
LG AI Research는 작년 12월에 EXAONE 3.5를 공개하고, 약 이틀전에는 추론 모델인 EXAONE Deep을 공개했다. 특히 Deep 모델의 경우, 사이즈가 딥시크-R1의 5% 정도로 경량 모델에 해당함에도 수학 분야 등에서 성능을 뛰어났다고 한다.
OpenAI나 DeepSeek와 같은 글로벌 foundation 모델과 경쟁할 수 있는 '한국 자체 모델'이라는 점과 함께 '오픈소스'로 공개한다는 점이 인상적이었다.
| Model Size | EXAONE-3.5, EXAONE Deep |
|---|---|
| 2.4B | 저사양 GPU에서도 학습과 추론이 가능한 온 디바이스용 초경량 모델 Training Token: 6.5T |
| 7.8B | 범용적 활용 가능한 경량 모델 Training Token: 9T |
| 32B | Frontier AI 급의 고성능 모델 Training Token: 6.5T |
공개한 모델은 3.5와 Deep 모두 활용 목적에 따라서 사용할 수 있는 세 가지 사이즈로 구성된다. Input context length는 동일하게 32,768 token이다. 3.5와 Deep 모델 각각의 training 방식을 Technical Report와 research blog의 설명을 기반으로 정리하면 다음과 같다.
📌 EXAONE-3.5
Pre-Training
Pre-Training 단계에서 데이터 구성과 모델 교육에 대한 접근 방식을 두 단계로 구성된다.
- general domain의 성능을 높이기 위해 다양한 소스의 대형 코퍼스 데이터를 기반으로 진행하는 1차 사전 훈련
- 보다 강화하고 싶은 domain specific 데이터를 기반의 2차 사전 훈련
Context length를 늘리기 위해선 'long-context FT'를 진행했다고 하는데, 최초의 Pre-Training 단계에서 학습한 내용을 기억하게 하기 위해서 재생 기반(replay-based) 기법을 사용한다고 한다. 즉, 2단계의 학습을 진행할 때, 1단계의 학습 데이터도 일부 넣어주는 것이다.

또한 벤치마크 데이터셋에 있는 데이터가 학습 과정에 포함되는 Contamination 현상을 방지하기 위해서 최대한 제거를 해줬다고 한다. 위와 같이 텍스트들을 정규화한 다음 window size를 50으로 하고 stride는 1로 해서 무작위 샘플링한 데이터에서 유사한 값들이 있는 경우 삭제를 하는 방식이다.
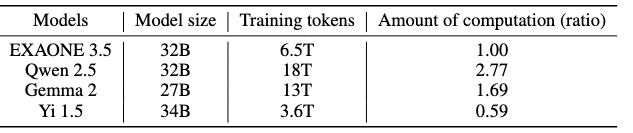
Table3에서는 학습에 사용된 비용은 비슷한 사이즈의 Qwen이나 Gemma 보다 현저히 낮다는 것을 비교하고 있는데, 그 이유에 대해서는 명확하게 설명하지 않는다. 그냥 효율적인 학습을 했지만 고성능이다... 정도.
Post-Training
Post-Training 작업으로는 SFT와 Preference Optimization을 진행했다.
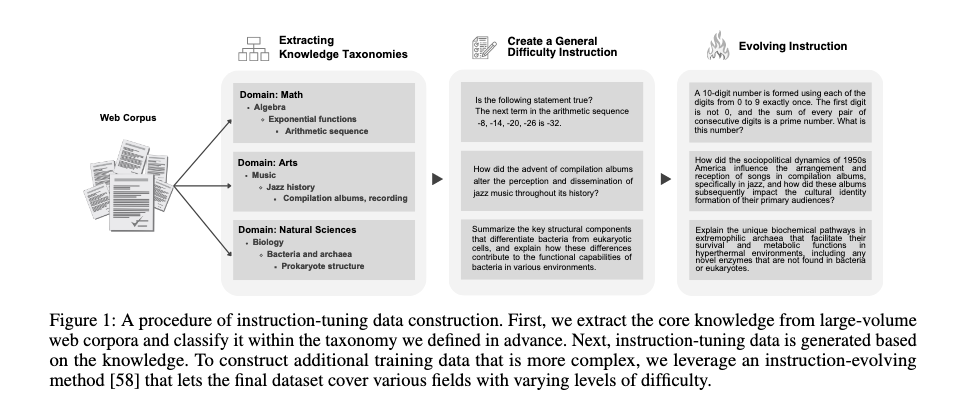
우선 SFT(Supervised Fine-Tuning)는 QA 형식의 dataset을 기반으로 instruct model을 만들기 위한 작업이다. 학습 데이터셋은 Web corpora에서 8M의 핵심 지식을 taxanomic system을 통해서 추출했다고 한다. 이후 추출된 지식들을 기반으로 Instruct dataset을 생성하고, 복잡성 수준을 높여서 다양한 어려운 지시를 생성했다.
SFT 이후, Preference Optimization을 진행하는데, 이때는 data synthetic과 사전에 수집된 데이터를 사용한다고 한다. 구체적으로 데이터를 생성하는 방법은 프롬프트 X에 대하여 여러 모델로부터 N개의 응답을 받으며 reward model을 기반으로 점수가 높은 응답부터 나쁜 응답까지 순위를 메긴다. 이후 추가적인 reward model을 사용해서 두 모델의 순위의 일치도를 계산하고 threshold 미만의 데이터를 필터링한다.
📌 EXAONE-Deep
Training
3.5 모델에서 Reasoning 성능을 높이기 위해서 SFT의 경우 1.6의 인스턴스를 사용하고 DPO의 preference data는 20K의 인스턴스를, 그리고 10K의 온라인 Reinforcement Learning 인스턴스를 사용했다고 한다. 데이터셋은 확장된 CoT(Chain-of-Thought)과정을 통해 모델이 추론을 수행하도록 설계되었다고 한다.
이때의 instance는 정확히 어떤 걸 의미할까? Gemini에 물어보니 '학습에 사용되는 개별적인 데이터 항목'을 의미한다고 한다.

SFT를 위한 Reasoning 데이터셋의 예시는 위와 같다. <thought> 태그 내에서 추론을 수행하도록 유도되고 있고, 자체적인 검사와 수정을 통해서 단계적인 논리적 진행을 수행한다. 추론 후에 생성된 최종 답변은 명확하고 간결한 방식으로 핵심 통찰력을 요약하도록 설계되었다. 또한 DPO에는 SimPER를 학습 알고리즘으로 사용하고, 온라인 Reinforcement Learning에는 자체 설계된 GRPO의 변형을 사용한다고 한다.
현재의 LLM 환경에서의 오픈소스의 의미가 개발의 모든 과정과 비법을 오픈하겠다는 의미는 아닌 만큼, 이에 대한 세세한 내용까지 모두 TR에서 설명하고 있진 않았다. 그럼에도 사용한 GPU와 computational cost 등을 공개하고 있다는 점은 인상적이었다. 한편, 대체적으로 평범한 학습 과정을 거친 것 같은데, 어떻게 효율을 높인 것인지에 대한 명확한 이해는 되지 않았지만, 데이터셋을 구축하는 과정에 공을 많이 들였다는 느낌을 받았다.
Evaluation 결과로는 성능이 굉장히 뛰어난 것 같은데, 체감되는 실제 성능도 테스트 해봐야 될 것 같다.
