Goals
- PostgreSQL 의 특징인 Vacuum 의 필요성에 대해 이해한다.
- Vacuum 의 내부 동작에 대해 이해한다.
PostgreSQL 에는 Vacuum 이라는 개념이 존재한다.
이는 Garbage Collector 와 유사한 역할을 수행하는 동작으로, 사용하지 않는 데이터를 제거하여 메모리 공간을 확보하는 작업이다.
이러한 작업이 필요한 이유는 PostgreSQL 의 MVCC 내부 구현이 다른 RDBMS 와 차이가 있어, 이로 인한 문제를 해결하기 위함이다.
✅ PostgreSQL MVCC
먼저, PostgreSQL 의 MVCC 내부 동작을 살펴보자.
MVCC 란 이전에 정리한 글에서도 살펴봤듯이, DBMS 에서 발생하는 이상현상을 효과적으로 억제하고, 특정 데이터에 대한 Read, Write 연산의 충돌 혹은 Locking 을 방지하여 높은 동시 처리량을 제공하기 위해 RDBMS 에서 제공하는 기능이다.
MVCC 는 기본적으로 특정 시점을 기준으로 이전에 Commit 된 데이터만을 읽는 것을 원칙으로 하고 있다.
Isolation Level, Lock and MVCC in RDBMS
예를 들어 Oracle 의 MVCC 에서는 UNDO segment(Rollback segment) 를 사용하여 이곳에 특정 데이터에 대한 변경 이력을 모두 저장하고 있다.
이 때 Transaction1(t1) 의 진행 도중, 다른 Transaction2(t2) 에 의해 Write 연산이 수행된 블록을 만나면 복사본 블록(CR 블록)을 만들고 그 복사본 블록에 UNDO segment 를 적용해 이전의 데이터를 불러와 읽어내는 방식으로 MVCC 가 동작한다.
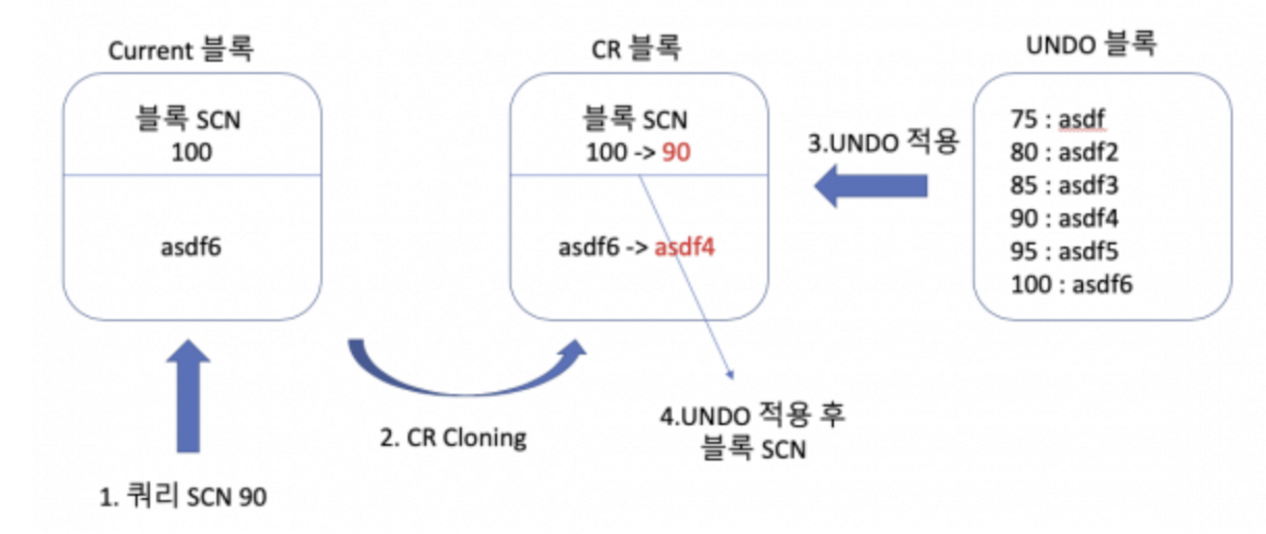
MySQL 에서도 Oracle 과 유사하게 UNDO segment 를 활용하여 MVCC 를 수행하며, 변경된 데이터 이력을 보관하고 있는 이 공간에서 이전의 데이터를 읽어와 작업을 수행하게 된다.
즉, Repeatable Read Level 에서는 Transaction 의 수행 시작 시점을 기준으로 이전의 Committed data 를 읽어오기 때문에 Transaction Id 를 비교하여 UNDO segment 에서 이전 Transaction Id 의 데이터를 읽어오게 될 것이다.
그렇다면, PostgreSQL 에서 MVCC 는 어떤 방식으로 동작할까?
PostgreSQL 에서는 하나의 데이터 페이지 안에 이전 Tuple(data) 과 변경된 Tuple 을 모두 보관하고 각각의 Tuple 별로 생성된 시점의 Transaction Id 와 변경 혹은 제거된 시점의 Transaction Id 를 기록하는 방식으로 MVCC 를 제공한다.
즉, Transaction 이 시작하게 되면 Transaction Id(이하 trx_id)를 할당받고 데이터 페이지 내에서 자신의 trx_id 보다 작은 trx_id 를 가진 Tuple 을 읽어오는 방식으로 동작하는 것이다.
이 때, Tuple 이 생성되거나 변경 혹은 제거된 시점을 각각의 Tuple 내 xmin, xmax 라는 Metadata field 에 기록하여 이를 기준으로 읽기 가능한 데이터를 구별하게 된다.
- xmin
INSERT시 신규 Tuple 의 xmin 에 trx_id 할당UPDATE시 신규 Tuple 의 xmin 에 trx_id 할당
- xmax
DELETE시 변경 이전 Tuple 의 xmax 에 trx_id 할당UPDATE시 변경 이전 Tuple 의 xmax 에 trx_id 할당, 신규 Tuple 의 xmax 에 NULL 할당
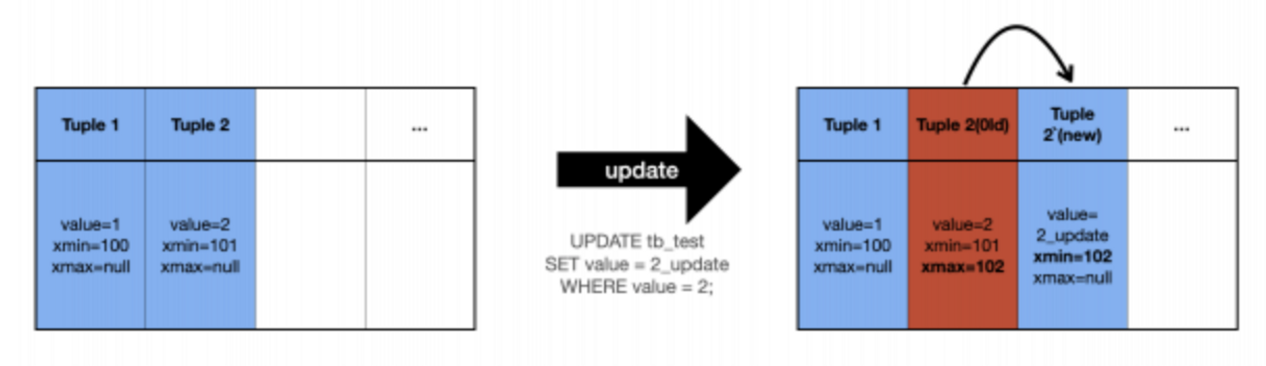
여기서 우리는 PostgreSQL 에서의 MVCC 와 UPDATE 시의 내부 동작이 Oracle, MySQL 의 동작 방식과 커다란 차이가 있음을 알 수 있다.
PostgreSQL 에서 UPDATE 는 기존 Tuple 의 데이터를 변경하고 이전 데이터를 Snapshot 하는 방식이 아니라, 새로운 Tuple 을 만들어 INSERT 하고, 이전 Tuple 을 DELETE 하는 방식으로 이루어진다는 것이다.
이 때, 새로운 Tuple 의 xmin 에는 현재 trx_id 가 할당되고, 변경 이전 Tuple 의 xmax 에도 현재 trx_id 가 할당되는 방식으로 UPDATE 가 이루어지기 때문에 실제로 변경 이전 Tuple 이 제거되는 것은 아니다.
뿐만 아니라, PostgreSQL 의 MVCC 는 이렇게 변경 혹은 제거된 Tuple 들이 DB 에 그대로 남아있는 상태에서 각 Tuple 의 xmin, xmax 값을 통해 읽기 가능한 데이터를 구별해내는 방식으로 동작한다.
아래 예시를 살펴보면, PostgreSQL 에서 xmin 과 xmax 을 활용한 MVCC 동작 방식을 어렵지 않게 이해할 수 있을 것이다.
xmin | xmax | value
-------+-------+-------
2010 | 2020 | AAA
2012 | 0 | BBB
2014 | 2030 | CCC
2020 | 0 | ZZZ- trx_id 2015 에서는 ‘AAA’, ‘BBB’, ‘CCC’ 를 Read 할 수 있다.
- ‘ZZZ’ 는 xmin 이 2020 이므로, 아직 존재하지 않는 값이고 Read 할 수 없다.
- trx_id 2021 에서는 ‘BBB’, ‘CCC’, ‘ZZZ’ 를 Read 할 수 있다.
- ‘AAA’ 는 xmax 가 2020 이므로, trx_id 2020 까지만 존재했던 값이고 Read 할 수 없다.
- trx_id 2031 에서는 ‘BBB’, ‘ZZZ’ 를 Read 할 수 있다.
- ‘AAA’, ‘CCC’ 는 xmax 가 2020, 2030 이므로, trx_id 2020, 2030 까지만 존재했던 값이고 Read 할 수 없다.
✅ Vacuum 의 필요성 1 - Dead Tuple 정리 및 FSM 확보
앞서 살펴본 바와 같이, PostgreSQL 에서 MVCC 를 위한 UPDATE 쿼리는 아래와 같이 동작한다.
- FSM 에 사용 가능한 공간이 있는지 확인하고, 없으면 추가 FSM 확보
- FSM 의 사용 가능한 공간에 변경된 데이터를
INSERT - 변경된 데이터의 추가가 완료되면, 이전 Tuple 을 가리키던 포인터를 새롭게 추가된 데이터로 변경
📌 Caution
FSM(Free Space Map) 은 PostgreSQL 에서 사용 가능한 공간을 표시한 지도와 같은 역할을 수행합니다.
이진 트리로 구성된 FSM page 들을 tree 형태로 표현하고 있으며, 각 테이블과 인덱스는 이 FSM 을 통해 사용 가능한 공간을 추적합니다.
만약 사용 가능한 FSM 공간이 부족하다면, 새로운 FSM page 를 생성하게 됩니다.
이렇듯, UPDATE 가 완료되면 변경 이전의 값을 저장하고 있는 Tuple 은 어디에서도 참조되지 않는 Tuple 이 되는데 이러한 Tuple 들을 Dead Tuple 이라고 한다.
문제는 이 Dead Tuple 들이 어디에서도 참조되지 않는 상태에서 FSM 에 메모리를 차지하고 있다는 점인데, 이를 효율적으로 정리해주거나 제거해주지 못하게 되면 메모리 낭비가 발생하게 되고, 부족해진 FSM 공간때문에 새로운 FSM page 를 생성하게 되면서 쿼리의 성능이 저하되는 문제 또한 발생한다.
📌 Caution
새로운 FSM page 의 생성이 쿼리의 성능에 악영향을 미치는 이유는 PostgreSQL 의 FSM page 가 다른 RDBMS 들의 Block 과 같은 역할을 수행하기 때문입니다.
즉, PostgreSQL 에서는 데이터를 읽을 때 FSM page 단위로 읽어와 메모리에 올리게 됩니다. 이 때, 각 page 의 크기는 default 8KB 로 한정되어 있고, 쓸모없는 Dead Tuple 들이 FSM page 에서 공간을 차지하게 되면 Live Tuple 을 읽어내기 위해 더 많은 FSM page 를 메모리에 올려 읽어내어야만 합니다.
결국 메모리에 올려야 하는 FSM page 가 많아질수록, 디스크 I/O 작업은 더욱 많아지게 되고, 이는 쿼리의 성능 저하로 이어지게 되는 것입니다.
이러한 문제를 해결하고 방지하기 위해 PostgreSQL 에서는 Vacuum 이라는 동작을 사용하고 있는데, 쌓여있는 Dead Tuple 들을 정리하고 제거하여 FSM 으로 반환하는 동작을 수행하게 된다.
✅ Vacuum 을 활용한 문제 해결 1
PostgreSQL 에서는 DBMS 가 자동으로 Vacuum 을 수행하는 AutoVacuum 기능을 제공하고 있으며, 개발자가 직접 명령을 통해 수행할 수도 있다.
이 때, Vacuum 은 일반적인 Vacuum 과 Vacuum Full 이라는 두 가지의 동작으로 구분될 수 있다.
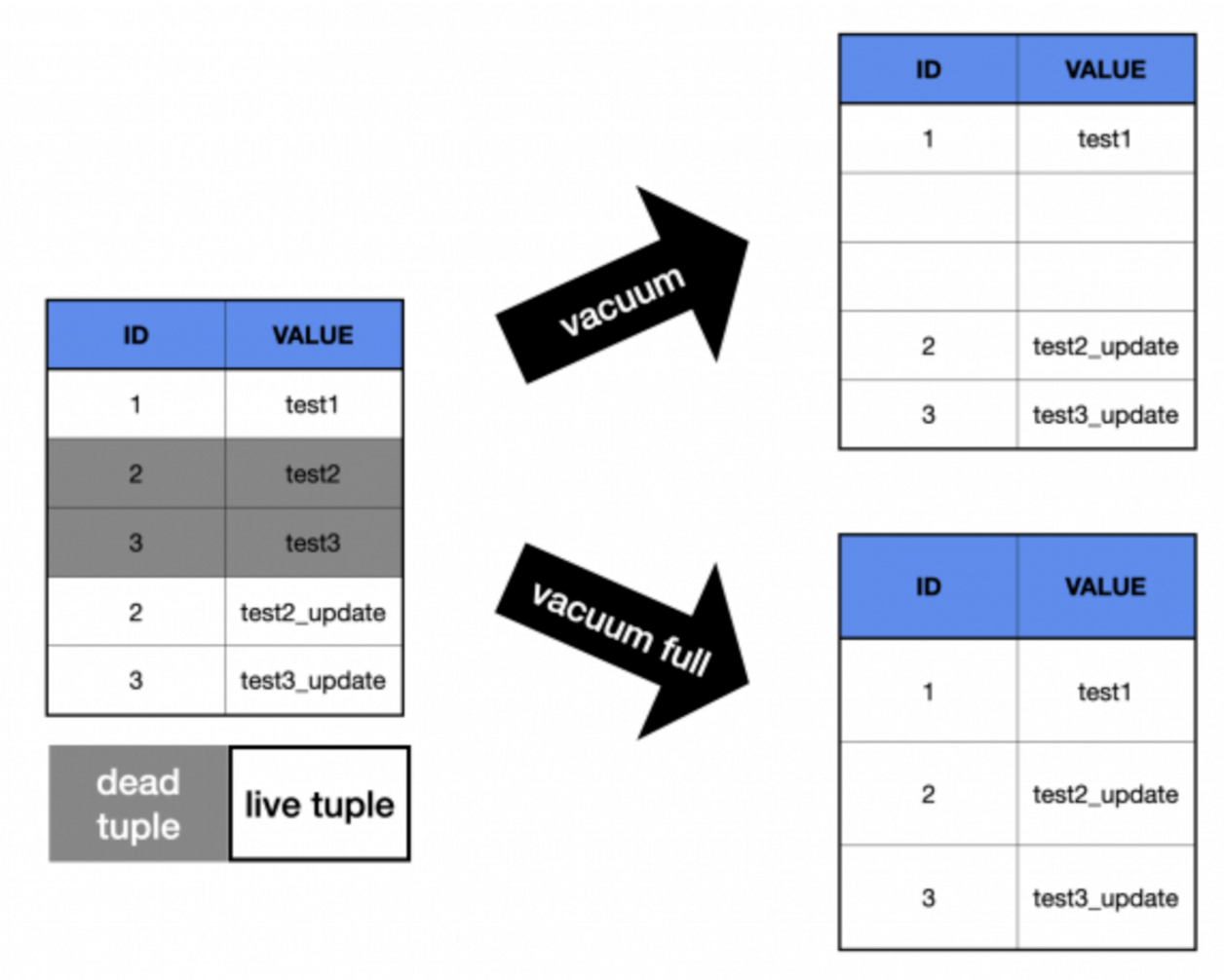
- Vacuum
- Dead Tuple 을 FSM 으로 반환
- OS 디스크의 메모리 확보 X
- Vacuum Full
- Dead Tuple 을 FSM 으로 반환
- OS 디스크의 메모리 확보 O
즉, 일반적인 Vacuum 의 경우에는 Dead Tuple 을 FSM 으로 반환하여 재사용 가능한 공간으로 확보하게 되지만, OS 디스크의 공간 반환까지는 처리하지 못하므로 테이블의 기존 크기는 그대로 유지된다. 개발자가 수행하는 VACUUM 명령과 DBMS 의 AutoVacuum 은 일반적인 Vacuum 으로 수행된다.
반면에 Vacuum Full 의 경우에는 Dead Tuple 을 FSM 으로 반환하고, OS 디스크의 공간까지 반환하기 때문에 테이블의 물리적인 크기까지도 줄어들게 된다. 개발자가 수행하는 VACUUM FULL 명령을 통해 수행할 수 있다.
하지만 Vacuum Full 은 서비스가 운영 중일 때는 수행이 어렵기 때문에 평소에 Vacuum 관련 정책을 적절하게 세워서 Dead Tuple 및 메모리 공간의 관리를 효율적으로 수행하는 것이 중요하다.
📌 Caution
Vacuum Full 은 테이블 Exclusive Lock 을 획득하여 수행되기 때문에 데이터에 대한 모든 접근이 대기하게 되어 서비스 운영 중에는 수행이 어렵습니다.
또한, 대상 테이블을 통째로 Copy 하는 방식으로 동작하기 때문에 디스크 용량이 여유롭지 못한 상황에서는 시도할 수 없습니다.
이렇듯, Vacuum 은 Dead Tuple 을 정리 및 제거하고 FSM 혹은 물리 디스크 공간을 확보하여 효율적인 메모리 사용과 쿼리 성능 저하를 방지하는 역할을 수행한다.
하지만 Vacuum 의 역할은 이 뿐만이 아니다.
✅ Vacuum 의 필요성 2 - Transaction Id Wraparound 방지
기존 이슈가 디스크의 비효율적인 사용과 DB 쿼리 성능 저하를 유발하는 성능 상의 문제였다면,
이제부터 알아볼 Transaction Id Wraparound 는 서비스 중단을 야기하는 더욱 심각한 이슈라 볼 수 있다.
📌 Caution
Transaction Id Wraparound 는 서비스 운영에 치명적인 이슈이므로, Vacuum 이 적절하게 수행되지 못해 Transaction Id Wraparound 가 발생할 가능성이 높아질 경우에는 AutoVacuum 이 OFF 로 설정되어 있더라도 DB 에서 강제로 Vacuum 을 수행하게 됩니다.
먼저, Transaction Id Wraparound 에 대해 살펴보기 전에 Transaction Id 의 개념을 살펴보자.
- Transaction Id
- Transaction Id 란, 각각의 Transaction 에 부여되는 고유한 값으로 Tuple 의 xmin, xmax 에 할당되어 PostgreSQL MVCC 동작에 핵심적인 역할을 수행한다.
- xmin 과 xmax 에 할당된 바이트 수는 각각 4바이트로 약 40억(2^32)개의 Transaction 을 표현할 수 있으며 그 중 20억 개는 과거, 나머지 20억 개는 미래를 위해 사용하게 된다.
정리하면 Transaction Id 는 각각의 Transaction 에 부여되는 고유한 값으로, Transaction 이 실행된 시점을 비교하는 데 사용될 수 있으며, 각 Tuple 의 xmin 과 xmax 는 표현할 수 있는 Transaction 의 수가 약 40억 개로 한정되어 있다는 것이다.
만약 각 Tuple 의 xmin, xmax 가 표현할 수 있는 Transaction 수를 초과하여 다음 Transaction 부터 다시 1 이라는 Id 값을 가지게 된다면 어떻게 될까?
이 경우, 표현할 수 있는 Transaction 수를 모두 돌고 난뒤 1이라는 Id 값을 할당받은 새로운 Transaction 은 Id 값이 2인 Transaction 보다 최신의 데이터임에도 불구하고, 모든 데이터들이 미래의 데이터가 되어 어떤 값도 읽을 수 없게 될 것이다.
바로 이러한 상황을 과거 데이터들이 모두 소실되는 Transaction Id Wraparound 라고 부른다.
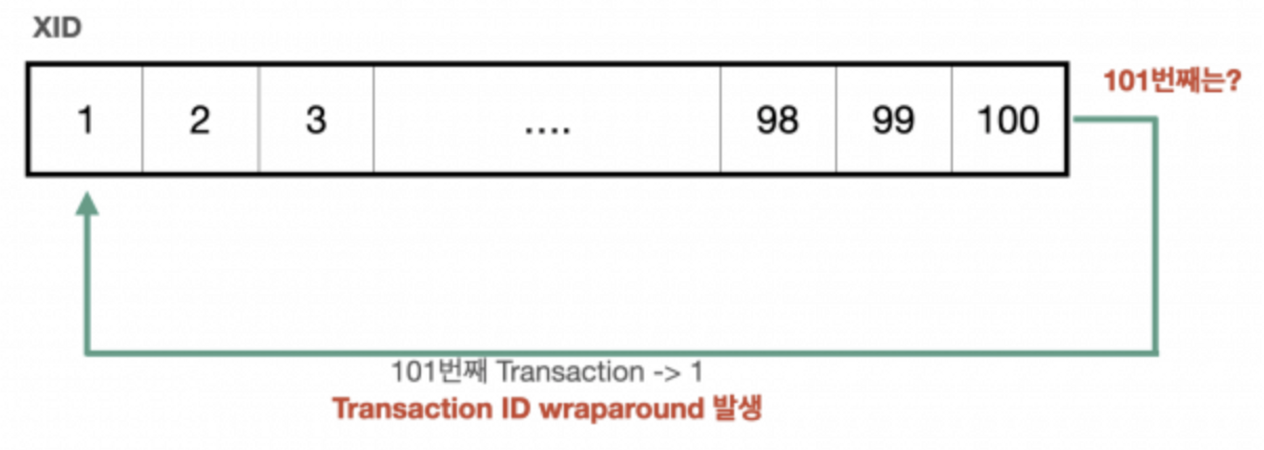
따라서, PostgreSQL 에서는 Transaction Id 를 재사용하기 위해 Freeze 혹은 Anti Wraparound Vacuum 이라 불리는 Vacuum 기법을 사용한다.
✅ Vacuum 을 활용한 문제 해결 2
- Freeze(Anti Wraparound Vacuum)
- Transaction Id 를 1부터 다시 재사용하게 되면, Transaction Id Wraparound 가 발생하기 때문에 PostgreSQL 은 Transaction Id 를 계속해서 증가시키지 않는다.
- 특정 시점이 되면 과거의 모든 Transaction Id 를
FrozenXID라는 특별한 값으로 변경하고,FrozenXID값을 가진 모든 Transaction 은 항상 Old Version, 즉 읽기 가능한 Transaction 으로 분류된다. 이러한 동작을 Freeze 혹은 Anti Wraparound Vacuum 이라 부른다.
즉, Freeze 는 기존의 Transaction Id 를 FrozenXID 라는 특별한 값으로 변경하여 항상 읽기 가능하도록 하고, Transaction Id 를 덮어쓰는 행위없이 순환할 수 있도록 하는 해결 방법이다.
이어서, Freeze 의 내부 동작에 큰 영향을 끼치는 Age 에 대해서 살펴보도록 하자.
- Age
- 테이블과 같은 오브젝트와 Tuple 의 나이를 의미한다.
- 테이블 생성 혹은 Tuple 의 Insert 시에 Age 는 1부터 시작하며 Transaction 이 발생할 때마다 1씩 증가하게 된다.
- 해당 테이블이나 Tuple 에 대한 Transaction 이 아니더라도 모든 테이블 및 Tuple 의 Age 가 증가한다.
즉, PostgreSQL 에서 Age 는 해당 테이블이나 Tuple 이 생성된 이후, 전체 DB 에 몇번의 Transaction 이 수행되었는지를 표현한 값이라 볼 수 있다.
따라서, 이 값은 꼭 해당 테이블이나 Tuple 에 대한 Transaction 이 아니더라도 DB 전체에 대한 Transaction 이 발생한 경우에 계속해서 증가해야 하는 값이다.
이렇게 Age 가 지속적으로 증가하다가 설정된 임계치에 도달하면, Transaction Id Wraparound 를 방지하기 위한 Freeze 의 대상이 되고, Freeze 가 수행된 이후에는 테이블과 모든 Tuple 의 Age 가 초기화된다.
이 때, Age 는 크게 2가지로 분류된다.
- Tuple Age
- Table Age
Tuple 은 Freeze 가 수행될 때 그 대상이 되는 객체이며, 대상이 되는 기준은 파라미터로 직접 설정할 수 있다. 기본값은 5천만이다.
즉, 생성된 후 5천만 번의 Transaction 이 수행되어 Age 가 5천만이 넘은 Tuple 이 존재한다면 Freeze 의 대상이 되는 것이다.
반면 Table 은 Freeze 가 수행되는 대상은 아니다.
하지만 Table 의 Age 는 해당 테이블에 속한 Tuple 의 Age 중에서 가장 높은 값으로 설정되기 때문에 결국 Tuple 의 Age 를 대표하는 특성을 가지게 된다.
따라서 Table 에 속한 모든 Tuple 의 Age 를 Full Scan 하여 Freeze 의 대상을 찾을 필요없이, Table 의 Age 만 확인해도 Freeze 의 대상 Tuple 을 저장하고 있는 테이블을 쉽게 판단할 수 있게 된다.
지금까지 살펴본 PostgreSQL MVCC 내부 동작으로 인한 문제점들, 그리고 Vacuum 을 통해 해결하는 방법을 간단하게 정리해보면 다음과 같다.
- 문제점
- Dead Tuple 누적으로 인한 디스크의 비효율적 사용 및 쿼리 성능 저하
- Transaction Id 중첩 문제(Transaction Id Wraparound)
- 해결방안
- AutoVacuum 과
VACUUM,VACUUM FULL명령으로 Dead Tuple 제거 - Freeze(Anti Wraparound Vacuum) 를 통해 Transaction Id Wraparound 방지
- AutoVacuum 과
✅ AutoVacuum
마지막으로, 앞서 살펴본 Dead Tuple 이슈와 Transaction Id Wraparound 이슈에서 AutoVacuum 이 수행되는 조건과 상황에 대해 조금 더 살펴보면서 포스팅을 마치려고 한다.
AutoVacuum 은 PostgreSQL 이 설정된 임계값에 따라 자동으로 수행하는 Vacuum 작업을 의미하며, 기본적으로 아래 두 가지 상황에서 수행된다.
- Dead Tuple 의 개수가 임계값에 도달했을 경우
- Table 혹은 Tuple 의 Age 가 임계값에 도달했을 경우
💡 Dead Tuple 의 개수가 임계값에 도달했을 경우
Dead Tuple 관련 이슈에서 AutoVacuum 이 수행되는 조건은 아래의 식을 따른다.
(number of Tuples * autovacuum_scale_factor) + autovacuum_vacuum_threshold식의 결과값은 곧 Dead Tuple 개수의 임계값이 되고 DB 에 쌓인 Dead Tuple 의 개수가 해당 임계값을 넘게 되면, AutoVacuum 이 자동으로 수행된다.
관련 파라미터는 아래와 같다.
name | setting
--------------------------------+---------
autovacuum_vacuum_scale_factor | 0.2
autovacuum_vacuum_threshold | 50- autovacuum_vacuum_scale_factor
- 테이블의 전체 Tuple 개수 중 설정된 비율만큼의 Dead Tuple 이 생성되면 AutoVacuum 수행
- 기본값은 0.2
- autovacuum_vacuum_threshold
- 테이블 내 생성된 Dead Tuple 의 개수가 설정된 개수를 넘어가면 AutoVacuum 수행
- 기본값은 50
즉, 특정 테이블의 생성된 Dead Tuple 개수가 (모든 Tuple 의 개수 * 0.2) + 50 을 넘어가게 되면 AutoVacuum 이 수행되어 테이블 내 Dead Tuple 을 정리하게 된다.
💡 Table 혹은 Tuple 의 Age 가 임계값에 도달했을 경우
Age 가 임계값에 도달하여 수행되는 Anti Wraparound Vacuum 은 Transaction Id Wraparound 를 방지하기 위해 수행되는 작업으로 Freeze 라고도 불리며, 아래 두 가지 경우에 수행된다.
Table Age > autovacuum_freeze_max_age- autovacuum_freeze_max_age
- 테이블의 Age 가 설정된 임계값을 초과한 경우 강제로 Anti Wraparound AutoVacuum 수행
- AutoVacuum OFF 설정이 있더라도 강제로 수행
- 기본값 2억
vacuum_freeze_table_age < Table Age < autovacuum_freeze_max_age- vacuum_freeze_table_age
- 테이블의 Age 가 설정된 임계값을 초과한 경우, 해당 테이블에 대한 Vacuum 작업 시 Anti Wraparound AutoVacuum 도 함께 수행
- 기본값 1억 5천
- vacuum_freeze_min_age
- Tuple 의 Age 가 설정된 임계값을 초과한 경우, Vacuum 작업 시 Freeze 작업 대상 Tuple 이 된다.
- Anti Wraparound AutoVacuum 수행 이후, 테이블의 Age 는 vacuum_freeze_min_age 가 된다.
- 기본값 5천만
물론, PostgreSQL 에서 Vacuum 과 관련된 파라미터는 이보다 더욱 다양하다. 서비스의 규모와 특성에 따라 권장되는 파라미터는 상이하기 때문에 각 파라미터에 대한 설명과 설정 방법에 대해서는 이후 지속적으로 포스팅해나갈 예정이다.
