
본격 개발의 달! 5월을 보냈다😂
현재 연구실에서 (1) 주기적으로 실행되어야 하고 (2) 실시간으로 작업 현황이 모니터링 되어야 하는 서비스를 개발 중인데, 초기에는 Airflow를 검토했지만, 다소 무거울 것 같아서 Celery+Redis+Websocket 조합을 시도했다.
문제는~ 이 모든 걸 처음 해본다는 것ㅋㅋ 물론 Claude와 Cursor와 함께라면 못할 건 없지만, 여전히 개발 시작 단계에서 구조 설계나 작동 원리 이해는 할 줄 알아야 한다.
🪵 시스템 구조
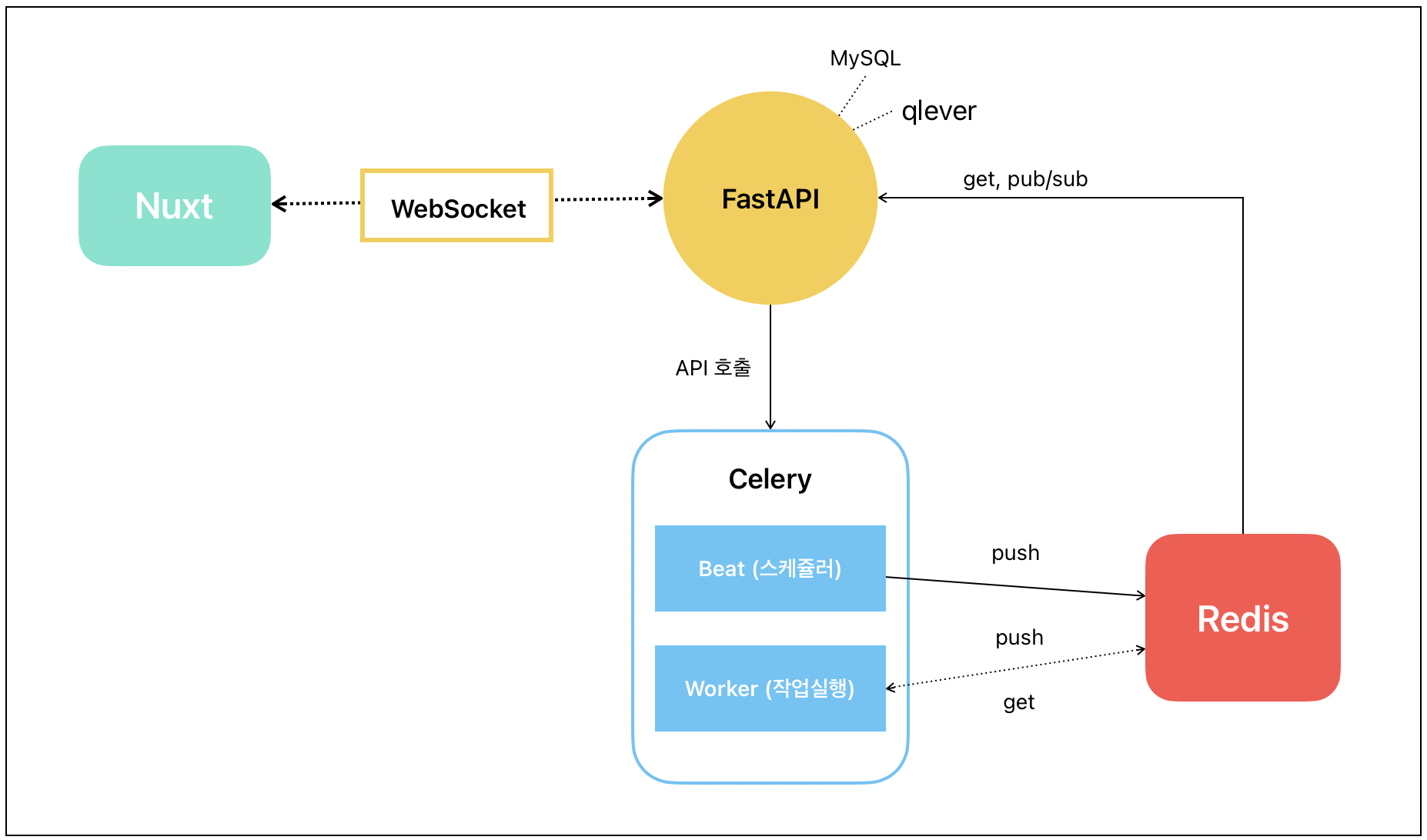
우선 각 정의한 각 시스템의 역할은 다음과 같다.
기본적으로 프론트는 Nuxt, 백엔드는 FastAPI 프레임워크를 사용하고, 실시간으로 프론트에 작업을 보내주는 역할은 FastAPI의 WebSocket이 양방향 통신으로 실시한다. 주기적으로 작업을 실행하는 스케쥴러는 Celery의 Beat가 수행하고, 실제 실행 로직은 Celery의 Worker가 한다. 실시간 로그는 Redis에 저장하는데, Redis는 간단하게 데이터베이스라고 볼 수 있지만, Key-Value나 리스트와 같은 형식으로 RAM에 저장한다는 점(인메모리 시스템)에서 로그와 같은 휘발성 데이터를 저장하는데 적합하다. 또한 저장 용량에도 제한이 있다.
이러한 구조에서 한 가지 의문은 Celery를 반드시 사용해야 하냐는 것이다. 결론은, FastAPI와 Redis만으로도 동일한 기능을 구현할 수 있지만, 현재 시스템은 비동기, 동기 작업이 모두 실행되어 분산 처리를 해야 효율적이었고, 안정적으로 시스템을 구동하는데는 Celery를 사용하는 것이 적합하다고 판단했다. 특히 모니터링과 같은 장시간 실행되는 작업에는 더욱 필요하다.
Redis의 경우에도, 지속적으로 로그를 쌓아주면 부화가 생길 것 같아 고민했지만, 주기적으로 실행할 때 Redis에 저장된 것들을 flushall(리셋) 해주면 괜찮을 것 같다고 판단했다.
🪵 파일 구조
address-management-tool/
│
├── docker-compose.yml # Docker 구성
├── .env
├── .gitignore
│
├── backend/
│ ├── requirements.txt # 필요한 패키지
│ ├── Dockerfile # backend의 dockerfile
│ ├── celery_app/
│ │ └── tasks.py # 공통 함수 선언
│ │ └── tasks_step1.py
│ │ └── tasks_step2.py
│ │ └── tasks_step3.py
│ │
│ └── fastapi_app/
│ └── main.py # fastapi 메인 실행
│ └── modules/
│ ├── module1/
│ │ └── module1_step1.py
│ │ └── module2_step2.py
│ ├── module2/
│ └── module2_step1.py
│ └── module2_step2.py
│
│
└── frontendfrontend
frontend 부분은 현재 고려사항이 아니니 자세히 다루지 않겠다. nuxt와 tailwindcss를 사용하며, npm create nuxt frontend로 프로젝트를 생성하고 npm install, npm run dev를 차례로 입력해서 localhost:3000을 열어주면된다.
backend/fastapi_app
백엔드는 fastapi를 사용하고 있고, pip install fastapi를 통해서 설치한다. 실행은 uvicorn(ASGI 웹 서버)를 통해서 실시한다(uvicorn main:app --reload).
main.py는 백엔드의 모든 API와 최종 실행을 하는 파일이다. 모든 서브 디렉토리는 추후 디플로이를 위해/api로 묶어줬고, 내주에 APIRouter를 통해 각 작업의 API를 구분했다. main.py가 너무 길어질 경우 라우터 폴더를 따로 만들어서 분리해줄 계획이다.
개발 단계에서는 상관없지만, 디플로이를 할 때 url 설정을 용이하게 하기 위해서 'localhost'나 '127.0.0.1'과 같은 주소는 .env에 API_URL과 같은 변수를 만들어서 임포트해서 사용하는 것이 편리하다.
fastapi는 기본적으로 8000포트로 열리고, 8000/docs로 접속하면 Swagger UI를 확인할 수 있다.
backend/celery_app
참고로 celery는 Window를 지원하지 않는다! gevent 등을 활용해서 우회해서 실행할 수 있는 것 같긴 하지만, 꽤나 까다로웠던 것 같다. 필자는 Mac OS에서 작업하고 있다.
가상환경을 설정하고 requirements.txt를 설치하는 부분의 설명은 생략하겠다. 사용한 주요 라이브러리의 버전들은 다음과 같다.
python-dotenv==1.1.0
argparse==1.4.0
pandas==2.0.3
polars==1.11.0
numpy==1.26.4
fastapi==0.115.5
uvicorn==0.34.1
celery==5.3.4
redis==5.0.0
websockets==11.0.3
pymysql == 1.1.1
qlever==0.5.23
...Celery를 작업하기 앞서, Redis를 설정해줘야 한다. Redis는 docker에서 실행해서 연결해주려고 한다. Redis는 6487 포트로 열린다.
docker run --name project_redis -d -p 6379:6379 redis
이렇게 도커를 실행한 뒤, 브라우저에서 6387포트로 접속해보면, 연결되지 않아서 처음에 잘못된건가 했는데 원래 이런것 같다. docker 내부에서 접속해서 redis-cli를 입력하면 Redis의 쿼리가 가능하다. keys *를 입력하면 현재 저장되어 있는 로그의 key(taskid)를 확인할 수 있고, 전체 삭제는 flushall이다. 혹은 Redis Insight라는 앱을 설치하면 UI로 보다 간편하게 확인할 수 있다.
다음은 Celery 설정이다. 작업 스케쥴링에 대한 Beat 설정은 celeryconfig.py에서 진행하고, worker는 tasks.py에서 수행한다. 다만 작업 내용이 많아서 tasks.py에는 공통 함수만 두고 같은 경로에 tasks_step1.py, tasks_step2.py와 같은 실행 파일들을 추가로 만들었다. celery worker를 실행할 때 하위 파일들을 모두 설정해줘야 하며, 이 설정은 __init__.py에서 실시한다.
from celery import Celery
# Celery 앱 생성
app = Celery('celery_app')
# 설정 모듈 로드
app.config_from_object('celery_app.celeryconfig')
# 각 태스크 모듈을 직접 임포트
from . import tasks
from . import tasks_step1
from . import tasks_step2
from . import tasks_step3실행은 backend 폴더에서 celery -A celery_app worker --loglevel=info로 하면 된다. -A celery_app는 init파일에서 설정한 Celery 앱을 실행한다는 의미이고, 여러개의 worker를 한 번에 실행해준다. 마지막에 loglevel은 출력 하는 레벨을 info로 설정해줬는데, debug, error, warning 등과 같은 설정을 해줄 수도 있다.
🪵 로직
비동기
Celery는 분산 비동기 작업 큐 시스템이기 때문에 기본적으로 비동기 작업을 실시한다. 해당 시스템의 경우, 4개의 개별 실행 스크립트를 동기로 실행하는데, 이때 각 스크립트 내부의 실행은 동기적으로 실행해야 했다.
for script in scripts:
task_result = run_script.delay(script) 예를 들어, 4개의 스크립트(.py)가 있을 때, for문을 통해서 위와 같이 실행하면, 하나의 테스크가 끝날 때 까지 기다렸다가 실행되는게 아니라 한번에 실행이 된다는 의미이다. 이때 delay()는 개별 스크립트가 동시에 시작하고, 각각 끝나면 완료로 즉시 반환한다. 총 소요 시간은 가장 오래 걸리는 스크립트의 실행 시간과 동일하다.
시간축: 0분----1분----2분----3분----4분----5분
워커1: [====script1 실행 중==============] (5분)
워커2: [===script2 실행 중===] (3분)
워커3: [==script3==] (2분)
워커4: [=====script4 실행 중======] (4분)
결과: 5분 후 모든 작업 완료반면, run_script 함수 내부에서는 적용한 내용들이 동기, 즉 순차적으로 실행되게 된다. 즉, scripts가 4개가 있을 때 for 문으로 run_script를 실행하면 script1의 단계(step1~step3), script1(step1~step3), script3(step1~step3), script4(step1~step3)가 병렬적으로 수행되는 것이다.
def run_script():
print('step1')
print('step2')
print('step3')이러한 방식은 각 스크립트 작업이 독립적으로 동시에 실행되어도 문제 없을 때 적합한 방식이다.
동기
Celery Worker를 사용함에도 동기로 작업을 수행해야 하는 경우가 발생한다. 이 경우 수동으로 동기 작업을 하게 만들거나 Chain을 사용하는 방법이 있다.
우선 순차적으로 스크립트 파일이 실행되도록 하는 방법은 단순히 개별 스크립트를 순서대로 실행한다는 의미이다. 이 작업은 available_scripts에서 정의한 n개의 작업을 각 작업이 끝나면 그 다음 작업이 시작하도록 한다.
for i in available_scripts:
script_function = i['function']
script_result = script_function()Chain을 활용하는 경우, 각각의 작업을 chain으로 묶어준다. si는 이전 실행의 결과를 다음 실행에 넘겨주지 않고, s는 넘겨주는 방식이다. 이때 script_step1등은 개별 함수이다.
from celery import chain
job = chain(
script_step1.si(month), # 1번 완료 후
script_step2.si(month), # 2번 시작
script_step3.si(month), # 2번 완료 후 3번 시작
)이러한 동기 실행은 서로 의존성이 있는 작업을 수행할 때 적합한 방법이다.
celery와 fastapi, Nuxt 통신
celery_app에서 구현한 tasks.py와 하위 파일들(tasks_step1.py 등)은 모두 개별 워커로 실행된다. 워커가 실행되기 위한 API는 main.py 혹은 router 파일에서 정의한다. 이때 실시간으로 작업 상황을 프론트에서 보여주기 위해서는 작업 단위 별로 redis에 저장한 task id를 조회하는 API로 추가로 구현해야 한다. 즉, redis에 저장(push)하는 부분의 구현은 celery_app 폴더 하위의 tasks.py 외에 개별 워커 파일에 두고, 저장된 기록을 가져오는(get) 부분은 fastapi_app의 main.py 혹은 router 파일에서 API로 구현되는 것이다.
이후 구현한 조회 API를 통해 실시간으로 redis에 저장된 로그를 front로 가져오는 부분은 WebSocket이 담당한다. redis에 실시간으로 저장되고 있는 로그를 API는 실시간 조회를 하고, 이를 WebSocket이 실시간으로 프론트엔드에서 보여준다고 이해하면 된다.
여기까지 하면 실시간 로그를 기록할 순 있는데, 문제는 웹 브라우저를 refresh한 경우, WebSocket 연결이 끊기면서 실시간으로 받아온 로그 기록들이 날아간다는 것이다. 따라서 refresh를 해줘도 로그가 지속적으로 기록되게 하기 위해서 모든 기록이 저장되는 또 하나의 API를 만들어줬다. 이 API에는 실시간 로그가 작업별로 redis에 저장되고(저장되는 형식은 직접 설정) frontend에서는 이 저장된 값을 WebSocket으로 받아오는 것이기 때문에 refresh를 해도 다시 WebSocket이 똑같은 값을 받아올 수 있어서 그대로 로그가 유지된다.
정리하면, step1 작업을 구현하기 위해서 celery_app/tasks_step1.py를 만들고, 이 워커 실행은 fastapi_app/main.py에서 '/api/step1/run' API를 통해서 진행한다. 이때 실시간 로그는 '/api/step1/status/{task_id}'를 통해서 가져오고, 최종적으로 전체 로그 기록은 '/api/step1/latest-status'를 통해서 수행되는 것이다.
후! 복잡하지만 여기까지 구현은 할 수 있었다.
🪵 미구현 작업
만약 이 시스템에서 step1과 같은 작업이 n개가 있다면, 위에서 만들어준 API를 그대로 n개를 만들어줘야 한다. 처음에는 일단 무지성으로 API를 그렇게 만들고 API에 대한 실행 함수들을 frontend에서 만들었는데, 생각해보니 이렇게 많은 API를 굳이 만들 필요가 없다는 것을 깨달았다. 물론, 개별 실행을 하기 위해서는 이 방법이 맞지만, 필자의 경우 step1부터 stepN까지가 순차적으로 연결될 실행이었기 때문에 굳이 API를 쪼개서 만들지 말고, 하나의 실행 API를 만들어서 프론트에서는 하나의 API만 받아오면 되는 것이다.
ㅎㅎ 어떻게 해야 하는지는 알겠지만, 일단 이 부분은 흐린 눈 하기로...
또한 프론트에서 실행중인 작업이 있을 때 웹 브라우저를 refresh한 경우 작업이 끊긴 것 처럼 보이는 것을 해결해야 한다. 이 문제는 위에서 언급한 '하나의 API'와 연결되는 내용인데, 만약 하나의 API로 실행했다면 refresh를 했을 때 백엔드 코드는 돌아가고 있지만, 프론트만 끊겼을 것이다. 그러나 API를 저렇게 쪼개고, 이를 순차 실행하는 부분을 프론트에서 구현했다면, refresh를 해서 WebSocket이 끊긴 그 시점 이후의 API 실행은 되지 않는다.
베스트는 하나의 API를 다시 구현하는 방법이지만... 그러기에는 너무 많은 길을 왔기 때문에 현재 상태에서 상태만 redis에 기록하는 API를 다시 생성하고자 했고, 아직 테스트 중이다.
.
.
.
아직 도커라이징도 안했고... 자잘한 에러들을 수정해야 함...
.
.
.
🧐😤🤯🫠🙃
