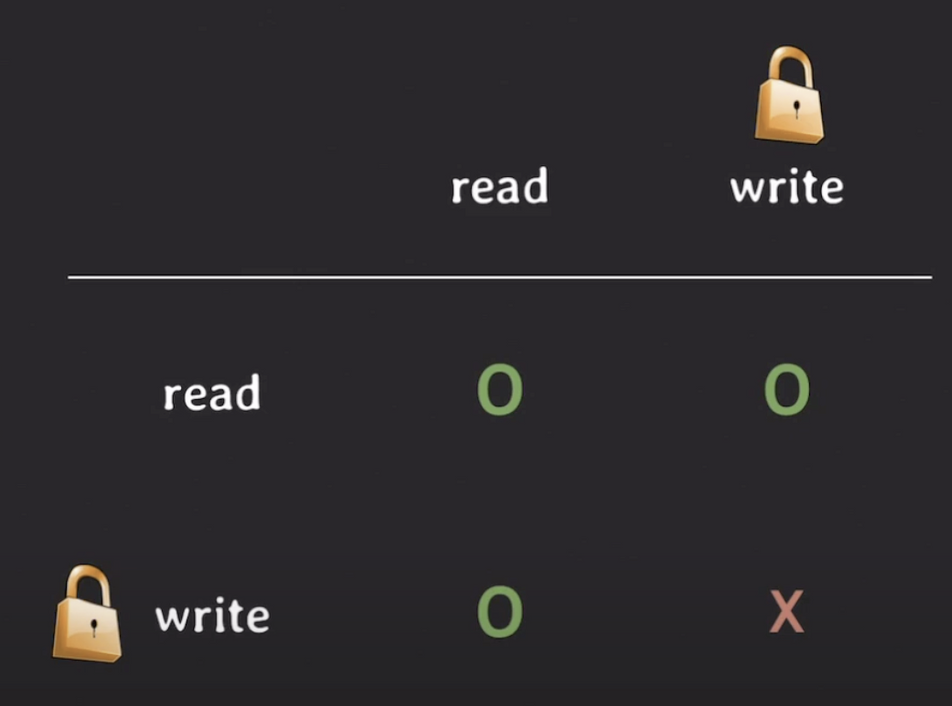
Transaction 이 Lock 을 취득할 수 있는 상황과 취득에 실패하는 상황에 대해 정리한 Matrix
- Lock 을 취득할 수 있는 상황 ✅
- Read(t1) → Data ← Read(t2)
- Write(t1) → Data ← Read(t2)
- Read(t1) → Data ← Write(t2)
- Lock 을 취득할 수 없는 상황 ❌
- Write(t1) → Data ← Write(t2)
위와 같이 MVCC 가 Read, Write 연산에 대한 충돌을 해결하고 Lock 매커니즘보다 높은 동시성을 제공할 수 있는 이유는 MVCC 가 기본적으로 Commit 된 데이터만 읽기 때문이다.
즉, Transaction2(t2)가 특정 데이터에 Exclusive Lock 을 취득하여 값을 Write 하였다고 하더라도, 동일 데이터를 Read 하는 Transaction1(t1)은 t2 가 Commit 되기 전까지 변경 전의 데이터를 조회하게 되는 것이다.
물론, t2 내에서 변경된 내역들은 별도의 공간에 보관되어 있다가 Commit 이 이루어지면 즉시 DB 에 반영된다.
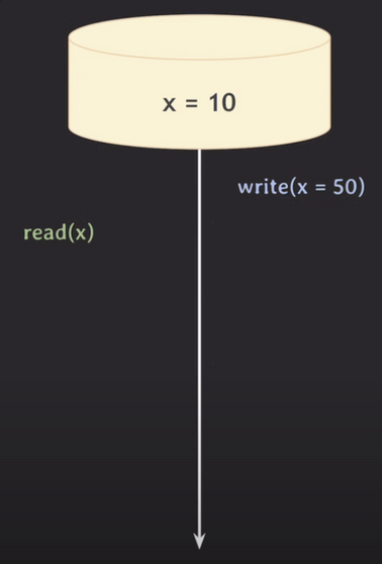
따라서, read(x) 의 결과는 변경 전의 데이터인 10 이다.
그렇다면, t1 이 동일 데이터에 대해 2번의 Read 연산을 수행하고, 그 사이 t2 의 Write 연산이 Commit 되었다면 t1 은 마지막으로 어떤 데이터를 읽게될까?

이러한 경우에는 Transaction 의 Isolation Level 에 따라 결과가 달라지게 된다.
기본적으로 MVCC 가 지원되는 Isolation Level 인 Read Committed, Repeatable Read 의 두 가지 상황을 살펴보자.
먼저, t1 의 Isolation Level 이 Read Committed 인 경우에는 t2 가 새롭게 Commit 한 변경 후의 값을 읽게 된다.
Read Committed Level 에서는 기본적으로 연산 수행 직전에 Commit 된 데이터를 읽기 때문이다.
따라서, t1 의 마지막 Read 연산 수행 직전의 Commit 데이터는 50 이므로, 두 번째 read(x) 의 값은 50 이 된다.
다음으로, t1 의 Isolation Level 이 Repeatable Read 인 경우에는 t2 가 Commit 되었다고 하더라도 변경 전의 값을 읽게 된다.
Repeatable Read 에서는 트랜잭션 시작 시점을 기준으로 그 전에 Commit 된 데이터를 읽기 때문이다.
따라서, t1 이 시작하기 전 데이터 값은 10 이었기 때문에 두 번째 read(x) 의 값은 첫 번째 연산과 동일하게 10 이 된다.
정리하면, MVCC 는 Transaction 이 데이터에 Read 연산을 수행할 때, 특정 시점을 기준으로 가장 최근에 Commit 된 데이터를 Read 하도록 하여 결론적으로 Read 연산과 Write 연산이 충돌하지 않고 동시에 수행 가능하도록 하는 기법이라고 볼 수 있다.
추가적으로, 이를 위해 하나의 Transaction 내에서 발생한 모든 Write 이력을 RDBMS 가 내부적으로 보관하고 있다가 Commit 시에 DB 에 반영하여야 하기 때문에 추가적인 저장공간을 사용하게 된다는 특징도 가지고 있다.
Caution
최근에 Commit 된 데이터를 읽어올 때의 기준이 되는 시점은 Isolation Level 마다 상이하며, 이를 구현하는 방법도 RDBMS 별로 다를 수 있음에 주의하여야 합니다.
하지만, 동일한 Isolation Level 에서의 Read, Write 연산의 결과값은 모든 RDBMS 가 기본적으로 동일합니다.
대부분의 Modern RDBMS 는 각 Isolation Level 별로 Locking 매커니즘과 MVCC 를 고루 사용하며 이상현상 발생을 억제하고 Transaction 의 동시 처리를 지원하고 있다.
앞서 설명한 내용들은 각 기능들에 대한 명세 중 일부에 지나지 않으며, 그 내부 동작과 제어 수준이 RDBMS 혹은 Isolation Level 마다 상이할 수 있으므로 본인이 사용 중인 RDBMS 에 대해 반드시 숙지하여 적절히 사용할 줄 알아야 한다.
