Ollama는 LLM을 로컬환경에서 쉽게 돌릴 수 있도록 하는 프레임워크이다. 이 자체가 LLM은 아니고 ChatGPT와 같은 LLM기반의 chatting AI를 GPT 뿐만 아니라 llama, mistral 등과 같은 다른 오픈소스 모델을 붙여서 사용할 수 있다는 의미이다. 로컬로 다운받은 모델을 돌리는 것이기 때문에 민감한 데이터를 넣어도 문제 없다는 점도 장점이지만, 무엇보다 로컬에서 LLM을 어느정도로 돌릴 수 있는지 궁금했기 때문에 바로 테스트를 진행해보았다.
실행환경은 M2 macOS ram16Gb 이다.
.
.
.
1. Ollama 설치하기
mac의 경우 brew install ollama를 실행한 뒤 ollama run mistral만 하면 된다는데, 왜인지 자꾸 아래와 같은 에러가 발생한다.
Error: could not connect to ollama app, is it running?
할 수 없이 ollama.com에서 다운받아서 진행했고, 정상적으로 설치되었다. (설치 후 상단 바에 귀여운 라마가 생긴다!ㅋㅋ) 설치할 수 있는 모델 리스트는 홈페이지에서 공개하고 있다. 필자는 mistral과 llama2를 테스트 해보았다.
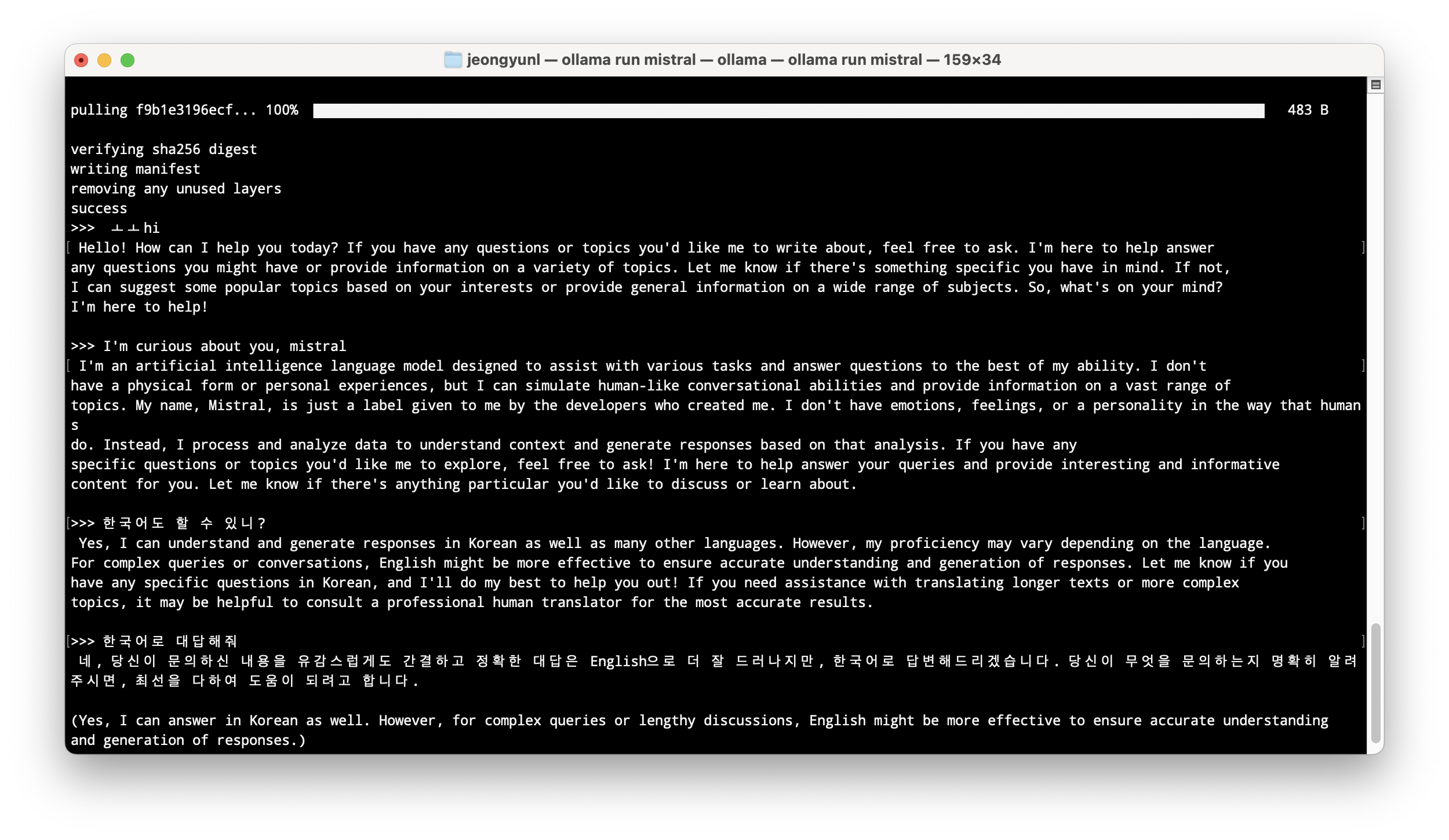
mistral을 설치하는 데에 대략 15분 정도 걸렸고 설치 후 바로 terminal 환경에서 채팅을 진행할 수 있다. 한국어로 답변을 할 순 있지만, 영어가 더 정확하다는 답변을 한다.
ollama run gemma "Summarize this file: $(cat /Users/home/Downloads/test.md)"이런식으로 사용하면 문서를 요약해주기도 한다. markdown, pdf파일을 테스트 해봤는데 markdown은 내용을 요약해주고 pdf는 metadata정보를 주었다. (몇 페이지인지, 어떤 언어로 사용되었는지 등등)
2. Open WebUI 설치하기
terminal에서 계속 사용해도 되지만, ChatGPT와 같이 웹 상의 UI가 더 사용하기 편리하다. Ollama를 웹 인터페이스로 구현하기 위한 툴이 바로 Open WebUI (구 Ollama WebUI)이다. 공식 깃헙에서 Docker에 설치해서 사용하라는 설명이 되어 있는데, 깃헙 파일을 클론해서 설치해도 되는 것 같다. Docker 설정이 귀찮아서 로컬에 다운 받아서 실행해보았다.
git clone https://github.com/open-webui/open-webui.git클론한 폴더를 열어보면.env.example파일이 있을 텐데 이를 그대로 복사해서 같은 위치(root)에 .env파일을 만든다.
이후 다음 순서 대로 설치하면 된다.
npm install
npm run build cd ./backend
pip install -r requirements.txt -U
sh start.sh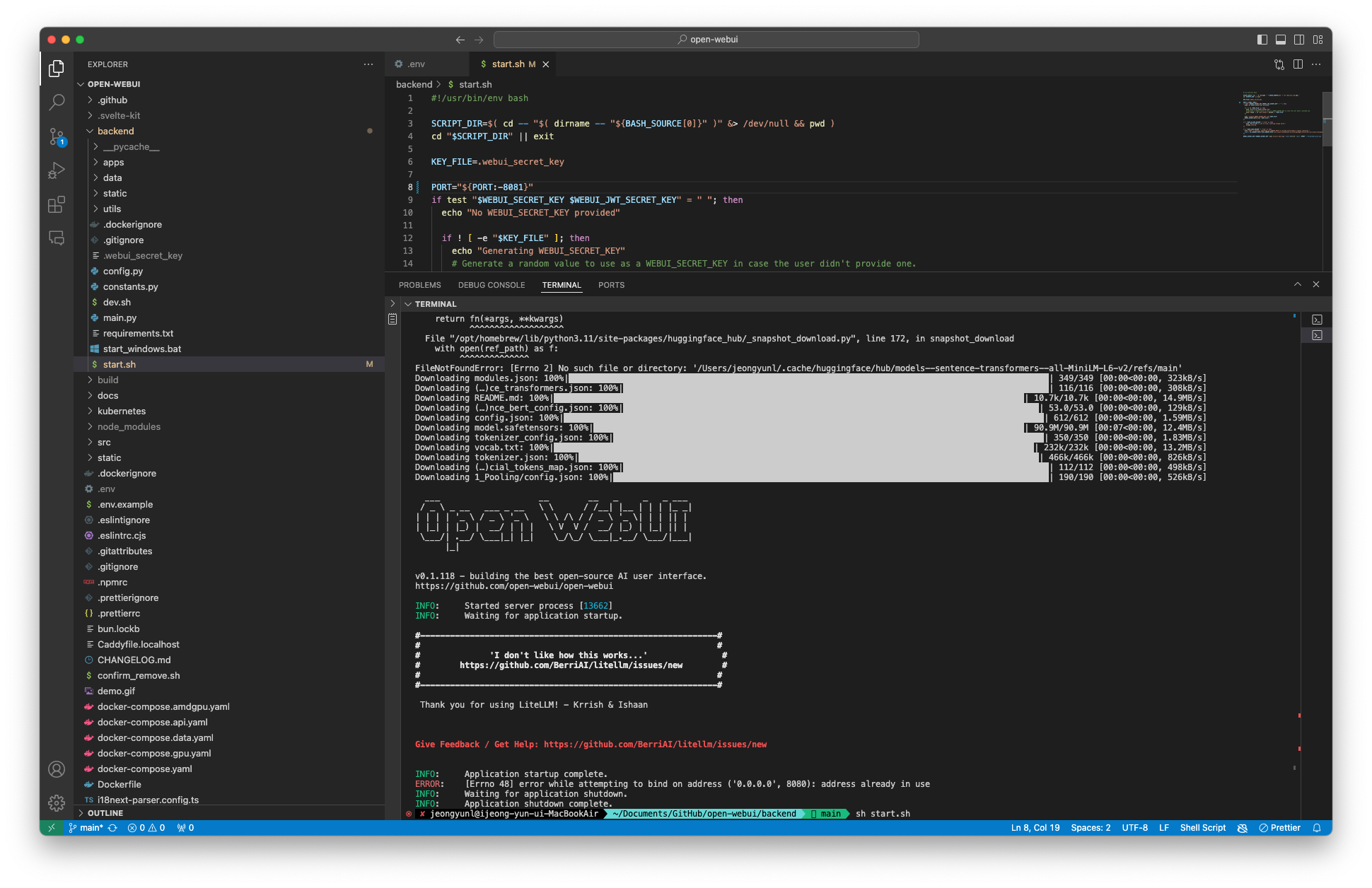
default port는 8080이다. 나는 이미 8080포트를 사용하고 있어서 위와 같은 에러가 발생했고 start.sh파일에서 8080을 8081로 수정해주었다.
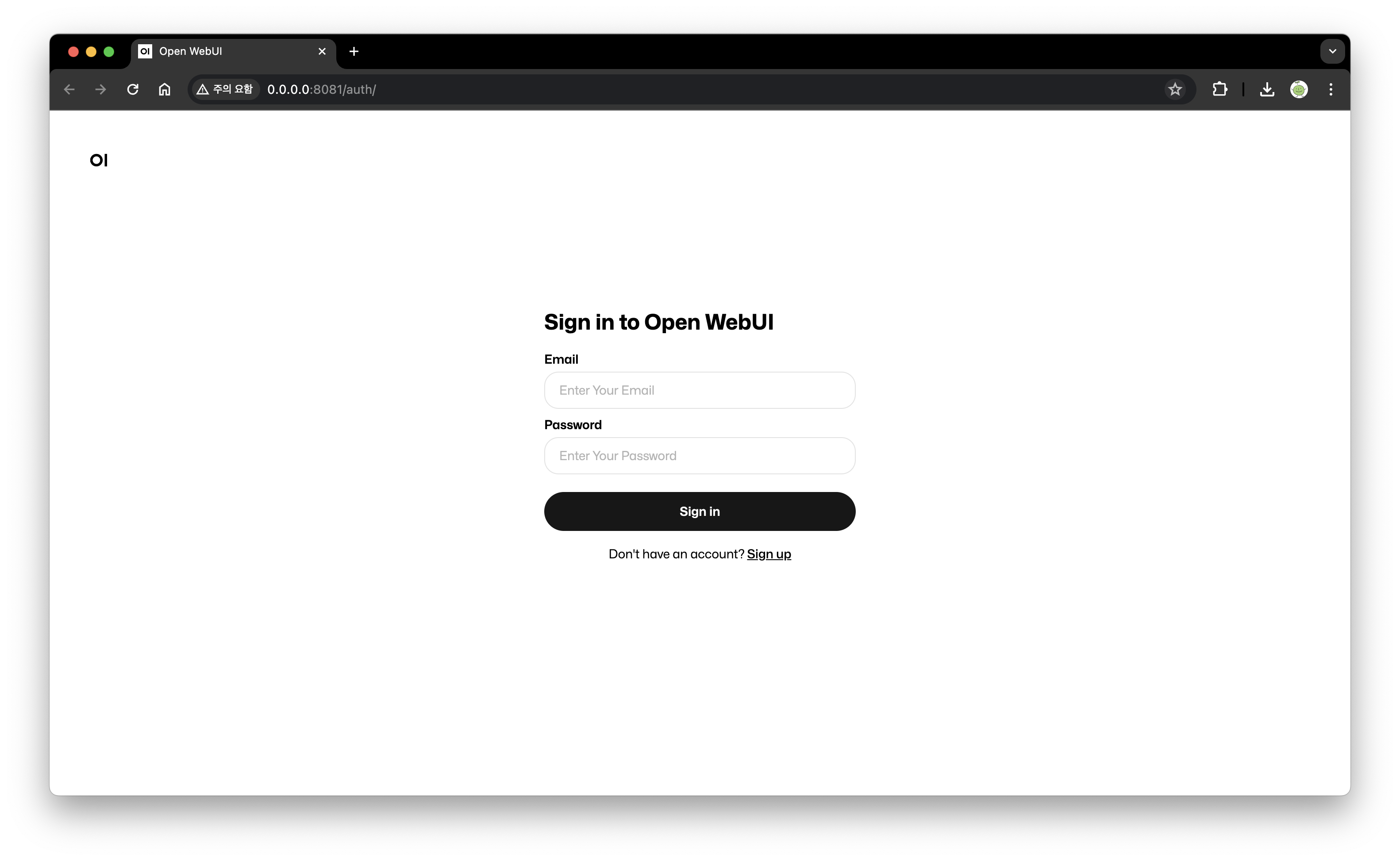
그리고 localhost:8080으로 들어가면 위와 같이 잘 작동하는 것을 확인할 수 있다!
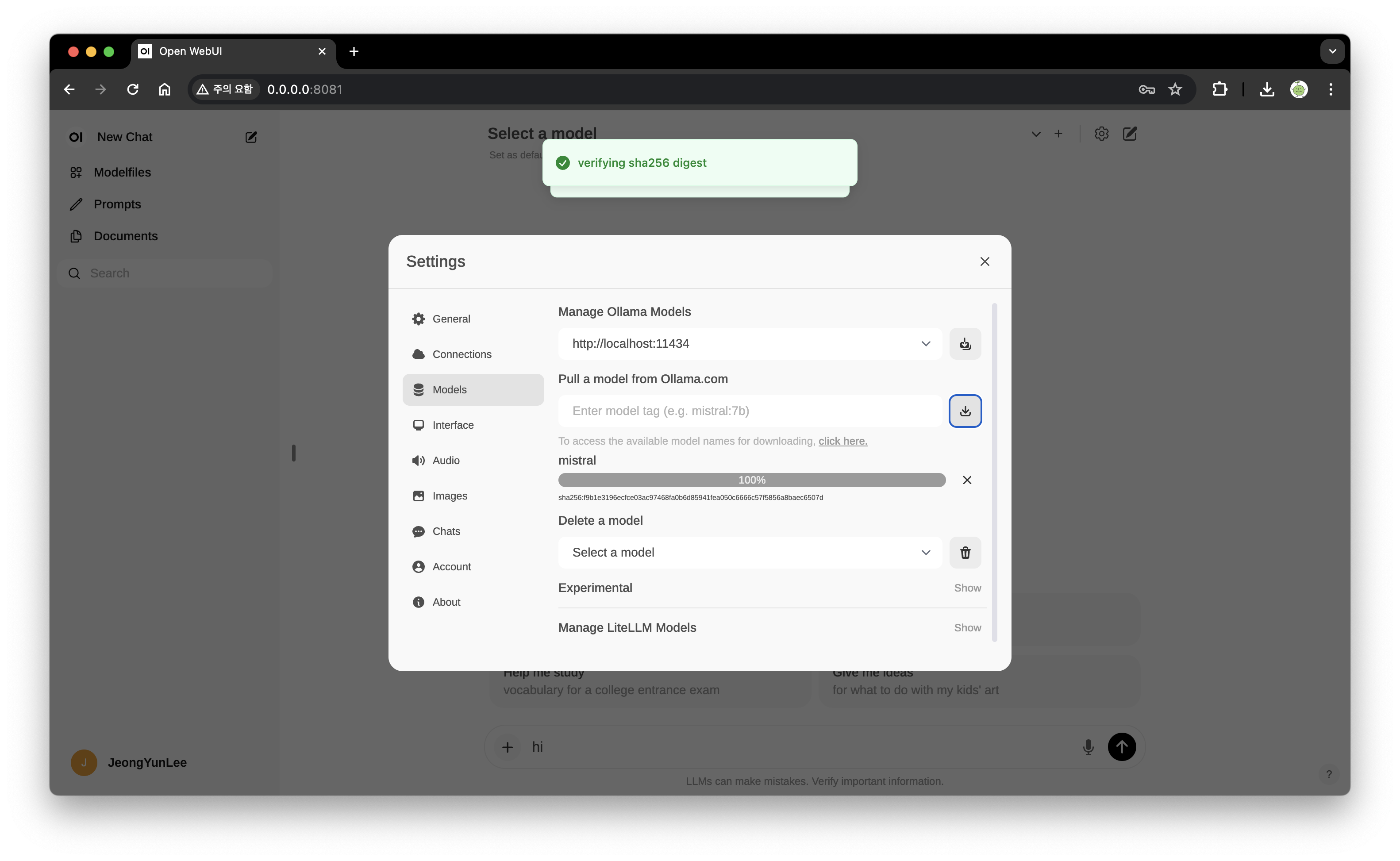
로그인을 한 뒤, 설정 부분에서 Model에 mistral을 입력하면 'succesfully~'하면서 모델 적용이 된다. 그리고 다시 채팅 화면 상단에 'Select a model' 부분에서 mistral을 선택한 뒤 채팅을 진행하면 된다.
.
.
.
여기까지가 Ollama를 활용해서 LLM을 로컬에서 실행하는 간단한 실습을 진행한 내용이다. 생각보다 간단해서 놀랐고, 생각보다 성능도 나쁘지 않았다.
+) 가벼운 궁금증
테스트를 다 한 뒤 한 가지 의문은, 채팅 베이스의 LLM만 실행할 수 있는 것인가?였다. ChatGPT의 등장 이후 LLM이 뭔가 prompt 기반으로만 작동하는 것 같은 착각이 들기 시작했는데, 더이상 보다 원초적으로(정확히 표현을 못하겠다) 임베딩 값을 가지고 테스트를 진행하진 않는건지? chat model도 결국 fine-tuning을 한 모델이라고 생각했는데, base model에 대한 흔적은 잘 찾아볼 수 없어서 든 의문이었다.
참고자료
