
올 상반기에 혼자 RAG를 공부하면서 끙끙 진행한 프로젝트이다. 특정 도메인의 pdf, csv 등 데이터를 수집, 전처리하고 VectorDB(주로 ChromaDB를 사용)에 chunk 별로 저장한 뒤, input과 유사도를 계산해서 retrieve 한 값을 넣어서 Output을 만드는 RAG의 기본 개념을 적용한 챗봇이다. 이 과정에서 정말 다양한 시행착오를 했고, 질리도록 휴리스틱한 RAG를 말 그대로 한땀 한땀 빚었다 😂. 지금까지 블로그 글들을 쭉 읽다 보면 그 과정들을 얼추 짐작할 수 있을 것...
(자세한 내용은 공유할 수 없지만, 공부히면서 기록한 테스트 버전이 33번까지 있다ㅋㅋㅋ 여기에 개발은 별개...)
이 글은 챗봇을 구현하는 과정을 필자 기준으로 크게 3단계로 나눈다면 두 번째 정도의 내용이 된다. 어떤 방식으로 LangGraph를 사용했고, Chainlit은 어떻게 사용하는 건지 간단하게 소개해보겠다.
- ipynb 파일로 langgraph 구조 만들어서 테스트
- streamlit > gradio > chainlit 기반 간단 데모 제작
- Flask, Nuxt 기반 최종 챗봇 개발
langgraph 기반의 구조적인 부분은 이때만 해도 agent 개념을 완벽히 적용해서 만든 건 아니고, 코드도 최적화하지 않아서 수정할 부분이 많다. 조만간 업그레이드 시켜서 공유하도록 하겠다.
Special Thanks to...
대부분의 RAG 입문자들이 그럴테지만, 진행하면서 Teddynote님의 유튜브와 위키독스를 정말 많이 참고했다.
Chainlit 설치
Chainlit은 Python 기반으로 채팅 구조의 어플리케이션 개발을 지원하는 도구로, 굉장히 쉽고 간단하게 심지어 UI도 예쁘게 만들 수 있다. 공식 문서도 친절한 편이라 참고해서 사용하면 된다.
pip install chainlit설치는 간단하고, 기본적으로 아래와 같이 app.py를 구성한 뒤 chainlit run app.py -w를 실행하면 localhost:8000이 열린다. -w은 코드를 수정했을 때 auto reloading되도록 하는 파라미터이다.
import chainlit as cl
@cl.on_message
async def main(message: cl.Message):
# Your custom logic goes here...
# Send a response back to the user
await cl.Message(
content=f"Received: {message.content}",
).send()
채팅내용은 왼쪽에 log가 남고, 이 log를 아이디별로 트래킹하는 용도로 LiteralAI를 붙여서 쓰는 것 같다. 로그인 부분과 로그 기록 부분에서 꽤나 애먹었는데, thumbs up/down 부분에 대한 기록이 계속 말썽이었고 다소 복잡한 설정이 있었던 것으로 기억한다. 일단 tracking 부분은 langsmith로 진행하고 있기도 하고, chainlit으로 서비스 배포할 예정은 아니라서 넘어갔다.
데이터 전처리, VectorDB 구축
이 부분은 간단하게 설명하고 넘어가겠다. pdf, csv 등은 이 당시에 PdfPlumber를 사용해서 읽거나 대부분 txt 파일로 옮겨서 사용했고, 이 과정에서 table 정보는 유실된 경우도 있다. 전처리 부분은 최대한 가볍게 가기 위해서 간단하게 진행했는데, 나중에 돌아보면 데이터 전처리가 최종 RAG 성능에 미치는 영향이 굉장히 큰 것 같다는 생각을 했다. 최근 Upstage의 Document Parser를 테스트 중인데, 앞으로는 그 툴을 사용해서 전처리를 진행할 것 같다.
VectorDB를 구축하는 과정도 이전에 ChromaDB, FAISS와 관련된 글을 작성했으니 넘어가겠다. 이 데모에서는 ChromaDB를 사용했고, Embedding model은 OpenAI의 text-embedding-3-large를 사용했다. 임베딩 모델도 성능에 큰 영향을 미치는데, text-embedding-3-small, text-embedding-ada-002를 비롯해서 llama, gemma, 한국어 기반 fine-tuning 오픈소스 모델등 다양하게 사용해봤지만, 결국 가장 차원이 크고 비싼 모델의 성능이 우수했다.
Langgraph 구조 설계
from IPython.display import Image, display
try:
display(
Image(app.get_graph(xray=True).draw_mermaid_png())
)
except:
pass이건 사실 모든 구조를 다 만들고, 위 코드를 실행했을 때 얻을 수 있는 mermaid 형식의 그래프 이미지이다.
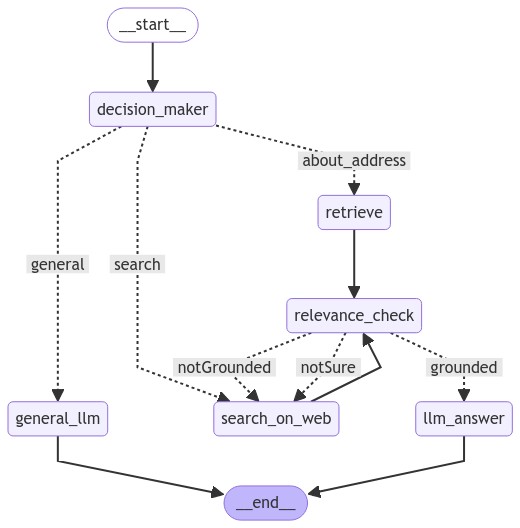
복잡한 것 같지만, 하나씩 보면 간단하다. Input이 들어갔을 때, 어떤 동작을 할 지 decision_maker로 routing 시키고, RAG가 필요 없는 일반 질문인 경우 바로 LLM에 넣어서 답변을 도출, RAG가 필요한 경우라면 VectorDB에서 필요한 chunk를 가져오고 relevance check를 한 뒤, 필요하다면 웹 서치를, 필요하지 않다면 LLM 기반의 답변을 생성해서 Output으로 출력하는 형태이다.
이 구조를 구현하는 코드 중 중요한 부분만 하나씩 살펴보겠다.
GraphState 설정
class GraphState(TypedDict):
question: str # 질문
q_type: str # 질문의 유형
context: str # 문서의 검색 결과
answer: str # llm이 생성한 답변
relevance: str # 답변의 문서에 대한 관련성 (groundness check)그래프의 상태를 지정하고 저장하는 부분이다. LangGraph는 node(실제 실행되는 함수라고 생각할 수 있음)와 edge(연결부)로 구성되는데, 각 노드를 연결할 때 서로 주고 받을 상태값들을 GraphState에서 지정해주는 것이다. 현재 str 타입만 사용했지만, 형태에 따라서 타입을 다르게 지정해주면 된다.
주의할 점은, 각 노드를 거칠 때 업데이트 되어야 하는 State를 반드시 입력해줘야 한다는 것이다. 아래 예시를 통해서 이 의미를 살펴보겠다.
decision maker
def decision_maker(state: GraphState) -> GraphState:
chat = ChatOpenAI(model="gpt-4o", api_key=openai_api_key)
prompt = PromptTemplate.from_template(
"""
너는 question의 종류를 분류하는 모델이야. 질문의 종류는 ['**관련 질문', '검색필요 질문', '일반 질문'] 3가지 종류로 구분 돼. 이때 question뿐만 아니라 chat_history까지 고려해줘.
1. **관련 질문: ~~ 등과 같은 내용의 질문일 경우 '주소관련 질문'으로 분류해 줘.
2. 검색필요 질문: ~~와 관련되지 않은 질문 중, 너가 스스로 대답할 수 없는 질문을 의미해. 예를 들어, '오늘의 날씨', '오늘의 주가' 등과 같이 최신 정보를 반영해야 하는 경우와 '~검색해줘'라는 말이 포함될 때 '검색필요 질문'으로 분류해 줘.
3. 일반 질문: ~~와 관련되지 않은 질문 중, 너가 스스로 대답할 수 있는 질문을 의미해. 예를 들어, '영어를 한국어로 번역해줘', '대한민국의 수도는?'과 같이 일반 상식적인 질문인 경우 '일반 질문'으로 분류해 줘.
질문이 들어왔을 때, 위 3개의 종류 중에 가장 해당되는 분류를 선택하고 반드시 ['**관련 질문', '검색필요 질문', '일반 질문'] 중 하나로 선택해. 띄어쓰기나 대소문자 구분 등 다른 형식이나 추가적인 설명 없이 오직 하나의 라벨만 출력해줘.
#Previous Chat History:
{chat_history}
#Question:
{question}
#Answer:"""
)
chain = prompt | chat | StrOutputParser()
rag_with_history = RunnableWithMessageHistory(
chain,
get_session_history, # 세션 기록을 가져오는 함수
input_messages_key="question", # 사용자의 질문이 템플릿 변수에 들어갈 key
history_messages_key="chat_history", # 기록 메시지의 키
)
input_data = {
'question': state["question"],
'chat_history': itemgetter("chat_history"),
'context':''
}
response = rag_with_history.invoke(input_data, config={"configurable": {"session_id": "rag123"}})
return GraphState(
q_type=response,
question=state["question"],
)
def decision_making(state: GraphState) -> GraphState:
q_type_strip = state["q_type"].strip()
if q_type_strip == "**관련 질문":
return "about_address"
elif q_type_strip == "검색필요 질문":
return "search"
elif q_type_strip == "일반 질문":
return "general"조건부로 분기하는 함수이다. relevance checker의 경우 이런 방식을 쓰길래(참고) 코드를 이런식으로 짰는데, retrieval 하는 부분도 하나의 tool이라고 생각하면 @tool을 바인딩해서 호출하는 방식으로도 접근할 수 있는거 같다(참고). 어느 방식이 일반적인지, 더 효율적인지는 아직 공부가 더 필요하다.
특히 output의 형식이 다르면 graph 중간에 에러가 발생하기 때문에 이 부분에서는 반드시 outputparser를 chain에 추가해서 사용해줘야 할 것 같다. Prompt engineering 만으로는(작성을 잘 못했기 때문일 수도 있음) 아무래도 불안하고 실제로도 가끔 이 부분에서 에러가 발생했다.
return 부분에서 q_type과 question은 앞서 GraphState를 업데이트 하는 부분이다. 이후 업데이트 된 State를 기준으로 decision_making 함수에서 조건에 맞게 분기되도록 적용한다.
Groundness Checker
chat = ChatOpenAI(model="gpt-4o", api_key=openai_api_key)
def relevance_message(context, question):
messages = [
SystemMessage(content="""
너는 Query와 Document를 비교해서 ['grounded', 'notGrounded', 'notSure'] 셋 중 하나의 라벨을 출력하는 모델이야.
'grounded': Compare the Query and the Document. If the Document includes content that can be used to generate an answer to the Query, output the label 'grounded'.
'notGrounded': Compare the Query and the Document. If the Document does not include content that can be used to generate an answer to the Query, or if the information is insufficient, output the label ‘notGrounded’.
'notSure': Compare the Query and the Document. If you cannot determine whether the Document includes content that can be used to generate an answer to the Query, output the label .notSure'.
너의 출력은 반드시 'grounded', 'notGrounded', 'notSure' 중 하나여야 해. 띄어쓰기나 대소문자 구분 등 다른 형식이나 추가적인 설명 없이 오직 하나의 라벨만 출력해줘.
"""),
HumanMessage(content=f"""
[Document]
{context}
[Query]
{question}
"""),
]
return messages
def relevance_check(state: GraphState) -> GraphState:
messages = relevance_message(state["context"], state["question"])
response = chat.invoke(messages)
return GraphState(
relevance=response.content,
context=state["context"],
answer=state["answer"],
question=state["question"],
)
def is_relevant(state: GraphState) -> GraphState:
relevance_strip = state["relevance"].strip()
if relevance_strip == "grounded":
return "grounded"
elif relevance_strip == "notGrounded":
return "notGrounded"
elif relevance_strip == "notSure":
return "notSure"
VectorDB에서 가져온 참고할 chunk가 실제로 질문의 답변을 생성하는데 적절한지 검토하기 위한 checker이다. 이 검증 부분은 (1) 질문과 Chunk 비교 (2) 생성한 답변과 Chunk 비교 이렇게 두 부분에서 진행할 수 있을거 같은데, 잘못된 정보로 생성한 답변은 당연히 Chunk를 기반으로 하니 오류를 잡기 더 어려울 것 같다는 생각을 해서 (1)번 방식을 택했다.
Decision Maker와 동일하게 GraphState를 업데이트 하고 조건별로 분기해준다.
최종 그래프 Compile
workflow = StateGraph(GraphState)
# 노드들을 정의합니다.
workflow.add_node("decision_maker", decision_maker) # 질문의 종류를 분류하는 노드 추가
workflow.add_node("retrieve", retrieve_document) # 답변을 검색해오는 노드 추가
workflow.add_node("general_llm", general_llm) # 일반 질문에 대한 답변을 생성하는 노드 추가
workflow.add_node("relevance_check", relevance_check) # 답변의 문서에 대한 관련성 체크 노드 추가
workflow.add_node("search_on_web", search_on_web) # 웹 검색 노드 추가
workflow.add_node("llm_answer", llm_answer) # 답변을 생성하는 노드 추가
workflow.add_edge("retrieve", "relevance_check") # 검색 -> 답변
workflow.add_edge("search_on_web", "relevance_check") # 웹 검색 -> 답변
# 조건부 엣지를 추가합니다.
workflow.add_conditional_edges(
"decision_maker",
decision_making,
{
"about_address": "retrieve",
"search": "search_on_web", #
"general": "general_llm",
},
)
# 조건부 엣지를 추가합니다.
workflow.add_conditional_edges(
"relevance_check", # 관련성 체크 노드에서 나온 결과를 is_relevant 함수에 전달
is_relevant,
{
"grounded": "llm_answer", # 관련성이 있으면 종료
"notGrounded": "search_on_web", # 관련성이 없으면 다시 질문을 작성
"notSure": "search_on_web", # 관련성 체크 결과가 모호하다면 다시 질문을 작성
},
)
workflow.add_edge("llm_answer", END) # 답변 -> 종료
workflow.add_edge("general_llm", END) # 답변 -> 종료
# 시작점 설정
workflow.set_entry_point("decision_maker")
# 기록을 위한 메모리 저장소 설정
memory = MemorySaver()
# 그래프 컴파일
app = workflow.compile(checkpointer=memory)최종적으로 생성한 함수들을 노드로 설정하고, 각 노드를 edge로 연결하는 그래프를 구조를 짜는 과정이다. workflow.add_node 부분에서는 각 노드들을 정의하며 ("노드명":함수명) 구조를 갖는다. workflow.add_edge는 노드들을 연결해주는데, 이때 조건에 따라서 분기되는 경우 workflow.add_conditional_edges로 연결한다. relevance_check 부분이 위에서 Groundness Checker 부분에 해당하는데, 도출된 답변에 따라서 다른 노드와 연결해준다.
마지막으로 END, START 노드를 설정하고 workflow를 컴파일 해주면 끝이다. 위에서부터 Memory, History와 관련된 코드들이 중간중간 있었고 이에 대한 설명은 생략했는데, 이 부분은 모델이 multi-turn 응답, 즉 앞 질문과 응답을 기억하고 다음 답변을 할 수 있도록 하기 위해서 추가한 부분이었다. 다만, 이때 이 구현이 뭔가 clear하지 않아서(기능은 제대로 동작했지만, 사용 token이 계속 쌓이고 중간에 비워주지 않았음) 다시 검토해볼 필요가 있다.
(추가) LangSmith
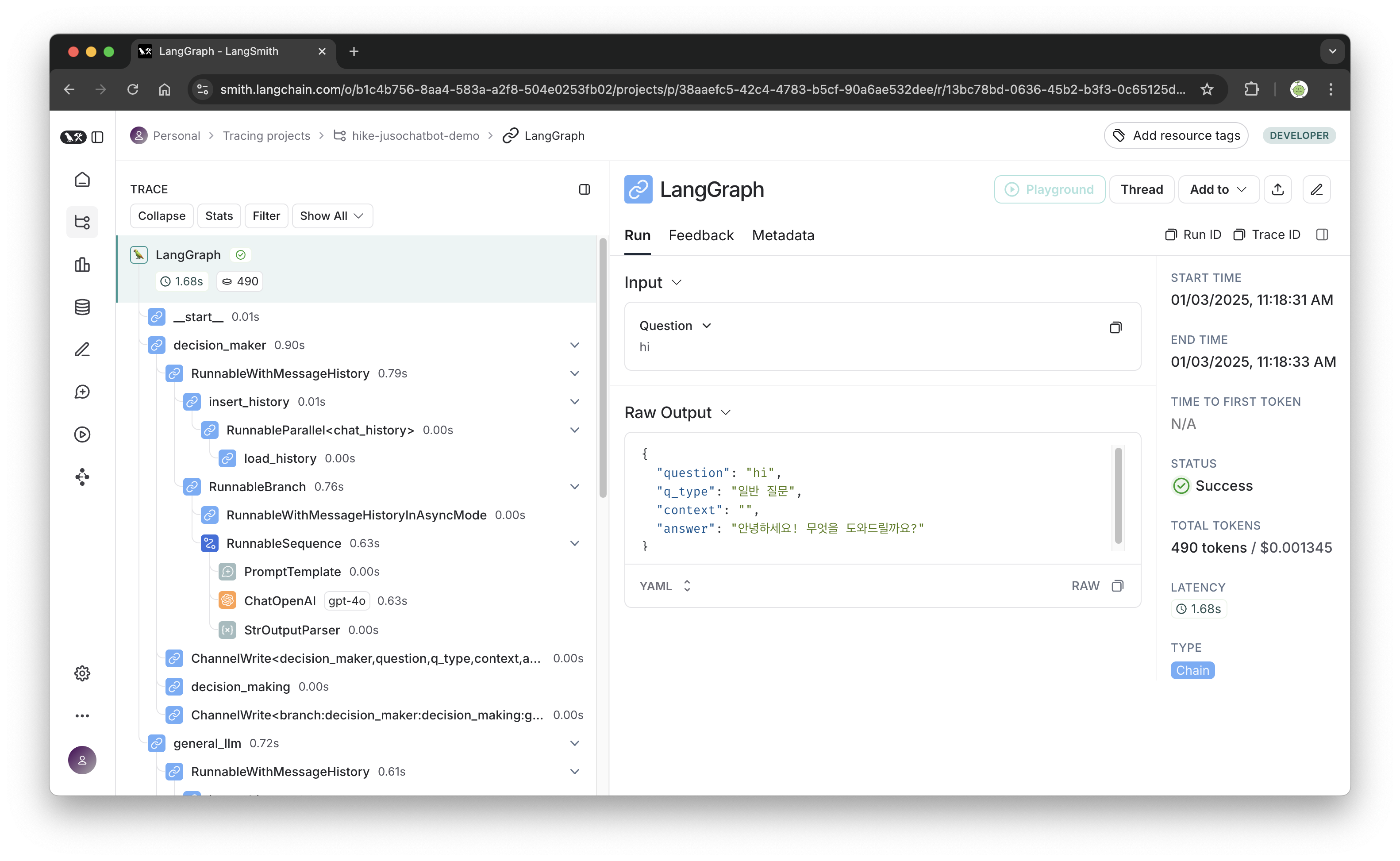
Langsmith는 LangChain에서 개발한 Tracking 툴로, langchain을 사용한다면 매우 유용한 도구이다.
이 데모에서도 Langsmith를 연결해줬기 때문에 챗봇이 돌아가는 동안 들어오고 나가는 모든 응답들을 확인할 수 있다. 또한 해당 응답이 도출되기까지의 프로세스도 기록되기 때문에 디버깅에도 용이하고 지불할 금액도 대략적으로 예측할 수 있다.
Chainlit 사용
if __name__ == "__main__":
from chainlit.cli import run_chainlit
run_chainlit(__file__)
@cl.on_message
async def run_convo(message: cl.Message):
async with cl.Step(name="langgraph", type="llm") as step:
step.input = message.content
user_id = str(uuid.uuid4())
config = RunnableConfig(
recursion_limit=20, configurable={"thread_id": user_id, "user_id": user_id}
)
inputs = GraphState(
question=message.content
)
try:
# answer = app.invoke(inputs, config=config)
# print(answer)
# answer_text = answer['answer']
with collect_runs() as cb:
# config = RunnableConfig(
# recursion_limit=20, configurable={"thread_id": "HIKE-JUSO-CHATBOT"},
# )
answer = app.stream(inputs, config=config)
final_answer = list(answer)
run_id = cb.traced_runs[0].id
print(run_id)
if 'general_llm' in final_answer[-1]:
answer_text = final_answer[-1]['general_llm']['answer']
elif 'llm_answer' in final_answer[-1]:
answer_text = final_answer[-1]['llm_answer']['answer']
step.output = final_answer
except GraphRecursionError as e:
print(f"Recursion limit reached: {e}")
answer_text = "죄송합니다. 해당 질문에 대해서는 답변할 수 없습니다."
except Exception as e:
print(f"An error occurred: {e}")
answer_text = "죄송합니다. 처리 중 오류가 발생했습니다."
await cl.Message(content=answer_text).send()
실행파일에서 Chainlit을 실행하기 위한 코드는 위와 같다. @cl.on_message 태그를 달아주고 함수화해서 실행하면 되고, inputs 변수에 GraphState의 question을 설정한다. try-except을 통해서 답변할 수 없는 경우(검색을 20번 retry했는데도 grodness check에서 관련성이 없다고 판단되면 except으로 넘어가도록 설정했다) 따로 처리할 수 있도록 설정해줬다.
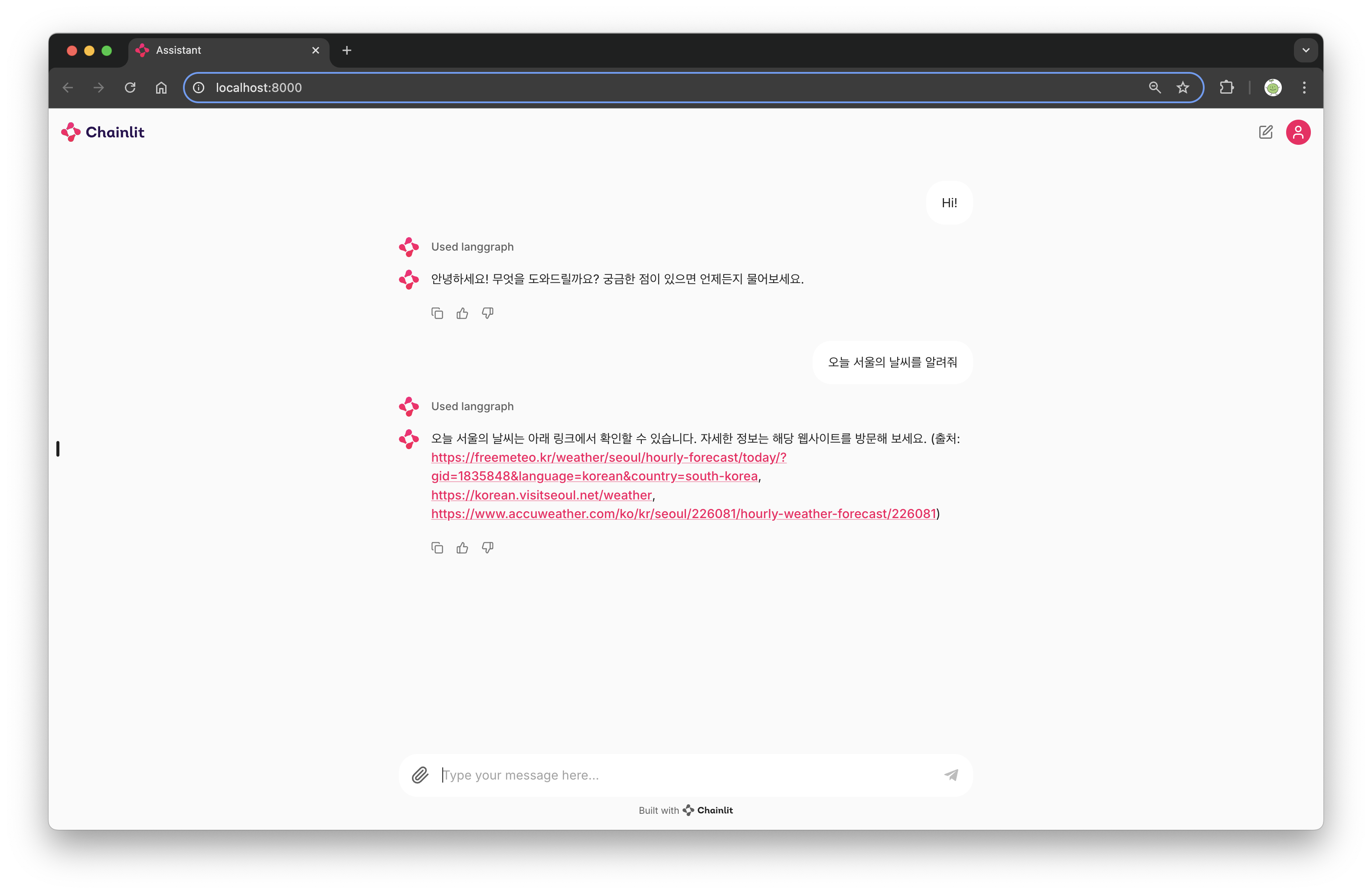
최종적으로 챗봇을 사용해보면 이렇게 잘 실행된다. 검색이 필요한 질문의 경우 연결해준 검색 프로세스를 통해서 검색하고 출처를 명시한다. VectorDB에서 가져와서 답변하는 것도 잘 된다.
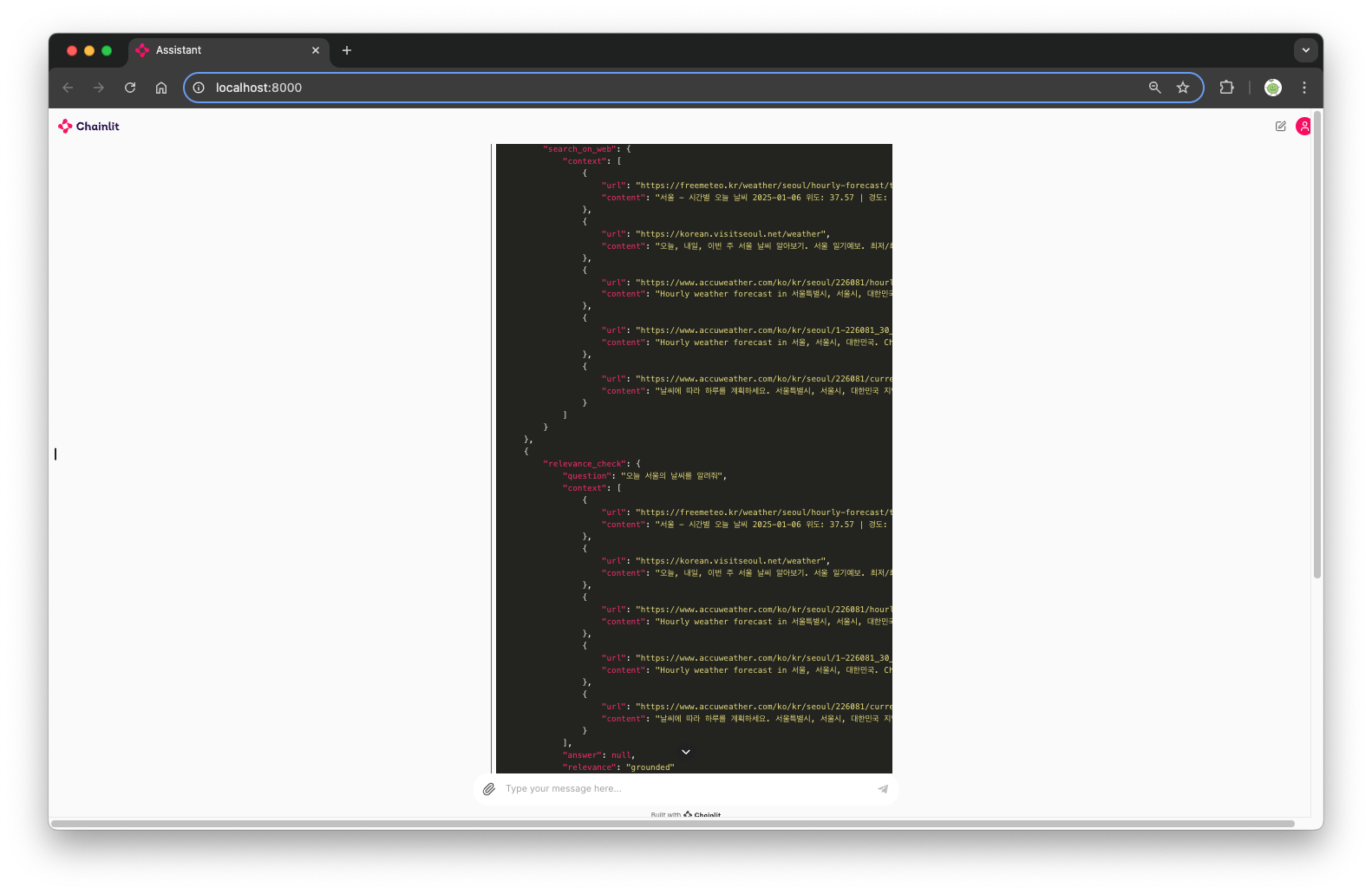
LangSmith를 통해서 자세하게 확인할 수 있지만, Chinlit에서는 각 응답의 프로세스를 바로 확인할 수 있도록 제공하기도 한다. LangGraph를 사용할 때 각 프로세스의 시작과 끝을 호출할 때 마다 인식해서 각 스텝이 보이도록 하는 방법도 있는거 같은데, 다음에 그 부분을 추가해봐야겠다고 생각했다.
이렇게 모델 개발 부터 Chainlit을 활용한 간단한 데모 구현까지 마쳤다. 모델 개발이 8할, 데모 개발이 2할 정도로 시간과 노력을 들인 것 같다. 여전히 사용해보면 모델이 불안정하고 답변의 정확도가 그렇게 높다고 볼 순 없지만... 차차 개선해나가는 걸로!
이 데모 코드는 깃헙 private에 있어서 공개하진 않았는데, 지금 공개할 수 있을 정도의 코드를 다듬고 있다. 작업이 끝나면 모든 코드를 공유하도록 하겠다.
